
ЛљгкЧЖШыЪНЯЕЭГЕФгявєПкСюЪЖБ№ЯЕЭГЕФЪЕЯж
ЗЂВМЪБМфЃК2010-11-24 16:12
ЗЂВМепЃКeetech
|
ЫцзХМЦЫуЛњММЪѕКЭаХЯЂММЪѕЕФбИЫйЗЂеЙЃЌгявєПкСюЪЖБ№вбОГЩЮЊСЫШЫЛњНЛЛЅЕФвЛИіживЊЗНЪНжЎвЛЁЃгявєПкСюЪЖБ№ЯЕЭГНЋИљОнШЫЗЂГіЕФЩљвєЁЂвєНкЛђЖЬгяИјГіЯьгІЃЌШчЭЈЙ§гявєПкСюПижЦвЛаЉжДааЛњЙЙЁЂПижЦМвгУЕчЦїЕФдЫааЛђзіГіЛиД№ЕШЁЃдкЪ§зжаХКХДІРэаОЦЌЩЯвбОЪЕЯжСЫгявєПкСюЪЖБ№ЯЕЭГЛђгявєПкСюЪЖБ№ЯЕЭГЕФВПЗжЙІФмЃЌШЛЖјЫцзХЧЖШыЪНЮЂДІРэЦїДІРэФмСІЕФДѓЗљЖШЬсИпЃЌМЦЫуСПДѓЕФгявєПкСюЪЖБ№ЫуЗЈвбОФмЙЛЭЈЙ§ЧЖШыЪНЮЂДІРэЦїРДЭъГЩЃЌНЋгявєПкСюЪЖБ№ЯЕЭГгыЧЖШыЪНЯЕЭГЯрНсКЯЃЌЗЂЛггявєЪЖБ№ЯЕЭГЕФЧБСІЃЌЪЙгявєЪЖБ№ЯЕЭГФмЙЛЙуЗКгІгУгкБуаЏЪНЩшБИжаЁЃ ВЩгУвўТэЖћПЫЗђФЃаЭ(Hidden Markov MODELЃЌHMM) УшЪігявєаХКХЕФЗЧЦНЮШадКЭОжВПЦНЮШадЃЌHMMжаЕФзДЬЌгыгявєаХКХЕФФГИіЦНЮШЖЮЯрЖдгІЃЌЦНЮШЖЮжЎМфвдзЊвЦИХТЪЯрСЊЯЕЁЃгЩгкHMMНЈФЃЖдгявєаХКХГЄЖШКЭФЃаЭЕФЛьКЯЖШЕФвЊЧѓЖМБШНЯЕЭЃЌвђДЫдкЯжгаЕФЗЧЬиЖЈШЫгявєПкСюЪЖБ№ЯЕЭГжаЃЌЖрВЩгУзДЬЌЪфГіОпгаСЌајИХТЪЗжВМЕФСЌајвўТэЖћПЩЗђФЃаЭ(ConTInuous Density Hidden Markov MODELЃЌCDHMM)ЁЃ ТлЮФИјГівЛжжЛљгкЧЖШыЪНЯЕЭГЕФгявєПкСюЪЖБ№ЯЕЭГЕФЩшМЦЗНАИЃЌгВМўЯЕЭГЕФКЫаФаОЦЌЪЧЧЖШыЪНЮЂДІРэЦїЃЌгявєПкСюЪЖБ№ЫуЗЈВЩгУCDHMMЁЃгявєПкСюЪзЯШОЙ§дЄДІРэЃЌЬсШЁMFCC(Mel-Frequency Ceptral Coefficients)ЬиеїВЮЪ§ЃЌШЛКѓНЈСЂДЫПкСюЕФCDHMMФЃаЭЃЌАбЫљгагявєПкСюЕФФЃаЭЗХдкФЃаЭПтжаЃЌдкЪЖБ№НзЖЮЃЌЭЈЙ§ИХТЪЪфГі*ЗжЃЌШЁ*ЗжзюДѓЕФвЛИізїЮЊЪЖБ№ГіЕФПкСюЁЃНЋгявєЪЖБ№ЯЕЭГгыЧЖШыЪНЯЕЭГЯрНсКЯЃЌПЩвдЪЙгявєПкСюЪЖБ№ЯЕЭГЙуЗКгІгУгкБуаЏЪНЩшБИжаЁЃ 1 гВМўЕчТЗЕФЩшМЦКЭЙЄзїдРэ ЛљгкЧЖШыЪНЯЕЭГЕФгявєПкСюЪЖБ№ЯЕЭГашвЊгаНгЪегявєаХКХЕФЪфШыаОЦЌХфКЯТѓПЫЗчЪЕЯжНЋФЃФтгявєаХКХзЊЛЛГЩЪ§зжаХКХЕФЙІФмЃЌШЛКѓгЩЧЖШыЪНЮЂДІРэЦїЖдЪфШыЕФгявєПкСюаХКХНјааДІРэЁЃЭъГЩгявєПкСюаХКХЪфШыЙІФмЕФаОЦЌВЩгУЕФЪЧPHILIPSЙЋЫОЕФЕЭЙІКФаОЦЌUDAl341TSЃЌЙЉЕчЕчдДЕчбЙЮЊ3VЃЌИУвєЦЕДІРэаОЦЌгЩФЃЪ§ЃЏЪ§ФЃзЊЛЛ(ADC)ЁЂПижЦТпМЕчТЗЁЂПЩБрГЬдівцЗХДѓЦї(PGA)КЭЪ§зжздЖЏдівцПижЦЦї(DAGC)вдМАЪ§зжаХКХДІРэЦїЕШВПЗжзщГЩЃЌФмНјааЪ§зжгявєДІРэЁЃ аОЦЌUDAl341TSВЩгУБъзМЕФФкВПМЏГЩЕчТЗЩљвєзмЯпIIS(Inter IC Sound Bus)ЃЌИУзмЯпЪЧгЩPHILIPSЕШЙЋЫОЙВЭЌЬсГіЕФЪ§зжвєЦЕзмЯпавщЃЌзЈУХгУгквєЦЕЩшБИжЎМфЕФЪ§ОнДЋЪфЃЌФПЧАКмЖрвєЦЕаОЦЌКЭЮЂДІРэЦїЖМЬсЙЉСЫЖдIISзмЯпЕФжЇГжЁЃ IISзмЯпгаШ§ИљаХКХЯпЃЌЗжБ№ЪЧЮЛЪБжгаХКХBCK(Bit Clock)ЁЂзжбЁдёПижЦаХКХWS(Word Select)КЭДЎааЪ§ОнаХКХDataЃЌгЩжїЩшБИЬсЙЉДЎааЪБжгаХКХКЭзжбЁдёПижЦаХКХЃЌIISзмЯпЕФЪБађШчЭМ1ЫљЪОЁЃ 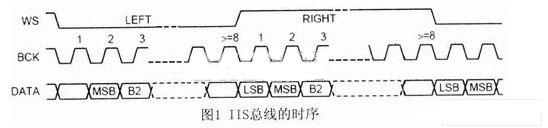 WSвВГЦЮЊжЁЪБжгаХКХЃЌИУаХКХЕФЕчЦНЮЊЕЭЕчЦНЪБЃЌДЋЪфЕФЪфШывєЦЕЪ§ОнаХКХЪЧзѓЩљЕРЕФвєЦЕЪ§ОнаХКХЃЛаХКХWSЕФЕчЦНЮЊИпЕчЦНЪБЃЌДЋЪфЕФЪфШывєЦЕЪ§ОнаХКХЪЧгвЩљЕРЕФвєЦЕЪ§ОнаХКХЁЃBCKЖдгІзХЪфШывєЦЕЪ§ОнаХКХЕФУПвЛЮЛвєЦЕЪ§ОнЃЌЦфЦЕТЪЮЊ2ЁСВЩбљЦЕТЪЁСУПИіВЩбљжЕЕФЮЛЪ§ЁЃ гыBCKЭЌВНЕФДЎаавєЦЕЪ§ОнаХКХВЩгУВЙТыЕФаЮЪНДЋЪфЃЌДЋЪфЫГађЪЧИпЮЛЯШДЋЪфЁЃIISзмЯпИёЪНЕФаХКХЮоТлгаЖрЩйЮЛгааЇЪ§ОнЃЌЪ§ОнЕФзюИпЮЛMSBзмЪЧГіЯждкWSаХКХИФБф(вВОЭЪЧДЋЪфвЛжЁЪ§ОнаХКХПЊЪМ)КѓЕФЕк2ИіДЎааЪ§ОнаХКХSCLKТіГхЮЛжУЁЃ ЭЈЙ§ЩЯЪіIISзмЯпФмЙЛЕУЕНЪфШыЕФвєЦЕЪ§ОнаХКХЃЌЖјЦфЫќЕФаХКХШчздЖЏдівцПижЦЁЂЪфШыЪ§ОнИёЪНЕФбЁдёКЭЪфШыдівцЕФПижЦЕШПижЦаХКХЭЈЙ§ГЦЮЊЁАL3ЁБ аЮЪНЕФНгПкзмЯпДЋЪфЁЃЮЊСЫМѕЩйв§НХЪ§КЭБЃГжСЌЯпМђЕЅЃЌИУНгПкзмЯпВЩгУДЎааЪ§ОнДЋЪфЗНЪНЃЌНгПкзмЯпгЩ3ЬѕаХКХЯпзщГЩЃКЪБЗжИДгУЕФЪ§ОнЭЈЕРЯпL3DATAЁЂФЃЪНПижЦЯпL3MODEКЭЪБжгаХКХЯпL3CLOCKЁЃФЃЪНПижЦЯпL3MODEЮЊЕЭЕчЦНЪБЕФДЋЪфФЃЪНЮЊЕижЗДЋЪфФЃЪНЃЛЮЊИпЕчЦНЪБЕФДЋЪфФЃЪНЮЊЪ§ОнДЋЪфФЃЪНЁЃ гявєПкСюЪЖБ№ЯЕЭГЕФгВМўЕчТЗЕФКЫаФаОЦЌЪЧЧЖШыЪНЮЂДІРэЦїSamsung S3C2440 ALЃЌжїЦЕЮЊ400MHzЁЃШ§аЧЙЋЫОЭЦГіЕФRISCЮЂДІРэЦїS3C2440 ALОпгаЕЭЙІКФЁЂИпадФмЕШЬиЕуЃЌПЩвдЙуЗКгІгУгкБуаЏЪНЩшБИжаЁЃS3C2440ALОпгавЛИіIISзмЯпвєЦЕБрТыЃЏНтТыНгПкЃЌгявєПкСюЪЖБ№ЯЕЭГЕФгВМўЕчТЗШчЭМ 2ЫљЪОЁЃЦфIISзмЯпПижЦЦїЭЈЙ§5ИљаХКХЯпгыUDAl34lTSБрНтТыаОЦЌЯрСЌЁЃетаЉ5ИљаХКХЯпЗжБ№ЪЧЃКЯЕЭГЪБжгаХКХCDCLKЃКЮЛЪБжгаХКХI2- SSCLKЃЛзжбЁдёПижЦаХКХI2SLRCKЃЛДЎааЪ§ОнЪфШыаХКХI2SSDIЃЛДЎааЪ§ОнЪфГіаХКХI2SDOЁЃS3C2440 ALЪЙгУL3НгПкДЋЪфЦфЫћ(ШчздЖЏдівцПижЦЁЂЪфШыЪ§ОнИёЪНЕФбЁдёКЭЪфШыдівцЕФПижЦЕШ)ПижЦаХКХЁЃЮЊСЫЪЙЯЕЭГМфФмЙЛИќКУЕиЭЌВНЃЌS3C2440ALашвЊЯђаОЦЌUDAl341TSЬсЙЉCDCLKЃЌИУЪБжгаХКХЕФЦЕТЪПЩвдбЁдёВЩбљЦЕТЪЕФ256БЖЁЂ384БЖЛђ512БЖЁЃ 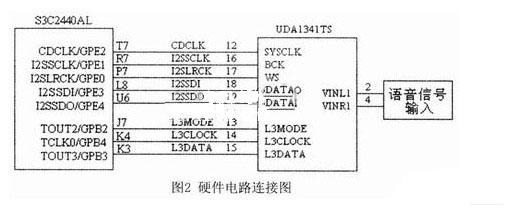 2 ЛљгкCDHMMЕФПкСюЪЖБ№ЕФШэМўЩшМЦ 2ЃЎ1 ПкСюЪЖБ№ЕФШэМўЯЕЭГПђЭМ гявєПкСюЪЖБ№ЕФШэМўЯЕЭГЗжБ№гЩЬиеїВЮЪ§ЬсШЁЁЂгявєФЃаЭПтКЭИХТЪЪфГі*ЗжШ§ДѓФЃПщзщГЩЃЌШчЭМ3ЫљЪОЃК1)гявєПкСюЬиеїВЮЪ§ЕФЬсШЁЃЌЪфШыВЛЭЌЕФгявєПкСюЃЌЪзЯШвЊНјааЬиеїВЮЪ§ЬсШЁЃЌВЩгУMelЦЕТЪВЮЪ§зїЮЊCDHMMЕФНЈФЃВЮЪ§ЃЌMelЦЕТЪВЮЪ§ЪЧИљОнШЫЖњЕФЬ§ОѕЬиадНЋгявєаХКХЕФЦЕЦззЊЛЏЮЊЛљгкMelЦЕТЪЕФЗЧЯпадЦЕЦзЃЌШЛКѓзЊЛЛЕНЕЙЦзгђЩЯЁЃ2)дкбЕСЗНзЖЮЃЌЖдВЛЭЌЕФгявєПкСюНЈСЂCDHMMФЃаЭЁЃ3)дкПкСюЪЖБ№НзЖЮЃЌЭЈЙ§ИХТЪЪфГі*ЗжЖдД§ВтгявєПкСюзіГіЪЖБ№ЁЃ 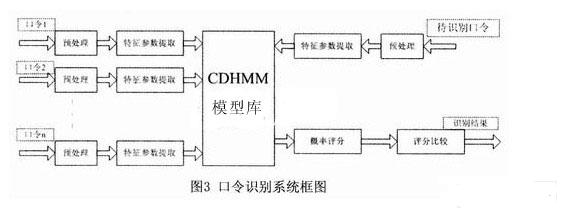 гявєПкСюЪзЯШОЙ§дЄДІРэЃЌЬсШЁMFCCЬиеїВЮЪ§ЃЌШЛКѓНЈСЂДЫПкСюЕФCDHMMФЃаЭЃЌАбЫљгагявєПкСюЕФФЃаЭЗХдкФЃаЭПтжаЃЌдкЪЖБ№НзЖЮЃЌЭЈЙ§ИХТЪЪфГі*ЗжЃЌШЁ*ЗжзюДѓЕФвЛИізїЮЊЪЖБ№ГіЕФПкСюЁЃ 2ЃЎ2 CDHMMЫуЗЈ HMMЪЧвЛжжЫЋжиЫцЛњЙ§ГЬЃЌгУИХТЪЭГМЦЕФЗНЗЈУшЪігявєаХКХЕФВњЩњМАБфЛЏЙ§ГЬЁЃHMMЕФФЃаЭВЮЪ§ЮЊІЫ=(NЃЌMЃЌІаЃЌAЃЌB)ЃЌЦфжаЃЌNЮЊФЃаЭжаТэЖћПЫЗђСДЕФзДЬЌЪ§ФПЃЛMЮЊУПИізДЬЌЖдгІЕФПЩФмЕФЙлВьЪ§ФПЃЛІаЮЊГѕЪМзДЬЌИХТЪЪИСПЃЌІа=(Іа1ЃЌЁЃЌІаN)ЃЛAЮЊзДЬЌзЊвЦОиеѓЃЌA=(aij)N*NЃЛB ЮЊЙлВьИХТЪОиеѓЃЌB=(bjk)N*NЁЃ CDHMMЕФBВЛдйЪЧвЛИіОиеѓЃЌЖјЪЧвЛзщЙлВьжЕИХТЪУмЖШКЏЪ§ЃЌгЩMИіСЌајИпЫЙУмЖШКЏЪ§УшЪіЃК 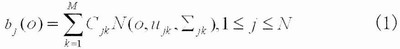 N(oЃЌujkЃЌЁЦjk)ЮЊЖрЮЌИпЫЙИХТЪУмЖШКЏЪ§ЃЌoЪЧЙлВьЪИСПађСаЃЌМДДггявєжаЬсШЁЕФЬиеїЪИСПВЮЪ§(o1ЃЌo2ЃЌЁЃЌot)ЃЌtЮЊЙлВьЪИСПађСаЕФЪБМфГЄЖШЁЃujkЃЌЁЦjkЗжБ№ЮЊИпЫЙЗжВМЕФОљжЕКЭЗНВюВЮЪ§ЃЌCjkЮЊИпЫЙЗжВМЕФШЈжЕЃЌТњзудМЪјЬѕМў 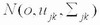 CDHMMВЮЪ§ЙРМЦВЩгУЁАЗжЖЮK-ЦНОљЗЈЁБЁЃГѕЪМФЃаЭПЩвдЫцЛњбЁШЁЃЌгЩ 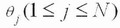 ЪЧИФНјКѓЕФФЃаЭЃЌдйНЋзїЮЊГѕЪМжЕЃЌжиаТЙРМЦЁЃ ЛљгкЁАЗжЖЮK-ЦНОљЗЈЁБЕФCDHMMВЮЪ§ЙРМЦОпЬхЙ§ГЬЮЊЃК (1)ЩшжУФЃаЭВЮЪ§ГѕЪМжЕІЫ=(ІаЃЌAЃЌB)ЁЃ (2)ИљОнДЫІЫгУViterbiЫуЗЈНЋЪфШыЕФбЕСЗгявєЪ§ОнЛЎЗжЮЊзюПЩФмЕФзДЬЌађСаЃЌРћгУзДЬЌађСаЙРМЦВЮЪ§AЁЃ  (3)гУЗжЖЮK-ЦНОљЗЈЖдBНјаажиаТЙРМЦЃЌМДНЋЕкЖўВНЕУЕНЕФУПвЛжжзДЬЌЕФбЕСЗгявєЪ§ОнЫбМЏдквЛЦ№ВЂЖдЦфЬиеїНјааЭГМЦЃЌДгЖјЕУЕНBЁЃ ЖдгкИХТЪУмЖШКЏЪ§гЩШєИЩе§ЬЌЗжВМКЏЪ§ЯпадЯрМгЕФCDHMMЯЕЭГЃЌУПИізДЬЌІШj(1ЁмjЁмN)ЕФИХТЪУмЖШКЏЪ§bj(X)гЩKИіе§ЬЌЗжВМКЏЪ§ЯпадЯрМгЖјГЩЃЌетбљПЩвдАбУПвЛзДЬЌгявєжЁЗжГЩKРрЃЌШЛКѓМЦЫуЭЌвЛРржажюгявєжЁЪИСПXЕФОљжЕЪИСПЃЌЗНВюОиеѓЁЦjkКЭЛьКЯУмЖШКЏЪ§жаИїИХТЪУмЖШКЏЪ§ЕФШЈжиЯЕЪ§ CjkЁЃ  (4)гЩ(2)КЭ(3)ЙРМЦЕФCDHMMВЮЪ§зїЮЊГѕжЕЃЌРћгУжиЙРЙЋЪНЖдCDHMMВЮЪ§НјаажиЙРЃЌЕУЕНВЮЪ§ЁЃ (5)РћгУ(4)ЫљЕУЕФМЦЫуЃЌВЂгыp(OЃЏІЫ)ЯрБШНЯЁЃШчЙћВюжЕаЁгкдЄЖЈЕФуажЕЛђЕќДњДЮЪ§ГЌЙ§дЄЖЈЕФДЮЪ§ЃЌМДЫЕУїФЃаЭВЮЪ§вбОЪеСВЃЌЮоашНјаажиЙРМЦЫуЃЌПЩНЋзїЮЊФЃаЭВЮЪ§ЪфГіЁЃЗДжЎЃЌШєВюжЕГЌГіуажЕЛђЕќДњЮДЕНдЄЖЈЕФДЮЪ§ЃЌдђНЋМЦЫуНсЙћзїЮЊаТЕФГѕжЕЃЌжиИДНјааЯТвЛДЮЕќДњЁЃ 3 НсЪјгя ТлЮФНЈСЂСЫвЛжжЛљгкЧЖШыЪНЯЕЭГЕФгявєПкСюЪЖБ№ЯЕЭГЃЌВЂЧвЖдЩЯЩ§ЁЂЯТНЕЕШ14ЬѕПкСюНјааВтЪдЃЌУПЬѕгявєЯШЧаГ§ОВвєЃЌдЄМгжиЃЌШЛКѓЭЈЙ§ HammingДАЗжжЁДІРэЃЌжЁГЄКЭжЁвЦЗжБ№ЮЊ20msКЭ10msЃЌШЛКѓЖдУПвЛжЁгявєаХКХЬсШЁ16MFCC+16AMFCCЙВ32ЮЌВЮЪ§зїЮЊЬиеїЪИСПЁЃИУгявєПкСюЪЖБ№ЯЕЭГДяЕНСЫЪЕЪБЕФвЊЧѓЃЌПЩвдЪЙгявєПкСюЪЖБ№ЯЕЭГЙуЗКгІгУгкБуаЏЪНЩшБИжаЁЃ |





ЭјгбЦРТл