步骤 2:替换 NPU Driver 后编译 Ubuntu 并刷机 根据瑞芯微 GitHub rkllm 仓库对的《RKLLM SDK User Guide》要求[5],特别说明: RKLLM 版本是 1.2.1: RKLLM 所需要的 NPU 内核版本较高,用户在板端使用 RKLLM Runtime 进行模型推理前,首先需要确认板端的 NPU 内核是否为 v0.9.8 版本。 # cat /sys/kernel/debug/rknpu/version
RKNPU driver: v0.9.7
BuildRoot 是默认系统,不太方便,所以刷了米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0 里的 Ubuntu 镜像后(烧录部分遵循米尔提供的文档 MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0 第 5 章:烧录镜像。发现 NPU Driver 版本是 0.9.7,不符合 RKLLM 用户文档的要求。
此时,只能将版本为 0.9.8 的 NPU Driver 代码替换到米尔给的 Ubuntu 源码里,然后重新编译 Ubuntu 镜像并重新刷机。对于刷机过程,RKLLM 的文档提到: 若用户所使用的为非官方固件,需要对内核进行更新。其中,RKNPU 驱动包支持两个主要内核版本:kernel-5.10 和 kernel-6.1: 米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0 对应的虽然不是最推荐的 kernel-6.1.84,但是也是 6.1。即下图: 米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0 里 04-Sources 的源码包
解压后 Ubuntu 源码目录
# 进入源码解压后得到的一个 MYD-LR3576 目录
# 第一次编译执行以下命令选择配置文件
./build.sh lunch
# Which would you like? [7]
# 这里选择 7,rockchip_rk3576_myd_lr3576_defconfig
# 紧接着分别编译 u-boot、kernel 和 modules
./build.sh u-boot
./build.sh kernel
./build.sh module
# 编译成功再执行下面命令,编译 Ubuntu 文件系统,并打包最终 Ubuntu 系统镜像
./build.sh ubuntu
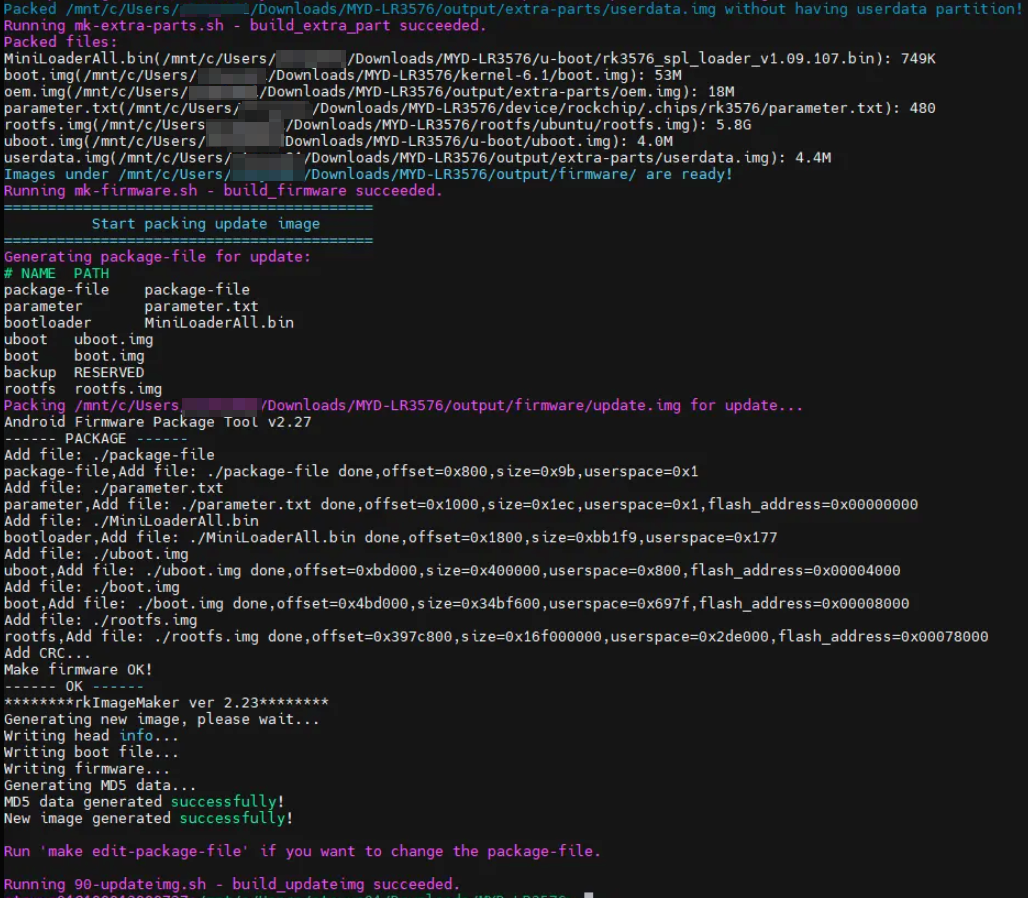
./build.sh updateimg
# RK3576 为了用户可以更便捷的烧录,单独创建了目录储存编译出来的镜像在 output/update/Image 下
分别对 u-boot、kernel、module 三部分编译,最后编译成功如下图所示: Ubuntu 镜像编译成功
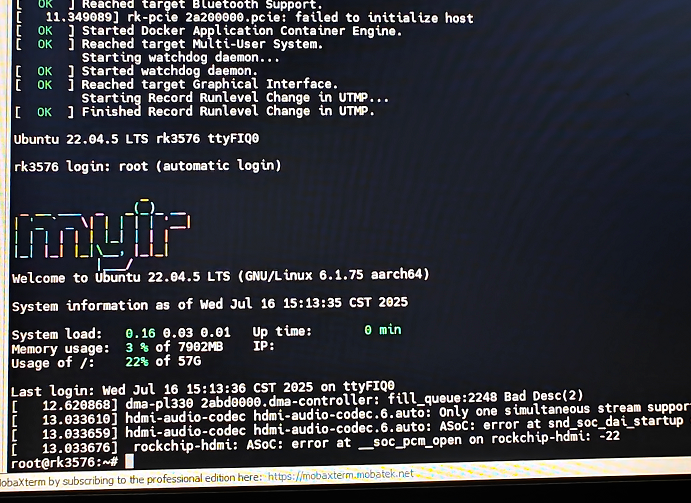
烧录结束后,连接笔记本,可以看到如下截图,进入系统。 刷机完后链接开发板,可以看到 MYIR 漂亮的字体 Logo
使用命令下图中的命令查看 NPU Driver 版本,符合预期! 自己基于米尔提供的 Ubuntu 源码更改 NPU Driver 为 0.9.8 后的 NPU Driver版本,符合预期
那么,下面我们就可以正式开始使用 RKLLM ! 三、多模态案例:支持图像和文本交互 前面我们已经介绍了瑞芯微大模型 SDK RKLLM。本节将会演示实际操作流程,目标是对 Qwen2-VL-3B 多模态模型进行部署,其中视觉 + 投影组件通过 rknn-toolkit2 导出为 RKNN 模型,LLM 组件通过 rkllm-toolkit 导出为 RKLLM 模型。 在 Qwen2-VL 这类多模态模型(支持图像和文本交互)中,“视觉 + 投影”(Vision + Projector)是模型处理图像输入的核心组件,作用是将图像信息转换为模型可理解的特征: 视觉组件(Vision):主要负责处理图像输入,完成“图像解析”的功能。它会对输入的图像(如后续示例中的demo.jpg)进行特征提取,将像素级的图像信息(比如颜色、形状、物体轮廓等)转换为高维的“图像特征向量”(一种数值化的表示)。这一步类似人类“看”到图像并提取关键信息的过程。 投影组件(Projector):多模态模型需要同时处理图像和文本,而图像特征与文本特征的原始格式(如维度、语义空间)可能不同,无法直接融合。投影组件的作用就是“桥梁”:它会将视觉组件输出的“图像特征向量”进行转换(投影),映射到与文本特征相同的语义空间中,让图像特征和文本特征能够被模型的后续模块(如语言模型 LLM)统一理解和处理。
简单来说,“视觉 + 投影”组件的整体作用是:把图像“翻译”成模型能看懂的“语言”(特征),并确保这种“语言”能和文本的“语言”互通,为后续的多模态交互(如图文问答)打下基础。在部署时,这两个组件被打包成 RKNN 模型,适合在 Rockchip 的 NPU(神经网络处理器)上高效运行,专门处理图像相关的计算。
下面,跟着 RKLLM SDK 里多模态模型例子[7],只给出必要的操作步骤。 步骤 1:环境准备 安装必要的 SDK 依赖库。 pip install rknn-toolkit2 -i https://mirrors.aliyun.com/pypi/simple
pip install torchvision==0.19.0
pip install transformers
pip install accelerate
步骤 2:模型的获取、验证与格式转换 本步骤产物为 rknn 和 rkllm 格式的模型文件。 操作如下,同官方指导[8]。: 注:我们这一步直接使用瑞芯微提供的 rkllm_model_zoo 里的模型[11]。 步骤 3:修改代码并交叉编译可执行文件并上传到板子上 本步骤产物为如下目录和文件。 rknn-llm-release-v1.2.1/examples/Qwen2-VL_Demo/deploy/install/demo_Linux_aarch64▶ tree
.
├── demo
├── demo.jpg
├── imgenc
├── lib
│ ├── librkllmrt.so
│ └── librknnrt.so
└── llm
1 directory, 6 files
操作如下: 修改源码中的EMBED_SIZE:适配模型 注:我们用的模型是 Qwen2-VL-3B,需要在src/main.cpp和src/img_encoder.cpp中修改EMBED_SIZE为2048。 不同的 Qwen2-VL 模型(2B 和 7B)需要在src/main.cpp和src/img_encoder.cpp中指定IMAGE_HEIGHT、IMAGE_WIDTH及EMBED_SIZE,核心原因是这些参数与模型的固有结构设计和输入处理逻辑强绑定,直接影响特征提取的正确性和数据传递的一致性。 代码中img_vec(图像特征向量)的尺寸依赖EMBED_SIZE计算(如IMAGE_TOKEN_NUM * EMBED_SIZE)。若EMBED_SIZE与模型实际输出维度不匹配,会因为特征向量内存分配错误(数组大小与实际特征维度不符)或者后续 LLM 组件无法正确解析图像特征,导致推理失败如 Segmentation Fault[12]: 交叉编译 假设当前位于 rknn-llm/examples/Qwen2-VL_Demo/ 目录下,执行 cd deploy
./build-linux.sh
编译成功,如下所示: 
成功交叉编译多模态代码
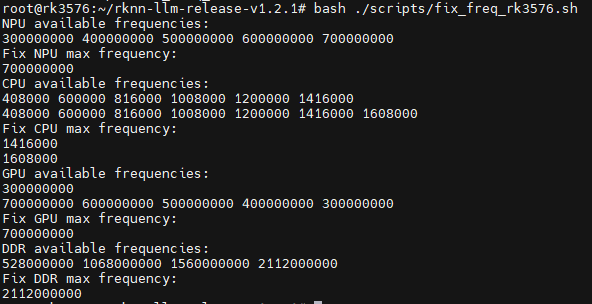
步骤 4:上传文件到开发板 将上一步编译后的install目录,以及前面转换模型得到的 rknn 和 rkllm 格式的模型文件通过 U 盘等方式上传到 RK3576 上。 性能测试 Tips 瑞芯微在 scripts 目录中提供了一些脚本和参数设置: 使用 fix_freq_rk3576.sh 锁定 CPU、GPU、NPU 等设备频率,让测试结果的性能更加稳定。 在设备上执行 export RKLLM_LOG_LEVEL=1,以记录模型推理性能和内存使用情况。 使用 eval_perf_watch_cpu.sh 可脚本测量 CPU 利用率。 使用 eval_perf_watch_npu.sh 可脚本测量 NPU 利用率。
fix_freq_rk3576.sh 脚本会对 NPU、CPU、GPU、DDR 进行锁频
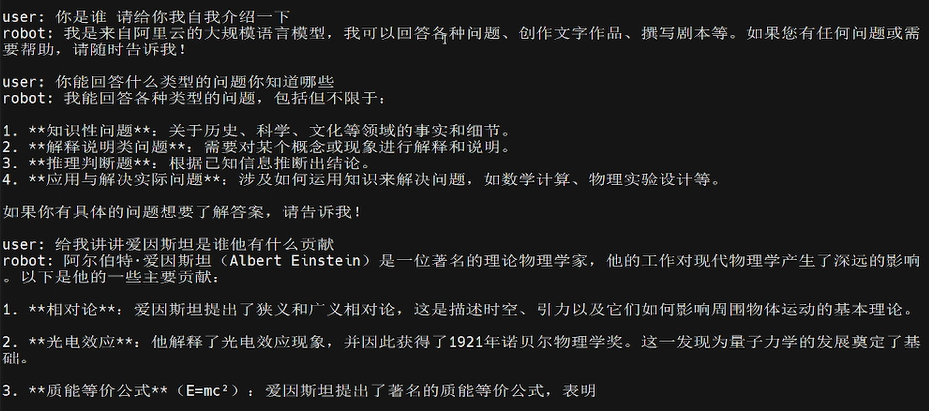
多模态效果演示 为后续验证多模态能力,先展示 RKLLM 的基础配置及纯文字交互测试场景,以下为配置参数与初始对话片段: 纯文字问答能力 因仅是纯文字对话没有图片,可以执行如下命令, # run llm(Pure Text Example)
./llm ~/rkllm-model-zoo/Qwen2.5-VL-3B-Instruct/qwen2.5-vl-3b-w4a16_level1_rk3576.rkllm 128 512
纯文字:自我介绍
[color=rgba(0, 0, 0, 0.9)]  纯文字:能回答哪些问题 纯文字:谁是爱因斯坦
纯文字执行结果
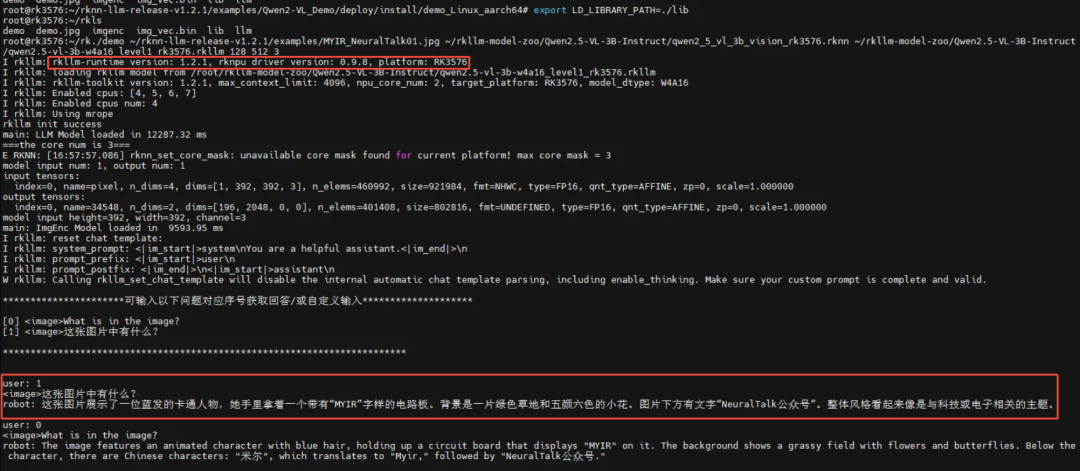
多模态问答能力 上述为图片问答的测试准备与初始提问,下文展示‘RK3576 多模态图片问答: 测评图片1:特征是可爱的二次元蓝头发女孩,手里拿着米尔 MYIR 开发板,下方文字写着:NeuralTalk 公众号
# run demo(Multimodal Example)
# 使用方式:./demo image_path encoder_model_path llm_model_path max_new_tokens max_context_len rknn_core_num
./demo demo.jpg models/qwen2-vl-vision_rk3588.rknn models/qwen2-vl-llm_rk3588.rkllm 128 512 3
./demo 最后一个参数是核数,用于推理时是否考虑多核推理,可选参数为:2(RKNN_NPU_CORE_0_1)、3(RKNN_NPU_CORE_0_1_2)、其他(RKNN_NPU_CORE_AUTO)。 测评图片1:描述图片
测评图片1:执行结果
下面我们再换一张图片试试效果!
测试图片2:图片背景是赛博风格

测试图片2:描述图片

测试图片2:多模态能力问答
测试图片3
下图展示了测试图片3运行中的一些性能指标,包括模型初始化时间、不同阶段的总时间(Prefill和Generate阶段)、Token数量、Token生成速度,以及峰值内存使用量。 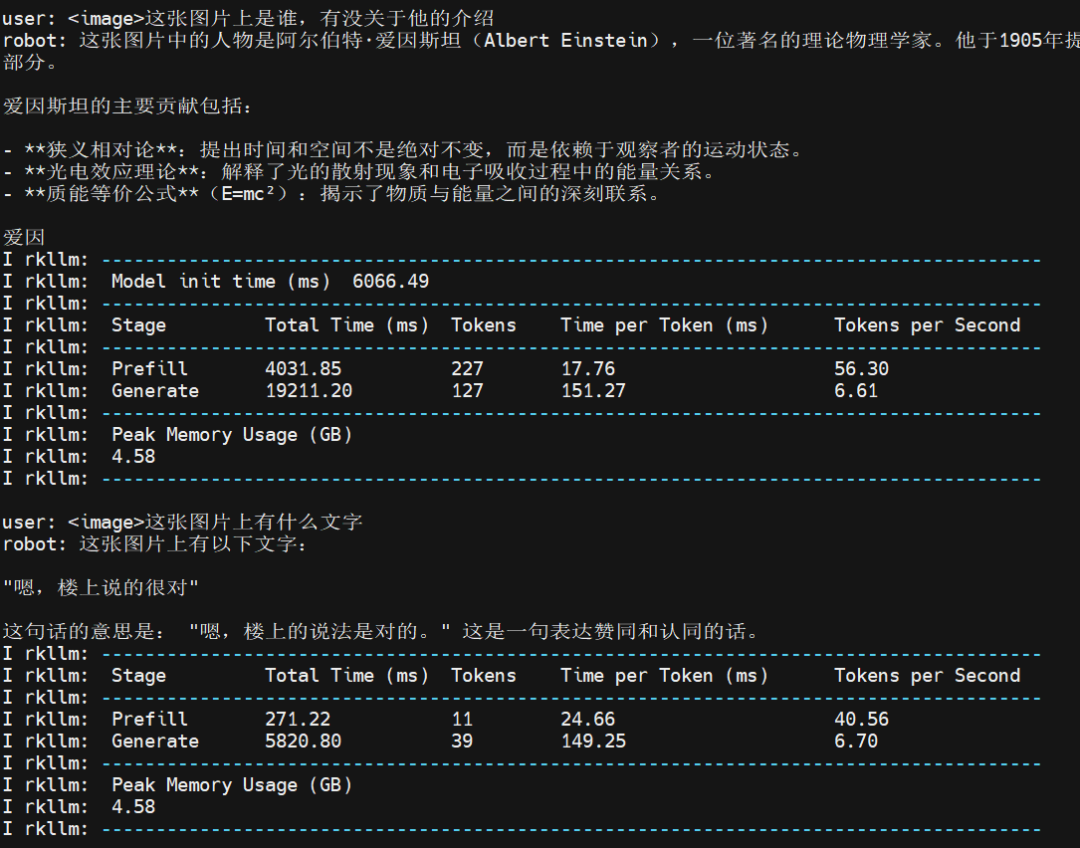
测试图片3:内存占用和耗时等
总得来说,模型第一次加载 6 秒钟,首次出词语也有体感上的慢,但是这之后速度就很稳定,而且很快,纯文字的速度更快一些。 结论 本文围绕瑞芯微 RK3576 开发板 NPU 对多模态 LLM 的支撑能力与性能展开测评,全面呈现其在端侧 AI 领域的价值。 端侧SLM在延迟、隐私与离线可用性上的优势显著,而 RK3576 凭借 8nm 制程、6TOPS自研NPU及动态稀疏化加速引擎,填补了旗舰与主流方案的市场空白。它针对2B-3B参数级模型专项优化,轻量化视觉任务算力利用率提升 18%,NPU功耗降低 22%,30% 的成本优势使其在多场景快速量产,中高端市场占有率环比增长 47%。 技术落地方面,RKNN 与 RKLLM SDK形成互补生态,RKNN 保障模型兼容性,RKLLM 通过量化优化、多模态支持等降低模型内存占用与推理延迟。实测中,RK3576 运行 Qwen2-VL-3B 模型时,纯文字交互 Token 生成稳定,多模态问答能精准识别图像元素,峰值内存占用 4.58GB ,在移动终端和工业场景可靠运行。 本文提供的环境准备、模型转换、代码适配等实操步骤,为开发者提供了可复现的部署方案。RK3576 在多场景展现良好兼容性与稳定性,能以低成本实现高准确率任务。 未来,RK3576“算力精准匹配场景”的设计理念或成中端AIoT核心方向,其在多维度的平衡,为端侧AI部署提供高性价比选择,助力边缘计算规模化应用。  RK3576 工作状态
参考资料 [1] MYD-LR3576-产品介绍-V1.1: https://dev.myir.cn/upload/files/product/20250211/17392600078427483.pdf [2]rknn_model_zoo: 'https://github.com/airockchip/rknn_model_zoo'
[3]airockchip/rknn-llm: 'https://github.com/airockchip/rknn-llm'
[4]米尔开发平台: 'https://dev.myir.cn/'
[5]Rockchip_RKLLM_SDK_CN_1.2.1.pdf: 'https://github.com/airockchip/rknn-llm/blob/main/doc/Rockchip_RKLLM_SDK_CN_1.2.1.pdf'
[6]rknpu-driver: 'https://github.com/airockchip/rknn-llm/tree/main/rknpu-driver'
[7]Qwen2-VL_Demo: 'https://github.com/airockchip/rknn-llm/tree/main/examples/Qwen2-VL_Demo'
[8]Qwen2-VL_Demo: 'https://github.com/airockchip/rknn-llm/tree/main/examples/Qwen2-VL_Demo'
[9]Qwen2-VL-2B-Instruct: 'https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct'
[10]rkllm_model_zoo: 'https://console.box.lenovo.com/l/l0tXb8'
[11]rkllm_model_zoo: 'https://console.box.lenovo.com/l/l0tXb8'
[12]Qwen2-VL-2B_Demo segfault RK3576 using 1.2.0 version: 'https://github.com/airockchip/rknn-llm/issues/336'
| 



 发表于 2025-8-29 17:56:14
发表于 2025-8-29 17:56:14