
如何实现高性能的DSP处理(上)
发布时间:2009-5-13 08:32
发布者:DSP
|
应用开发通常开始于在个人电脑或工作站编写的C原型代码,然后将代码移植到嵌入式处理器中,并加以优化。本系列文章则将这种层面的优化在系统级扩展到包括以下三方面的技术:内存管理,DMA管理,系统中断管理。这些优化措施与程序代码优化同样重要。在大多数系统中,有很多的数据需要传输,并需要很高的数据传输速率。因此,你最终会混合使用处理器中的所有存储器,如内部存储器和外部存储器。 软件架构选择 在开始设计之前,我们必须确定使用什么类型的软件“架构”,所谓架构是在嵌入式系统中搬移程序代码和数据的软件底层结构。由于架构定义了使用多少存储和其他系统资源,因此,架构也影响系统的性能。设计的架构也能反映某些性能特性、是否易于使用,以及其他应用要求。软件架构划分为以下几类:高速实时处理;易编程要求优于对性能的要求;以性能为第一考虑。 第一类高速实时处理架构,对于安全性至关重要的应用程序或没有外部存储器的系统是很理想的。在这种情况下,要么是无法忍受缓冲数据所需的时间,或者是没有相应的系统资源,由于没有外部存储器,故所有工作都需在片内完成。在这种情况下,需要先读取并处理数据,再进行判决,然后删除数据。然而,这里必须保证的是,在当前帧的所有处理完成前正在使用的缓冲数据帧不会被覆盖。 例如,车道偏离系统就是一个安全性至关重要的应用。在这个系统中,通常不能在做出判断前等待33毫秒的全帧数据,更好的做法是处理帧的一部分。例如,您可以从帧末尾处开始检测车道,因此只需读入数据帧末尾部分的数据。 第二种架构通常用在是否易于编程是最重要的考虑因素的情况。这种架构对于需要快速面市的应用,以及需要迅速开发样机和易于编程超过对性能的要求等应用都是十分理想的,它也同样降低了开发难度。 当需要达到系统的最优性能时,第三类架构就是合适的选择。由于重点是性能,所以需要对某些因素,诸如处理器、数据流、带宽效率和优化技术等的选择,做仔细的考虑。然而,这种架构的不足之处在于可复用性和可升级性方面有所降低。 在开发周期中,事先规划好指令和数据流是十分重要的,这也包括对是否需要外部存储器或者缓存做出重要决定。这样,开发人员就可以集中精力利用处理器的结构特点,并调整性能,而不需要重新审视初始设计。 高速缓存概述 高速缓存能够以很快的存取时间(通常是单个周期)将指令和数据存储在处理器片内存储器中。高速缓存的实现是因为减少了系统对单周期访问的存储器资源数量的需求。基于高速缓存的处理器结构,开始时将数据放置在低成本的低速外部存储器中,需要时,高速缓存可自动地将其中的指令和数据传输到处理器的片内存储器。 指令和数据高速缓存为Blackfin处理器核提供了最高带宽的传输路径,但高速缓存存在的问题是它不能预测程序接下来需要的究竟是哪些数据和指令,因此,高速缓存提供了一些功能,使用户可以控制高速缓存的操作。在Blackfin处理器中一些关键的指令段就可以锁定到高速指令缓存中,这样在需要的时候可以直接使用。 值得注意的是,当高速缓存决定需要保留哪些指令时,它会自动保留最近使用最多的指令段。由于DSP软件花费大部分的时间在循环上,这样DSP程序往往会重复访问相同的指令。因此,在不需要任何用户干预情况下,指令高速缓存可以大大提高系统性能。 此外,除了高速指令缓存的功能外,高速数据缓存还提供了“直写”和“回写”模式。在“直写”模式中,在高速缓存中对数据的修改要传送到外部存储器中。总之,编程最好开始采用“回写”模式,可以提高10-15%的效率,在大多数算法中,比“直写”模式更加有效率。如果数据在多种资源中需要共享,由于要维护数据的一致性,因此采用“直写”模式也是有用的。比如,在ADSP-BF561处理器中,要实现两个处理器核数据的共享,则“直写”模式就十分有用。在单核处理器中,如果DMA控制器和高速缓存访问同样的数据,这种模式也是有益的。 利用DMA提升性能 DMA是提高系统性能的另一个有效工具。因为DMA的访问独立于处理器核,处理器核可以专注于处理数据。在理想的配置中,处理器核只需要设置DMA控制器,并在数据传输完毕时响应中断即可。 通常,高速外设和其他大多数外设都具有DMA传输能力。某些DMA控制器也允许外部存储器与内部存储器,以及存储器空间内的数据传递。若设计者仔细地设计系统,将取得巨大的性能提升,因为任何DMA控制器传输的数据都不需要处理器核“操心”。 Blackfin处理器支持二维DMA的传输,如图1所示。左侧显示的是输入缓冲区数据,红、绿、蓝三基色数据交替放置。一维到二维的DMA转换将交替的数据转换成独立的红、绿、蓝数据。图1的左下角为读入数据的伪程序代码。如果没有DMA控制器,这些数据传输就只能由处理器核完成。使用DMA控制器后,则DMA负责数据传输,传输完毕并中断处理器核,处理器核则可解放出来做其他任务,如数据处理等。 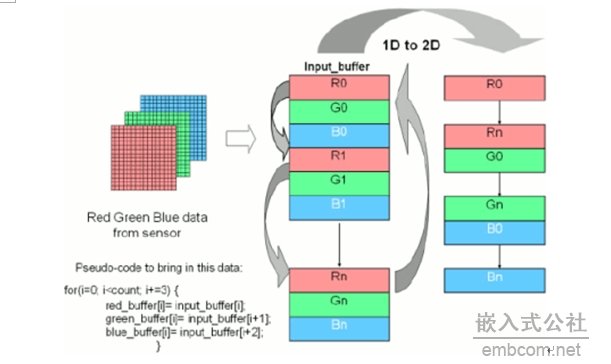 图1:二维DMA存储器访问模式。 DMA也可以与高速缓存联合使用。通常,DMA传输首先将高速外设中的数据读入到处理器的外部存储器,数据高速缓存则将数据从外部存储器读入到处理器内部。进行这种操作通常需要使用“乒乓”缓冲器,一个缓冲区用于数据传输,另一个用于数据处理,图2说明了这种操作方式。DMA控制器将数据传输到buffer0时,处理器核则访问buffer1,反之亦然。 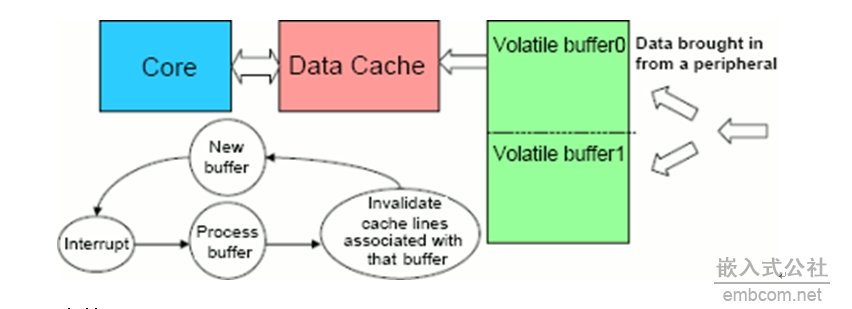 图2:DMA和高速缓存联合使用时数据一致性的维护。 当联合使用DMA和高速缓存时,维持DMA控制器读入的数据与高速缓存中数据的一致性是很重要的,图2说明了如何完成这一操作。当外设生成新的数据,DMA控制器则将数据放置在一个新的缓冲区,并产生中断,通知处理器核可以处理这些数据。当处理器核处理该缓冲区数据前,与该缓冲区相应的高速缓存行被设为无效,从而强制高速缓存从主存储器中取出数据,这样就可以确保一致性。这种方法主要的缺点是它不能达到单一DMA模型的性能,这里DMA控制器采用将缓冲区的数据直接读入内部存储器的模式。 指令划分 指令划分(instructionpartitioning)通常比较简单。如果程序代码能容纳在内部存储器中,只需要关闭指令高速缓存,直接把程序代码映射到内部存储器就可以获得最大的效能。然而,多数应用程序代码不能全部容纳在内部存储器中,所以必须打开高速指令缓存。 高速缓存容量通常小于外部存储器,但这并不是一个问题,因为对于多数嵌入式软件,“通常20%的程序代码的运行时间占整个运行时间的80%”。大多数情况下,最耗时间的程序代码都很小,足够放置到高速缓存中,所以高速缓存器能够充分发挥其作用。 为了提高性能,还可以使用指令的线锁机制(line-lockingmechanism),锁定程序的最关键的部分代码。如需要进一步提高性能,可以关闭指令高速缓存并采用“存储器覆盖”的机制代替,该机制使用DMA将程序代码传输到一个存储器块,而同时在另一个存储器块上执行操作。 数据划分 数据划分通常没有指令划分那么简单。和程序代码划分一样,如果数据缓冲区可以被容纳在内部存储器中,你就没有多余的工作。如果不是,首要任务就是要区分静态数据(如用于查找表)和动态数据。数据高速缓存在静态数据方面使用较好,而DMA通常在动态数据方面性能更佳。 即使使用了数据高速缓存,也通常需要设立一个外设DMA传输通道,将数据从外设传输到外部存储器。如果采用了数据高速缓存,可以将这些数据读入到内部存储器,只要在访问数据前使高速缓存的缓冲区无效即可。如果正在使用DMA,则可以建立DMA传输,将数据从外部存储器读入到内部存储器。 相关阅读:如何实现高性能的DSP处理(下) 供稿:ADI公司 |



网友评论