
H.264视频解码器在C6416 DSP上的实现
发布时间:2010-11-25 22:42
发布者:designer
|
多媒体通信终端设备具有广泛的应用前景,可以应用于视频会议、可视电话、PDA、数字电视等各个领域,所以高效、实用的多媒体终端设备一直是通信领域研究的主要方向之一。 多媒体通信终端的实现主要有两点:一方面需要快速、稳定的处理器作为多媒体信号处理的平台,另一方面需要适合多媒体通信的协议标准和软件算法,尤其是对音视频信号的压缩处理算法。两者的结合才能产生高效的多媒体通信设备。目前,随着数字信号处理器(DSP)的高速发展,为实现高效的音视频信号处理提供了可能性;另一方面,最新的低码率视频压缩标准H.264的出台,提供了适合通信的视频标准和算法指导。因此,将两者结合,把H.264算法在DSP上实现,对于多媒体通信的研究具有一定的意义和价值。 本文介绍了H.264解码器算法的DSP实现。在设计中,采用了ATEME公司的网络视频开发平台(NVDK C6416)作为DSP处理平台,实现了H.264的优化解码算法。对于QCIF视频序列,解码速度达50~60帧/秒。 1 网络视频开发平台NVDK简介 NVDK是TI的第三方ATEME公司推出的基于TI C6400系列DSP评估开发套件,是一款适用于图像、视频信号处理的高速DSP开发平台。该套件为诸如视频基础设施及网络化视频设备等高级视频应用制造商提供了方便,提高了数字视频应用项目的开发速度。 1.1 NVDK C6416体系结构 NVDK C6416由TMS320C6416 DSP内核、10/100 Mbps 的以太网子卡、音频/视频接口盒、PCI总线、存储器单元、扩展接口及独立电源等构成。其功能结构框图如图1所示。 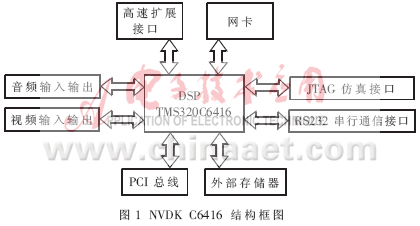 1.2 NVDK C6416的主要特点 NVDK作为网络及视频开发套件,把很多音视频接口及网络接口直接做在板卡上,给采用TI C6000系列DSP芯片作为处理单元的开发用户提供了便利的前端平台。它为项目演示、算法实现、原型制作、数据仿真、FPGA开发和软件优化提供了完整的DSP开发平台。其主要特点如下: ·C6416 DSP内核:600MHz时钟频率及8指令并行结构,最高可以达到4800MIPS的处理能力。 ·视频特点:在输入端,NVDK能够捕获PAL制或NTSC制的模拟视频信号,可以采用复合视频(CVBS)或者S-video视频信号输入,输入模拟视频信号被数字化为YUV422数字视频格式。在输出端,NVDK在支持复合视频(CVBS)以及S-Video输出的同时,还提供了SVGA输出模式,可以直接将信号输出到显示器上。就图像尺寸而言,视频采集提供FULL、CIF和QCIF三种图像格式,视频输出提供FULL和CIF两种图像格式。 ·音频特点:提供两路双声道音频输出,CD音质的输入输出立体声接口,另外还提供一路单声道的麦克风输入。 ·主接口:提供了PCI接口,允许与PC机相连。该板既可以以PCI模式运行,也可以单独脱机工作。 ·网络接口:以太网接口为视频码流的网络传输带来了方便。 ·外部扩展存储器:256M 64位宽扩展内存SDRAMA和8M 32位宽扩展内存SDRAMB及4MB FLASH ROM提供了足够的内存空间和灵活的内存分配方案。 2 H.264视频压缩标准 H.264是由ITU-T 视频编码专家组(VCEG)和ISO/IEC移动图像专家组(MPEG)共同提出的最新国际视频编码标准。它在H.261、H.263视频压缩标准的基础上,进行了进一步的改进和扩展。其目的是为了进一步降低编码码率,提高压缩效率,同时提供一个友好的网络接口,使得视频码流更适合在网络上传送。由于该标准可以提供更低的码率,所以更适合应用于多媒体通信领域。 H.264主要有以下新特点: ·网络适配层NAL(Network Abstraction Layer)。 传统的视频编码编完的视频码流在任何应用领域下(无论用于存储、传输等)都是统一的码流模式,视频码流仅有视频编码层(Video Coding Layer)。而H.264根据不同应用增加不同的NAL片头,以适应不同的网络应用环境,减少码流的传输差错。 ·帧内预测编码模式(Intra Prediction Coding)。 帧内预测编码合理地利用了I帧的空间冗余度,从而大大降低了I帧的编码码流。 ·自适应块大小编码模式(Adaptive Block Size Coding)。 H.264允许使用16×16、16×8、8×16、8×8、8×4、4×8、4×4等子块预测和编码模式,采用更小的块和自适应编码的方式,使得预测残差的数据量减少,进一步降低了码率。 ·高精度亚像素运动估计(High precision sub-pel Motion Estimation)。 H.264中明确提出了运动估计采用亚像素运动估计的方法,并制定1/4像素和1/8像素可选的运动估计方法。亚像素运动估计,提高了预测精度,同时降低了残差的编码码率。 ·多帧运动补偿技术(Multi-frame Motion Compensation)。 传统的视频压缩编码采用一个(P帧)或两个(B帧)解码帧作为当前帧预测的参考帧。在H.264中,最多允许5个参考帧,通过在更多的参考帧里进行运动估计和补偿,找到残差更小的预测块,降低编码码率。 ·整形变换编码(Inter Transform Coding)。 H.264采用整形变换代替DCT变换,整形变换采用定点运算代替浮点运算。采用这种变换,不仅可以降低编解码的时间,而且,为该算法在多媒体处理平台上实现带来了方便。在这一点上,H.264视频编码标准更适合作为多媒体终端的编解码标准。 ·两种可选择熵编码CAVLC和CABAC。 CAVLC(Context-based Adaptive Variable Length Coding):基于内容的自适应变长编码。 CABAC(Context-based Adaptive Binary Arithmetic Coding):自适应二进制算术编码。 以往的视频压缩标准中,都采用Huffman编码与变长编码相结合的方法进行熵编码。Huffman编码虽然是一种很好用的熵编码方法,但是其编码效率并不是最高的,而且,Huffman编码的抗差错性能很低。H.264中采用了两种可以选择的熵编码方法:CAVLC编码抗差错能力比较高,但是编码效率不是很高;CABAC编码是一种高效率的熵编码方法,但是计算复杂度很高。两者各有优缺点,所以针对不同的应用,选择不同的编码方法。 3 H.264解码器算法的DSP实现和优化 3.1 在PC机上实现H.264算法并进行优化 ITU-T官方提供的H.264的核心算法不仅在代码结构上需要改进,而且在具体的核心算法上也需要做大的改动,才能达到实时的要求。这一步需要做的具体工作包括:去处冗余代码、规范程序结构、全局和局部变量的调整和重新定义、结构体的调整等。 3.2 PC机H.264代码的DSP化 C6000开发工具Code Composer Studio有自己的ANSI C编译器和优化器,并有自己的语法规则和定义,所以在DSP上实现H.264的算法要把PC机上C语言编写的H.264代码进行改动,使其完全符合DSP中C的规则。 这些改动包括:去除所有的文件操作;去除可视化界面的操作;合理安排内存空间的预留和分配;规范数据类型——因为C6416是定点DSP芯片,只支持四种数据类型:short型(16 bit)、int(32bits)、long型(40bits)和double型(64bits),因此必须对数据进行重新规范,把浮点数的运算部分近似用定点表示,或用定点实现浮点运算;根据内存的分配定义远近程常量和变量;把常用的数据在数据结构中提取出来,以near型数据定义在DSP内部存储空间,以减少对EMIF端口的读取,从而提高速度。 3.3 H.264的DSP算法优化 通过把PC机H.264代码DSP化,可以在DSP上实现H.264的编解码算法,但是,这样实现的算法运行效率很低,因为所有的代码都是由C语言编写,并没有完全利用DSP的各种性能。所以必须结合DSP本身的特点,对其进一步优化,才能实现H.264视频解码器算法对视频图像的实时处理。 对DSP代码的优化共分为三个层次:项目级优化、C程序级优化、汇编程序级优化。 (1)项目级优化:主要是通过选择CCS提供的编译优化参数,根据H.264系统的要求进行优化,通过不断地对各个参数( -mw -pm -o3 -mt等)的选择、搭配、调整,改善循环、多重循环体的性能,进行软件流水,从而提高软件的并行性。 (2)C程序级优化:主要是针对采用的DSP的具体特点进行代码的功能精简、数据结构的优化、循环的优化、代码的并行化处理。在这里主要工作包括以下部分:去除掉SNR计算、帧率及其他辅助信息的程序模块。函数及数据映射区域的调整,把经常用的数据存储在片内存储器中,频繁调用的程序尽可能映射在相邻或相近的存储区域。C函数的并行化处理,针对并行化效果差的函数,尤其是多重循环体,要进行循环拆解,将多重循环拆解为单重循环。减少存储区数据的读取和存储,尤其是片外存储区域数据的调用,以减少时间。数据结构的重定义和调整。 下面以数据结构的调整说明如何合理利用DSP特性进行软件优化。 数据结构是指数据的类型及其在内存空间的分配方式,不同的数据结构,对程序的性能有不同的影响。因此,数据结构的调整对程序在DSP上并行执行是必不可少的步骤。 在H.264解码器内核代码中,数组mpr[ i][j]用来存放一个宏块的预测系数,数据类型是int型,其中i、j是该系数的坐标。但是预测系数实际上只有8位位宽,所以,定义成byte型就足够了。这样一方面节省了内存空间,另一方面,用byte类型可以直接使用LDW指令代替LDB指令,一次读取4个数据,节省了读取时间。因为H.264中对系数的读取都是以块为单位的,而内核中的mpr数据结构显然不能充分利用DSP的特性,所以数据存储结构也需要调整,把mpr中每一个块分配到一个连续的内存空间有利于数据的传送,如图2所示。这样,每一次确定了一个块以后,只要更改一维的信息就能确定系数的位置,而原始的结构对每一个系数都有确定两位系数。通过这样的数据调整,可以明显地提高程序的运行速度。  (3)汇编程序级优化。汇编级的优化包括两部分:采用线性汇编语言进行优化和直接用汇编语言进行优化。由于系统编译器的局限性,并不能将全部的函数都很好地优化,这样就需要统计比较耗时的C语言函数,用汇编语言重新编写。这些函数包括:插值函数、帧内预测函数、整形反变换等函数。 下面以差值函数中的一段来说明汇编编写带来的性能提高。 横向1/2插值源代码: for (j = 0; j < BLOCK_SIZE; j++) { for (i = 0; i < BLOCK_SIZE; i++) { for (result = 0, x = -2; x < 4; x++) result += mref[ref_frame][ y_pos+j][ x_pos+i+x]*COEF[x+2]; block[ i][j] = max(0, min(255, (result+16)/32)); } } 该段代码采用一个六阶滤波器来插值1/2位置的像素值,共插出16个值(一个块)。源代码采用三重循环,内层循环是插值滤波器,如果直接用编译器把源代码编译成汇编的话,内部循环都要反复读取一些内存数据。采用汇编自己编写,则可以改进算法,大大降低函数的运行时间。 如图3所示,在插值第一个半像素位置时,要在内存中读取1~6像素的值,插值第二个半像素位置时,要读取2~7点的值,这样,就反复读取了2~5像素点的值,而且,插值一个点需要进行6次乘法、5次加法。用汇编语言编写,手工排流水线,可以降低数据的读取次数,同时减少了乘、加法指令数。首先,采用LDNW指令直接读取8个数据到寄存器中,每次插值直接使用寄存器而不再去内存中读取数据。另外,采用DOTPSU4乘累加命令代替MPL指令,将四次乘法和3次加法用一条指令来代替,减少了指令数目。 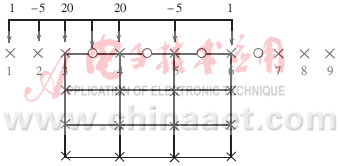 通过以上各种优化方法,最终实现了基于C6416内核的H.264 baseline解码器算法。 4 算法性能的评测及前景展望 在NVDK C6416环境下,测试了解码器算法,对QCIF测试序列,已经能够达到50~60帧/秒的解码速度,远远达到了实时性解码的目的。 在NVDK C6416板卡上实现的H.264视频解码器具有功能强、使用灵活等特点,有广泛的应用前景。该优化的算法不仅适用于NVDK板,对于所有的C64开发板都具有通用性,只要根据板卡的内存分配,重新配置内存参数文件,便可以把该算法移植到新的开发板中。该H.264视频解码器与网络平台相连接便可以应用于视频会议、可视电话、无线流媒体通信等应用领域。 |



网友评论