
TMS320C6000嵌入式系统优化编程的研究
发布时间:2009-4-8 10:45
发布者:李宽
|
本文分析了TMS320C6000的硬件设计和指令系统的特点,结合应用开发过程中遇到的问题,对这种高速并行DSP器件的开发方法进行了总结。 1 TMS320C6000的硬件设计和指令系统 TMS320C6000系列DSP(数字信号处理器)是TI公司最新推出的一种并行处理的数字信号处理器。它是基于TI的VLIW技术的,其中 TMS320C62xx是定点处理器,TMS320C67xx是浮点处理器。本文主要讨论TMS320C6201。该处理器的工作频率最高可以采用 50MHz,经内部4倍频后升至200MHz,每个时钟周期最多可以并行执行8条指令,从而可以实现1600MIPS的定点运算能力,而且完成1024定点FFT的时间只需70μs。 1.1 TMS320C6000的硬件结构 图1是TMS320C6000 CPU的结构图。 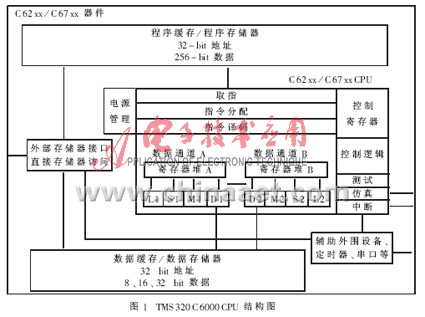 TMS320C6000的CPU有两个数据通道A和B,每个通道有16个32位字长的寄存器(A0~A15,B0~B15),四个功能单元 (L,S,M,D),每个功能单元负责完成一定的算术或者逻辑运算。A、B两通道的寄存器并不是完全共享,只能通过TMS320C6000提供的两个交换数据通道1X、2X,才能实现处理单元从不同通道的寄存器堆那里获取32位字长的操作数。 TMS320C6000的地址线为32位,存储器寻址空间是4G。C6201片内集成有1Mbit SRAM——512Kbit的程序存储器(根据需要可全部配置成Cache)和512Kbit的数据存储器。通过片内的程序存储空间控制器,CPU一次可以取出256bit,即一次最多可以取出8条32位指令。 C6201有32位的外部存储接口EMIF为CPU访问外围设备提供了无缝接口。外围设备可以是同步动态存储器(SDRAM)、同步突发静态存储器(SBSRAM)、静态存储器(SRAM)、只读存储器(ROM),也可以是FIFO寄存器。 为了便于进行多信道数字信号处理,TMS320C6000配备了多信道带缓冲能力的串口McBSP。McBSP的功能非常强大,除具有一般 DSP串口功能之外,还可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同标准。McBSP最多支持128个信道;支持多种数据格式(8 /12/16/20/24/32bit)的传输;可自动进行u律、A律压扩。其工作速率可达到1/2时钟速率。 TMS320C6000提供的16位主机接口(HPI)使得主机设备可以直接访问DSP的存储空间。通过内部或外部存储空间,主机和DSP可以交换信息。主机也可以利用HPI直接访问映射进存储空间的外围设备。 DSP器件一般都带有DMA控制器,可以在CPU操作的后台进行数据传输。TMS320C6201的DMA控制器有4个独立的可编程通道,可以同时进行四个不同的DMA操作,每个通道的优先级可以通过编程设定。每个通道可以根据需要传输8/16/32bit的数据,并且DMA控制器可以访问全部 32位的地址空间。此外,还有一个辅助通道允许DMA控制器响应主机通过HPI口发来的请求。 1.2 指令系统 C62xx和C67xx共享同一个指令集。C67xx可以使用所有的C62xx指令,但因为C67xx是浮点芯片,所以C67xx的指令集中有一些指令只能用于浮点运算。TMS320C6201CPU的设计采用了类似于RISC的结构,指令集简单、运算速度快。8个功能单元负责不同功能的运算, 指令和功能单元之间存在一个映射关系。其中,L单元有23条指令,M单元有20条指令,S单元29有条指令,D单元有26条指令。 TMS320C6201的大部分指令都可在单周期内完成,都可以直接对8/16/32bit数据进行操作。同时,TMS320C6201指令集针对数字信号处理算法提供了一些特殊指令:为复杂计算提供的40bit的特殊操作的加法运算;有效的溢出处理和归一化处理;简洁的位操作功能等。 TMS320C6201中最多可以有8条指令同时并行执行;所有指令均可条件执行。以上所有特点提高了指令的执行效率、减小了代码长度、大大减少了因跳转引起的开销、提高了编码效率。 流水线操作是DSP实现高速度、高效率的关键技术之一。TMS320C6000只有在流水线充分发挥作用的情况下,才能达到1600MIPS的速度。C6000的流水线分为三个阶段:取指、解码、执行,总共11级。和以前的C3x、C54x相比,有非常大的优势,主要表现在:简化了流水线的控制以消除流水线互锁;增加流水线的深度以消除传统流水线结构在取指、数据访问和乘法操作上的瓶颈。其中取指、数据访问分为多个阶段,使得C6000可以高速地访问存储空间。 2 优化编程的几个方法 使用TMS320C6000进行程序设计时,首先的感觉是汇编指令集太小了。C6000在设计时采用了一种类RISC机的结构,运算速度特别快,但是指令集却非常简单。象DSP算法中常用的乘加指令、循环操作指令等,在C54x和C3x中两条指令就可以完成的功能,而在C6000中却需要一个循环体,所以它的程序设计一般比较复杂。要想充分发挥C6000的运算能力,必须从它的硬件结构出发,最大限度地利用八个功能单元,使用软件流水线,尽量让程序无冲突的并行执行。 并行处理的长处在于,在处理彼此之间没有承接关系的运算时,在CPU资源允许的情况下可以并行完成。但对于前后有承接关系或者判断、跳转频繁的情况,就无法发挥并行的优势。一般循环体都满足并行处理的条件,并且循环体往往是程序中耗时最长的地方。因此进行C6000应用开发时应将优化重点放在循环体上。为了降低开发难度,C6000提供了很多在高级语言(如ANSI C)一级对程序进行优化的方法。在应用满足实时性处理要求时,应尽量采用这种方法。但是这种方法的效率比较低,C语言优化最好的例子是点乘,这种循环使用 C语言进行优化可以百分之百地的利用CPU资源,程序的并行性达到最好。但是我们在做20点的点乘时发现它的耗时是汇编语言程序的3倍。所以如果系统的实时性要求比较高,就不能使用这种优化方法了。 这时可以考虑使用线性汇编语言进行开发。线性汇编语言是TMS320C6000中独有的一种编程语言,介于高级语言和低级语言之间。因为在用手写汇编语言进行应用开发时,开发者除了要精通C6000的指令系统之外,还必须为指令分配功能单元、考虑指令的延迟和功能单元之间的配合以及合理分配使用 32个寄存器,才能写出高效的并行指令,发挥C6000的威力。上面任何一个方面出现问题,都会严重影响算法的效率。 线性汇编语言的指令系统和汇编语言的指令系统完全相同,但是它有自己的汇编优化器指令系统,用于和汇编优化器配合使用。与汇编语言的最大区别在于,编写线性汇编语言时不需要考虑指令的延时、寄存器的使用和功能单元的分配,完全可以按照高级语言的方式进行编写。当然由于它不是高级语言,有许多编程的限制。例如,在优化循环体时,不能使用跳转到循环体之外的跳转指令;另外计数器只能使用减计数,如果使用加计数,优化器将不能工作等等。但总的说来,它的代码效率远远高于高级语言,而且开发难度和开发周期比汇编语言要小得多。 在实际开发过程中需要具体情况具体分析,选择一种高效、快捷的开发方法。以下结合应用开发中的几个模块来简述我们使用的优化方法。 2.1 使用汇编语言 使用汇编语言进行并行编程难度比较大。但在有些情况下,程序中数据有非常强的承接关系,并且该程序体逻辑关系清楚,使用的寄存器不超过32个, 这时直接使用汇编语言实现,效率会更高。另外,有些使用C语言比较难实现的运算函数,在C6000的汇编指令集中可能有专用DSP指令,这时就可以直接使用汇编语言实现。 使用汇编语言进行编程时特别需要注意的是C6000指令的延迟情况,有些指令并不是立刻就能得到结果。C6000指令集中有延迟的指令如表1所示。  例1 32位归一化函数norm_l() short norm_l(long L_var1) {short var_out; if (L_var1 == 0L) { var_out = (short)0; } else { if (L_var1 == (long)0xffffffffL) { var_out = (short)31; } else { if (L_var1 < 0L) { L_var1 = *L_var1; } for(var_out=(short)0;L_var1<(long)0x40000000L; var_out++) { L_var1 <<= 1L; }}} return(var_out); } 使用汇编语言进行优化: .global _norm_l _norm_l: B B3 CMPEQ 0,A4,B0 [!B0] NORM A4,A4 NOP 3 消耗时间(时钟周期):C语言norm_l()为723;汇编语言为11。 2.2 使用线性汇编语言重写整个函数 对于某些以循环体为主的函数可以使用线性汇编语言重写整个函数。使用汇编优化器进行优化之后,效率是非常高的。 下面例子是算法中计算帧能量的函数,其中包含两个单循环体。进行优化时,首先要确定循环的次数。对于循环次数是变量的情况,优化器不进行并行优化; 其次尽量减少数据存取次数,例如以32位存取指令对16位数据进行存取,可以节省一半的存取周期。仔细观察C代码,会发现两次循环次数相同。第二个循环要用到第一个循环的结果,因此可以将两个循环合并在一起,这样就避免了在第二个循环中再从存储器中取结果,减少了一半的Load操作。 long Comp_En( short *Dpnt) { int i ; long Rez ; short Temp[60] ; for ( i = 0 ; i < 60 ; i ++) Temp[ i] = shr( Dpnt[ i], (short) 2) ; Rez=(long) 0 ; for (i=0; i <60; i ++) Rez=L_mac(Rez, Temp[ i], Temp[ i]); return Rez ; } 相应的线性汇编程序如下: .global _Comp_En ;函数名定义,对c变量前加__Comp_En .cproc Dpnt;函数头定义,Dpnt是参数 .reg Rez,Rez1,Rez2,I ;寄存器定义,不必考虑实际的寄存器分配 .reg t1,t2,x1,c1,m1,m2 zero Rez zero Rez1 zero Rez2 mv Dpnt,c1 mvk 30,i ;确定循环次数。因为用LDW代替LDH,循环次数减少一半。 loop1 .trip 30 ldw *c1++,x1 shl x1,16,t1 shr t1,2,t1 shr x1,2,t2 ;将两个循环合在一起,又减少了一半的从内存取数据的时间。 smpyh t1,t1,m1 smpyh t2,t2,m2 sadd Rez1,m1,Rez1 sadd Rez2,m2,Rez2 [ i] sub i,1,i ;循环计数器从30递减 [ i] b loop1 sadd Rez1,Rez2,Rez .return Rez .endproc 消耗时间(时钟周期):C语言为32971;线性汇编语言为93。 2.3 使用线性汇编改写复杂函数中的循环体 当函数的逻辑关系复杂,判断、跳转、函数调用情况特别多时,上面方法的效果就会大打折扣。这时可以使用线性汇编将其中的循环部分改写成一个函数,以优化后的函数调用代替循环部分,而不是优化整个复杂函数。 高速数字信号处理器件的应用范围越来越广,特别是在移动通信领域中,软件无线电、智能天线等新技术的实现都需要强大的实时数字信号处理的支持。 TMS320C6000系列DSP完全可以满足此类要求。但目前对于并行DSP技术的软硬件开发还处在摸索阶段,如何充分利用高速DSP的资源,是这方面的研究重点。本文研究了最新推出的TMS320C6000的优化策略,从工程和系统的角度总结出一套既能满足实时性又能保证开发时效性的实用的优化编程方法,以供分飨。 |



网友评论