
дкTM1300ЩЯЪЕЯжH.26LЕФ4x4ЕуећЪ§БфЛЛ
ЗЂВМЪБМфЃК2010-12-12 22:47
ЗЂВМепЃКdesigner
|
H.26LЪЧЯТвЛДњЪгЦЕБрТыБъзМЁЃЫќЕФБрТыадГЌдНСЫЫљгаЯжДцБъзМЃЌАќРЈH.263+КЭMPEG-4ЃЈSPЃЉЁЃИУЮФЗжЮіH.26Lв§ШыЕФЖржжаТЕФБрТыЬиадЃЌзХжиНВЪі4%26;#215;4ЕуећЪ§БфЛЛЃЌВЂЬсГівЛжждкTM1300ЩЯЪЕЯжЕФПьЫйБфЛЛЫуЗЈЁЃ H.26LЪЧЯТвЛДњЪгЦЕБрТыБъзМЁЃзюГѕЃЌH.26LгЩITU-TЕФVCEGаЁзщПЊЪМзХЪжжЦЖЉЁЃ2001Фъ11дТЃЌMPEGКЭVCEGСЊКЯГЩСЂJVTаЁзщЙВЭЌВЮгыжЦЖЉH.26LЁЃвВе§вђЮЊMPEGЕФМгШыЃЌH.26LНЋБЛФЩШыMPEG-4ЕФЕкЪЎВПЗжЁЃгЩгкH.26LБъзМЛЙдкжЦЖЉЙ§ГЬжаЃЌБОЮФднЪБвдJVTЬсЙЉЕФВтЪдФЃаЭTML8ЮЊВЮПМЁЃ H.26LаХдДБрТыЕФЛљБОБрТыПђМмРрЫЦгкЕБЧАСїааЕФЪгЦЕБрТыБъзМЃЌВЩгУНсКЯБфЛЛБрТыКЭдЄВтБрТыЕФЛьКЯБрТыММЪѕЁЃЫќГіЩЋЕФадФмжївЊРДдДгкв§ШыЕФаТБрТыЬиадЃК4%26;#215;4ЕуећЪ§БфЛЛЁЂЪЙгУUVLCНјааьиБрТыЁЂ1/4ЁЋ1/8ЯёЫиОЋЖШЕФдЫааЪИСПЁЂгаЖржжПщДѓаЁНјаадЫЖЏЙРМЦЕШЕШЁЃетаЉаТЕФБрТыММЪѕДгВЛЭЌВрУцЬсИпСЫбЙЫѕадФмКЭШнДэадФмЁЃгШЦфЪЧ4%26;#215;4ЕуећЪ§БфЛЛЃЌЪЧЫљгаЪгЦЕбЙЫѕавщжаЖРвЛЮоЖўЕФЁЃ ЫфШЛH.26LБъзМЛЙдкжЦЖЉжаЃЌЕЋЪЧдкГѕВНЕФВтЪджаЃЌЫќЕФБрТыадФмГЌдНСЫЯжДцЫљгаБъзМЃЌАќРЈH.263+КЭMPEG-4ЃЈSimple profileЃЉЁЃетаЉЪдбщНсЙћБэУїЃЌдкШЁЕУЯрЭЌЕФПЭЙлЪгЦЕжЪСПЯТЃЌH.26LБШH.263+ФмЙЛНкЪЁ20%ЁЋ50%ЕФТыТЪЃЌБШMPEG-4ЃЈSPЃЉНкЪЁЖрДя50%ЕФТыТЪЁЃзїЮЊЯТвЛДњЪгЦЕБрТыБъзМЃЌH.26LеЙЪОСЫЦфОоДѓЕФЗЂеЙЧАОАЁЃ 1 H.26LЕФ4x4ЕуећЪ§БфЛЛ 1.1 БфЛЛМђНщ дкH.26LБрТыММЪѕжаЃЌ4x4ЕуећЪ§БфЛЛПЩвдПДзїЪЧDCTБфЛЛЕФећЪ§АцБОЃЌжївЊЭъГЩШЅГ§ЭМЯёЕФПеМфЯрЙиадЃЌгы4%26;#215;4ЕуDCTБфЛЛгазХЯрЭЌЕФаджЪЁЃЯШПМТЧвЛЮЌЕФећЪ§БфЛЛЃКЩшa,b,c,dЪЧ4ИіД§БфЛЛЕФЕуЃЌAЃЌBЃЌCЃЌDЪЧЖдгІЕФ4ИіБфЛЛЯЕЪ§ЃЌдђПЩвдгУвдЯТЙЋЪНБэЪОa,b,c,dЕуЕФе§БфЛЛЃК A=13a+13b+13c+13d B=17a+7b-7c-17d C=13a-13b-13c+13d D=7a-17b+17c-7d ЗДБфЛЛЙЋЪНШчЯТЃК a"=13A+17B+13C+7D b"=13A+7B-13C-17D c"=13A-7B-13C+17D d"=13A-17B+13C-7D ЦфжаaКЭa"ЕФЙиЯЕЪЧa"=676aЁЃвВОЭЪЧЫЕЃЌОЙ§ЗДБфЛЛКѓЃЌЛЙашвЊНјааЙщвЛЛЏВйзїЃЌЪЙЕУе§БфЛЛКЭБфЛЛГпЖШвЛжТЁЃ ЭЌбљЖўЮЌЕФ4x4ећЪ§БфЛЛЕФБфЛЛКЫЪЧПЩЗжРыЕФЁЃЗжРыЕФБфЛЛНЋМЦЫуИДдгЖШДгOЃЈN4ЃЉНЕЕНOЃЈN3ЃЉЁЃ 1.2 гы8x8ЕуDCTБфЛЛЕФБШНЯ гыДЋЭГЕФDCTБфЛЛЯрБШЃЌH.26LВЩгУ4x4ЕуећЪ§БфЛЛЮЊЪгЦЕБрТыДјРДСЫвдЯТгХЕуЃК ЂйгажњгкМѕЩйПщАпКЭЛЗаЮАпЃЌЬсИпСЫЭМЯёжЪСПЁЃгЩгкЖдБфЛЛЯЕЪ§НјааСЫСПЛЏЃЌдьГЩСЫИпЦЕЯЕЪ§ЖЊЪЇЃЌЫљвдЛжИДЕФЭМЯёжаЛсгаПщАрКЭЛЗаЮАрЁЃдкH.26LжаЃЌВЩгУСЫИќаЁЕФ4x4ЕуБфЛЛЃЌПЩвдгааЇвжжЦПщАпКЭЛЗаЮАпЁЃ ЂкећЪ§БфЛЛМѕаЁСЫЛ§РлЮѓВюЁЃДЋЭГЕФЛ§РлЮѓВюРДздСНИіЗНУцЃКе§БфЛЛКЭЗДБфЛЛВЛЦЅХфдьГЩЕФЮѓгыСПЛЏдьГЩЕФЮѓВюЁЃЮЊСЫДяЕНбЙЫѕЕФФПЕФЃЌЕкЖўжжЮѓВюВЛПЩБмУтЁЃЕЋЪЧЃЌгЩгкH.26LВЩгУСЫОЋШЗЕФећЪ§БфЛЛЃЌЫљвде§БфЛЛКЭЗДБфЛЛВЛЛсВњЩњЮѓВюЃЌетбљгааЇЕиМѕЩйСЫЛ§РлЮѓВюЁЃ ЂлдЫЫуЫйЖШПьЁЃвђЮЊH.26LВЩгУЕФБфЛЛЙЋЪНЪЧвЛИіМђЕЅЕФећЪ§ЗНГЬЃЌвВОЭЪЧЫЕМЦЫуЖМЪЧЛљгкећЪ§ЕФЃЌЖјВЛЪЧИЁЕуЪ§ЃЌЫљвдЫќМѕЩйСЫЕЅИіБфЛЛЕФМЦЫуСПЃЌвВгаРћгкВЩгУЖЈЕуЕФDSPЪЕЯжЁЃ 2 дкTM1300жаЕФЪЕЯж TM1300ЪЧвЛПю32ЮЛГЌИпадФмЕФЖрУНЬхДІРэЦїЁЃЫќЕФКЫаФДІРэЦїВЩгУЕФЪЧVLIWГЌГЄжИСюзжНсЙЙЃЌПЩвддкУПвЛИіЪБжгжмЦкФкЭЌЪБНјаа5ИіВйзїЃЛжЇГжИпЖШВЂааЕФЖЈжЦВйзїЃЌФмДѓДѓМгПьЪ§зжаХКХДІРэКЭЖрУНЬхгІгУжаГЃМћЕФЬиЪтдЫааЕФадФмЃЌЖјЖЈжЦВйзїдкЪЙгУЩЯРрЫЦгкCгябдКЏЪ§ЕїгУЃЌЗНБуСЫГЬађЕФЩшМЦЁЃ БОЮФеыЖд4x4ЕуећЪ§БфЛЛЕФЬиЕуКЭTM1300ЕФЖЈжЦдЫЫужИСюЕФЬиЕуЃЌЖдећЪ§БфЛЛзїСЫвдЯТЕїећЃКЯШзіааБфЛЛЃЌдйзіСаБфЛЛЁЃгЩгкааБфЛЛЕФНсЙћВЛЛсГЌЙ§16ЮЛЕФБэЪОЗЖЮЇЃЌЙЪдкзїСаБфЛЛжЎЧАЃЌжиаТКЯВЂЪ§ОнЃЌдйзїСаБфЛЛЃЌетбљзїЪЧЛљгквдЯТСНЕуПМТЧЁЃ ЕквЛЃЌгЩгкЪгЦЕЪфШыЪ§ОнЮЊЮоЗћКХЕФзжНкаЭЃЌЖјTM1300ЪЧ32ЮЛЕФДІРэЦїЃЌвдзжЮЊЕЅЮЛЗУЮЪФкДцЃЌФмЬсИпЗУЮЪЕФаЇТЪЁЃЕБЧА4x4Ъ§ОнПщЃЈжИеыЮЊP1ЃЉКЭВЮПМжЁ4%26;#215;4Ъ§ОнПщЃЈжИеыЮЊP2ЃЉЕФЪ§ОнзщжЏШчЯТЁЃД§БфЛЛЕФЕуЮЊЕБЧАЪ§ОнПщЕФжЕгыВЮПМжЁЪ§ОнПщЖдгІЕФжЕжЎВюЁЃ P1:cal,cb1,cc1,cd1 P2:ra1,rb1,rc1,rd1 ca2,cb2,cc2,cd2 ra2,rb2,rc2,rd2 ca3,cb3,cc3,cd3 ra3,rb3,rc3,rd3 ca4,cb4,cc4,cd4 ra4,rb4,rc4,rd4 ЕкЖўЃЌПЩвдРћгУ8ЮЛГЫ/РлМгЕФЖЈжЦВйзїЃЌвЛИіВйзїФмЭъГЩ4Иі8ЮЛГЫ/РлМгЃЌвЛИіЛњЦїжмЦкЃЈCLKЃЉзюЖрФмжДаа5ИіВйзїЁЃгыЗЧЖЈжЦЕФГЫ/РлМгЯрБШЃЌМѕЩйСЫдЫЫуЕФДЮЪ§ЃЌЬсИпСЫГЬађдЫааЕФВЂааЖШЁЃ 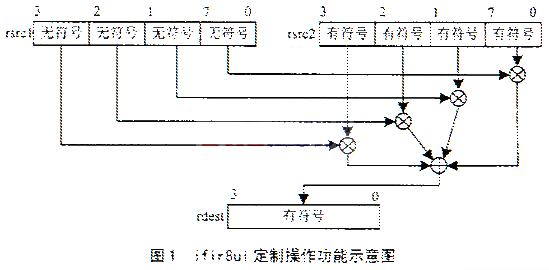 ЭМ1ЮЊifir8uiЖЈжЦВйзїЙІФмЪОвтЭМЁЃ 3 ЪЕбщНсЙћ БОЮФЬсГіЕФЛљгкTM1300ЕФ4x4ећЪ§БфЛЛЕФПьЫйЫуЗЈЃЌЪЙгУСЫВЂааЫуЪЧММЪѕДѓДѓМѕЩйСЫМЦЫуСПЁЃЪЕбщБэУїЃЌНјаа1Иі4x4ЕуећЪ§БфЛЛЃЌжБНггУГЫЗЈКЭМгЗЈдЫЫуашвЊ80ИіЛњЦїжмЦкЃЌИФНјКѓЕФЫуЗЈжЛаш28ИіЛњЦїжмЦкЃЛЖјРћгУTM1300Нјаа1Иі8x8ЕуЖЈЕуDCTБфЛЛашвЊ180ИіЛњЦїжмЦкЃЌвВУїЯдДѓгк4Иі4x4ЕуећЪ§БфЛЛЪБМфЁЃдкБфЛЛЗНУцH.264ЕФБфЛЛБрТыдЫЫуИДдгЖШаЁгкЦфЫќБрТыЗНЗЈЁЃ |
ЭјгбЦРТл