
Vivado设计套件提升设计生产力的九大优势
发布时间:2014-12-18 15:38
发布者:designapp
|
您的开发团队是否需要在极短的时间内打造出既复杂又富有竞争力的新一代系统?赛灵思All Programmable器件可助您一臂之力,它相对传统可编程逻辑和I/O,新增了软件可编程ARM处理系统、可编程模拟混合信号(AMS)子系统和不断丰富的高复杂度的IP,支持开发团队突破原有的种种设计限制。赛灵思有多种All Programmable器件可供用户选择,构成这些器件的各种硅片组合使用赛灵思独特的高性能3D堆叠硅片互联技术彼此互联。这些领先一代的All Programmable器件为用户提供的功能,远超常规可编程逻辑所能及,为用户开启了一个全面可编程系统集成的新时代。 All Programmable抽象化与自动化有何意义? 其意义在于采用赛灵思All Programmable器件,用户的开发团队可以用更少的部件实现更多系统功能,提升系统性能,降低系统功耗,减少材料清单(BOM)成本,同时满足严格的产品上市时间要求。但如果不借助强大的硬件、软件、系统设计工具和设计流程,则无法将这些优势交到您的设计团队的手中,您也不可能实现这些优势。赛灵思把所需的这些硬件、软件和系统设计开发流程统称为“All Programmable抽象化(All Programmable Abstraction)”。  All Programmable抽象化与自动化 在这种使用All Programmable抽象化进行先进的领先一代的硬件、软件和系统开发过程中,起着核心作用的是赛灵思Vivado设计套件。Vivado设计套件是一种以IP和系统为中心的、领先一代的全新SoC增强型综合开发环境,可解决用户在系统级集成和实现过程中常见的生产力瓶颈问题。 就在同类竞争解决方案还在试图通过扩展过时且松散连接的分立工具来跟上片上集成的高速发展的时候,Vivado设计套件凭借业界最先进的SoC增强型设计方法和算法,提供了独特、高度集成的开发环境,为设计者带来了设计生产力的极大提升。Vivado设计套件将硬件、软件和系统工程师的生产力提升到了一个全新的水平。 以下九大理由,将让您了解到Vivado设计套件为何能够提供领先一代的设计生产力、简便易用性,以及强大的系统级集成能力。 【分页导航】
加快系统实现 理由一:突破器件密度极限:在单个器件中更快速集成更多功能 如果设计工具能够让All Programmable器件集成更多功能,用户就能够在系统设计中选择尽可能小的器件,从而直接带来系统成本和功耗的下降。Vivado设计套件提供一种集成环境,能够让架构、软件和硬件开发人员在通用设计环境中协作工作,从而最大程度地提升设计效率,充分发挥All Programmable器件的可编程逻辑架构及其专用片上功能模块的潜力。 以OpenCores.org的以太网MAC(媒体访问控制器)模块设计为例。作为实验,赛灵思反复原样复制OpenCores以太网MAC,直至它们填充带有693,120个逻辑单元的Virtex-7 690T FPGA。赛灵思又以类似的方法填充带有622,000个逻辑单元的同类竞争器件。下图显示的是实验结果。 按逻辑单元数量来衡量(一个“标准”的逻辑单元由一个4输入LUT(查找表)和一个触发器组成),赛灵思Virtex-7 690T器件的原始容量比同类竞争器件(带有622,000个逻辑单元)高出11%。但如图1所示,如果用Vivado设计套件将所有这些以太网MAC模块实例填充到赛灵思Virtex-7 690T器件中,赛灵思Virtex-7 690T器件要比同类竞争器件容纳的实例数多出36%。这个实验表明,Vivado设计套件与赛灵思7系列FPGA架构结合使用所产生的效率,要远高于同类竞争工具/器件组合所产生的效率。 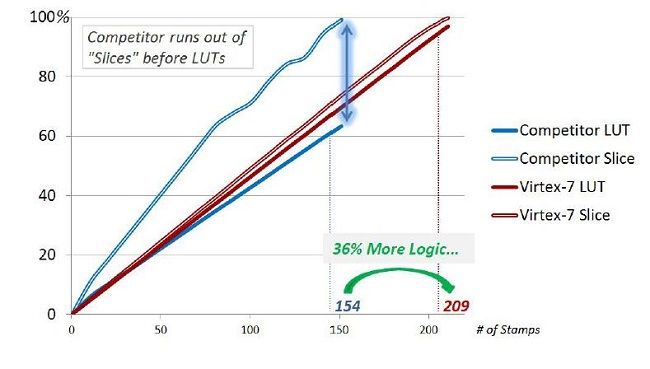 图1:复制次数与架构资源利用率的对比 (注:图1根据LUT和Slice计数结果,对赛灵思7系列All Programmable器件和同类竞争可编程逻辑器件进行比较。赛灵思7系列All Programmable器件slice含四个6输入LUT、八个触发器以及相关的多路复用器和算术进位逻辑,相当于1.6个逻辑单元。) Vivado设计套件如何最大化器件利用率 Vivado设计套件之所以能够实现更高的器件利用率,是因为它采用高级拟合算法,而且赛灵思7系列可编程逻辑架构在每个Slice内采用真正独立的LUT。值得注意的是,图1详尽地体现了赛灵思7系列的LUT和Slice拟合结果,两者均实现了近100%的利用率。而同类竞争的可编程逻辑器件在器件利用率仅达到63%就用尽了可用的Slice。产生这种低利用率的根源归咎于该竞争器件的可编程逻辑架构,这种架构在许多情况下不允许把两个LUT捆绑成一个物理集群。在完整的设计中,这显然会产生大量未充分利用的集群。这是由于为了满足架构的引脚共享要求,只有一个LUT得到使用,而另一个LUT则不能再用于设计中其余的逻辑。这项实验清楚地表明,用户可以使用更小的7系列All Programmable来实现更大的系统设计。 在这个IP模块拟合实验中,Vivado设计套件与同类可编程器件形成了鲜明的对:Vivado设计套件实现了99%的LUT利用率,而且即便在如此高利用率水平下,它还能在完成设计布局布线的同时,满足时序约束。Vivado布局布线算法旨在处理高密度、高难度设计,便于用户将更多逻辑置于该器件中,从而降低用户的系统材料清单(BOM)成本和系统功耗。 【分页导航】
理由二:Vivado以可预测的结果提供稳健可靠的性能和低功耗 出于纳米级IC设计的物理原因,互联已经成为28nm及更高工艺节点的可编程逻辑器件架构的性能瓶颈。Vivado设计套件采用先进的布局布线算法,可突破该性能瓶颈,而且点击鼠标即可得到高性能结果。 Vivado设计套件的分析型布局布线算法能够同步优化包括时序、互联使用和走线长度在内的多重变量,提供可预测的设计收敛。同时,Vivado的实现引擎可保证在逻辑利用率高的大型器件上得到的结果和在器件利用率较低的设计上得到的结果一样优异。此外,在系统设计规模随着系统功能的增加而逐步增大的情况下,Vivado既能保持高性能结果,还能提高各次运行结果间的一致性。 如图2所示,与同类竞争工具相比,Vivado设计套件可随着利用率的提升提供更出色的性能,同时还能处理更大规模的设计。 注:如图2所示,同类竞争工具的结果的平均变动要比使用Vivado设计套件得到的结果大四倍。另外,值得注意的是同类竞争解决方案在填满器件时,可用性能下降了一半。与此形成鲜明对比的是,Vivado设计套件在受测的不同设计上得到的结果一致,性能保持稳定。最后还需要注意是同类竞争解决方案不能处理Vivado设计套件能够成功处理的大型系统。同类竞争解决方案很快就不堪重负。 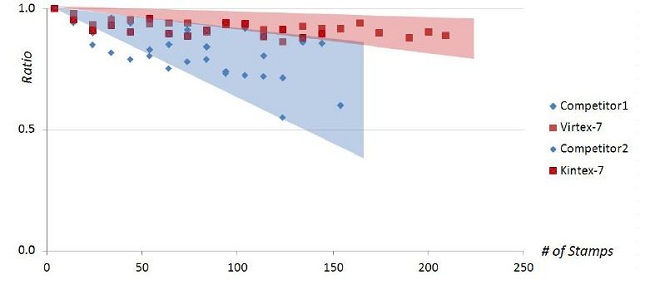 图2:以复制次数为标准的性能对比 Vivado降低系统功耗 Vivado设计套件提供了业界一流的系统功耗分析与优化工具。从架构或器件选择阶段开始,设计人员就可以运用准确且易用性无与伦比的Xilinx Power Estimator(XPE,赛灵思功耗评估器)电子数据表来确定系统功耗。设计人员不仅能够通过XPE的快速 评估(Quick Estimate)和IP向导轻松入门,而且还能够简单并排比较多种实现方案,帮助设计团队微调设置,以便地为各种场景精确建模。 当设计进入编译阶段,Vivado设计套件继续提供准确的功耗分析和估算。Vivado设计套件开箱即用,能够在不给系统设计的时序造成负面影响的情况下自动降低设计的功耗。如果用户还需要进一步降低功耗,可以使用Vivado设计套件独有功能,充分利用赛灵思7系列精细粒度时钟门控技术,进一步降低整个系统设计或部分设计的功耗。 这种Vivado设计套件实现的智能时钟门控优化技术能够平均降低动态功耗18%,如图3所示。 Vivado设计套件提供了一系列无与伦比功能与特性,可帮助用户轻松完成对设计的分析工作。用户可以甄别出功耗最大的模块,从而明确从哪些模块切入,高效而明显降低系统功耗。所有这些功能都内置在通用Vivado集成设计环境(IDE)中,所以设计团队仅借助一款统一的工具套件,就可一次性最小化系统功耗。 系统功耗是设计大多数产品时应考虑的一个重要因素,Vivado设计套件提供的领先一代设计工具是对赛灵思All Programmable器件的有力补充和完善。  图3:运用智能时钟门控优化实现的动态功耗比率(按动态功耗降幅分类) 【分页导航】
理由三:Vivado设计套件提供了无与伦比的运行时间和存储器利用率 从设计人员生产力考虑,设计工具应能够快速运行,最好是快到每天能够完成多次编译,这样设计团队就能够迅速得到最终设计。从一开始Vivado设计套件就是为高速运行设计的,比同类竞争的可编程逻辑设计工具的速度明显要快得多。 同样以之前讨论过的OpenCores以太网MAC模块设计为例。图4说明,随着实例数量的增加,Vivado设计套件的运行时间比竞争对手的软件快三倍。此外,数据还表明,Vivado的运行时间的增减可以预测,即运行时间只单调地随设计规模增减。与此形成鲜明对比的是,同类竞争软件的运行时间无规律性。例如94个实例的设计完成的速度比使用84个实例的设计快。 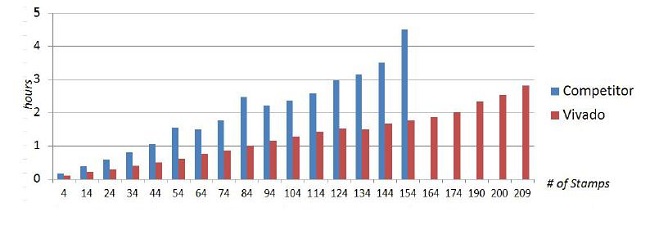 图4:运行时间比较 Vivado内存占用更小 Vivado设计套件采用先进高效的数据模型和结构,内存占用极小且明显低于同类竞争解决方案的内存占用。此处仍以OpenCores以太网MAC模块为例。要成功运行规模最大的设计(154个实例),竞争软件需要占用16GB的RAM,相比之下运行同样规模大小的设计,Vivado设计套件占用的内存要小三分之二(见图5)。内存占用减少意味着Vivado设计套件拥有明显的生产力优势,因为设计人员在编译较大型系统设计时不会耗尽内存。 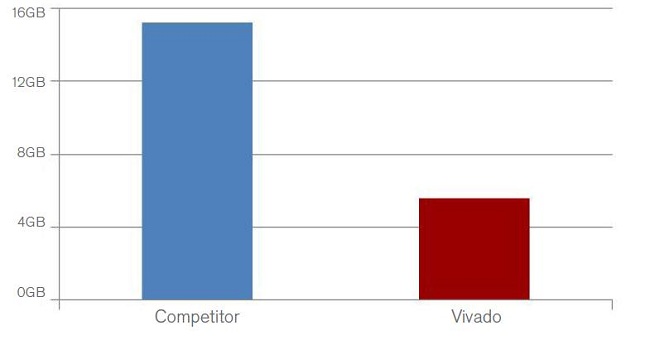 图5:内存占用 【分页导航】
加快系统集成 理由四:使用Vivado高层次综合生成基于C语言的IP 如今的无线、医疗、军用和消费类应用均比以往更加尖端,使用的算法也比以往更加复杂。业界算法开发的金标准就是采用C、C++和SystemC高级编程语言。过去设计流程中需要经过一个缓慢且容易出错的步骤来将用C、C++或SystemC语言编写的算法转换为适合于综合的Verilog或VHDL硬件描述。而现在Vivado设计套件系统版本中提供的Vivado高层次综合功能可轻松地自动完成这一步骤。 您以往可能听说过C语言级硬件综合。不管您听说过什么,C语言级算法综合已成为系统级设计的捷径。当前有超过400名用户正在成功利用Vivado高层次综合(HLS)技术开发符合C、C++和SystemC语言规范的赛灵思All Programmable器件用IP硬核。 Vivado HLS通过下列功能,让系统和设计架构师走上IP硬核开发的捷径: ● 算法描述、数据类型规格(整数、定点或浮点)和接口(FIFO、AXI4、AXI4-Lite、AXI4-Stream)抽象化; ● 采用可提供最佳QoR(结果质量)的基于指令的架构感知型编译器; ● 使用C/C++测试平台仿真、自动化VHDL/Verilog仿真和测试台生成功能加快模块级验证; ● 发挥整套Vivado设计套件的功能,将生成的IP硬核轻松嵌入基于RTL的设计流程中;发挥Vivado System Generator for DSP的功能,将生成的IP硬核轻松嵌入基于模型的设计;发挥Vivado IP集成器(Vivado IP Integrator)的功能,将生成的IP硬核轻松集成到基于模块的设计。 这样硬件设计人员就有更多时间投入到设计领域的探索中,即有更多时间评估备选架构,找出真正理想的设计解决方案,轻松应对各种严峻的系统设计挑战。例如设计人员将行业标准的浮点math.h运算与Vivado HLS结合使用,就能够在实现较手动编码的RTL更优异的QoR的同时,让线性代数算法的执行速度呈数量级提高(10倍),如表1所示。 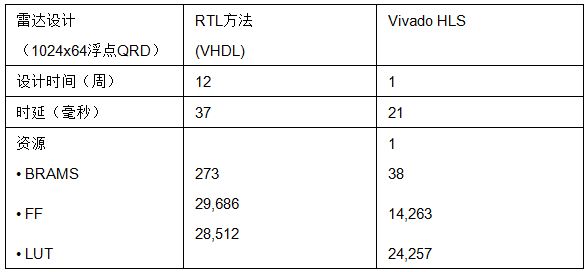 表1:Vivado HLS实现的QoR 通过集成到OpenCV环境中的预先编写、预先验证的视觉与视频功能,Vivado HLS还能加速基于赛灵思Zynq-7000 All Programmable SoC器件的系统的实时Smarter Vision算法的开发工作。此类系统使用运行在Zynq SoC的双核ARM处理系统上的软件和位于Zynq SoC高性能FPGA架构上的硬件来运行这些算法(如图6所示)。  图6:Vivado HLS加快基于OpenCV的开发工作 图字:  使用Vivado HLS Smarter Vision库的各项功能,用户借助硬件加速就能迅速实现复杂像素处理接口和基本视频分析功能的实时运行。 (如欲立即开始使用Vivado HLS,敬请下载《如何使用Vivado高层次综合的FPGA设计》。这是一本以赛灵思对其主要客户举办的培训为依据的综合性用户指南。该指南可快速向软件工程师教授如何将软件算法从处理器上移植到赛灵思All Programmable FPGA和SoC的可编程逻辑上,加快他们的代码运行速度。) 【分页导航】
理由五:利用System Generator for DSP实现基于模块的DSP设计集成 如上文所述,Vivado设计套件系统版本提供System Generator for DSP,这是一款行业领先的将DSP算法转换为高性能生产质量级硬件的高级设计工具,转换所需时间仅为传统RTL设计方法的几分之一。Vivado System Generator for DSP可让开发人员运用业界最先进的All Programmable系统建模工具(MathWorks提供的Simulink和MATLAB),无缝集成那些可用Vivado HLS综合到硬件中的算术函数、SmartCORE与LogiCORE IP、定制RTL以及基于C语言的模块,从而加速高度并行系统的开发。图7所示的是使用Vivado HLS和Vivado System Generator for DSP将基于C语言的模块集成到Simulink中的设计流程。 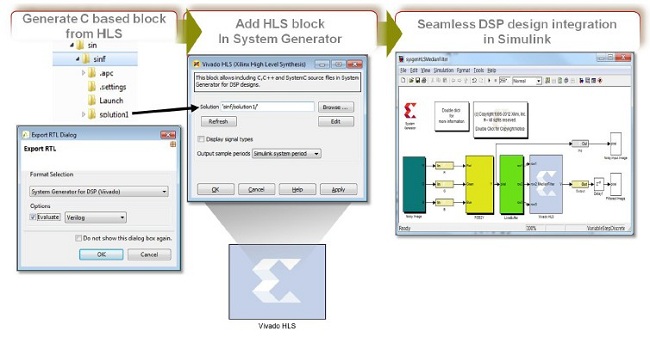 图7:使用Vivado HLS和Vivado System Generator for DSP将基于C语言的模块集成到Simulink中 Vivado System Generator for DSP提供自动定点/浮点硬件生成功能、可将Simulink仿真速度提高1000倍的硬件协同仿真功能、用于基于RTL的Vivdo设计流程的系统集成功能,以及用Vivado IP集成器实现的基于模块的设计功能,可进一步加快系统实现。 【分页导航】
理由九:采用C、C++和SystemC语言将验证速度提高100倍以上 如前文所讨论的,Vivado设计套件系统版本内置Vivado HLS,可帮助用户的设计团队用C、C++和SystemC语言迅速完成算法设计的创建与迭代工作,同时还在验证工作中发挥这些高级编程语言的高仿真速度优势。使用Vivado HLS定点和业界标准浮点math.h库,开发人员运用C函数规范即可快速为设计建模并完成设计迭代,然后仅根据时钟周期和吞吐量等考虑因素建立目标感知的RTL架构。将C、C++和SystemC语言用作初始设计和建模语言可极大地加快仿真速度(比RTL仿真速度快数千倍)。在一个视频设计实例中,10个经处理的视频帧的仿真速度采用C语言比采用HDL快12,000倍,如表2所示。  表2:Vivado设计套件的视频设计仿真速度快1.2万倍 总结 赛灵思Vivado设计套件是一种以IP和系统为中心的、领先一代的全新SoC增强型开发环境,用于解决系统级集成和实现工作中的生产力瓶颈问题。这套设计工具专为系统设计团队开发,旨在帮助他们在更少的器件中集成更多系统功能,同时提升系统性能,降低系统功耗,减少材料清单(BOM)成本。 Vivado设计套件由于如下九大理由,是帮助您实现上述这些目标的理想系统设计工具: ● Vivado设计套件可让用户进一步提升器件密度。 ● Vivado设计套件可提供稳健可靠的性能,降低功耗以及可预测的结果。 ● Vivado设计套件可提供无与伦比的运行时间和存储器利用率。 ● Vivado HLS能够让用户用C、C++或SystemC语言编写的描述快速生成IP核。 ● Vivado设计套件借助MathWorks公司提供的Simulink和MATLAB工具可支持基于模型的DSP设计集成。 ● Vivado IP集成器突破RTL的设计生产力制约。 ● Vivado集成设计环境为设计和仿真提供统一集成开发环境。 ● Vivado设计套件提供综合而全面的硬件调试功能。 ● Vivado HLS使用C、C++或CSystem语言可将验证速度提高100倍以上。 您的设计团队不妨立即试试Vivado设计套件,体验一下其带来的强大优势? 【分页导航】
|




网友评论