
Blackfin C语言优化
发布时间:2009-2-28 13:33
发布者:虞美人
|
其实我不是很会写文章,想要把技术性文章写的有意思就更难了。不过这一段日子总是有一种冲动想要写点什么,把自己了解的有关BlackfinC语言优化和系统优化方面的技巧和知识写下来,和正在从事这方面工作朋友们分享,也许有些帮助,也算是对自己过去一段时间工作的总结。 在文章开始之前,我想先问读者一个问题:您的DSP代码里有多少是汇编,这些汇编里有多少是您自己写的? 曾几何时汇编编程是DSP工程师的一张名片。很多人到现在谈起汇编编程还是颇为自豪的,搞得你想说自己不会都要鼓起点勇气——那眼神是恨不得把你送回火星去。这主要是因为在最开始的时候DSP上的C语言编译器不是很普遍,编译器的水平也还在起步阶段,很难用到DSP相应的硬件特性,编译效率值得商榷。而且那时DSP应用场景和复杂度远不比今天,基本上限制在数字信号处理的典型算法上,FFT,FIR,IIR滤波器,等等。这些函数和滤波器的实现相对今天的应用比较简单,用汇编语言也容易突出DSP的硬件特性。还有一个原因是那时候DSP普遍都跑的很慢,基本上在几十兆的水平。这也限制了C语言的使用。试想一下一段C代码跑的比汇编慢十倍,几十兆的DSP一下就变几兆了。 但是今天再来看这所有的一切是完全不一样了。首先是DSP的应用范围越来越广,客户越来越多的希望用同一颗芯片,在同一个平台上实现更多的设计和应用。这对DSP的设计,DSP和MCU的融合都带来重大影响。DSP和MCU之间也不是过往那井水不犯河水的安宁。随着DSP和MCU的主频先后突破1GHz,在很多应用中DSP和MCU相伴相生的场景也开始被一颗强壮的芯代替,或者DSP或者MCU。在这样的应用中,操作系统,文件系统,USB协议栈,TCP/IP,海量数据存储,样样都会用到。数字信号处理也从骨灰级的滤波器变成全系列音视频处理,OFDM基带处理,天线阵列信号处理,彩色图像重建…试想一下这些应用哪一个不是成千上万行代码。汇编语言在编程复杂度,可移植性和可维护性上真的是遇到了前所未有的挑战。而与此相对应的是C语言和C语言编译器的蓬勃发展。今天您可以很容易找到上面提到所有这些应用和算法的C语言实现,而C语言编译器在编译效率和成熟度上都有很大的突破。也让C语言在DSP上的应用得以受到愈来愈高的重视。 但是C语言本身并不是为DSP定义的——C语言在PC上的默认条件在嵌入式处理器上不成立,比方说存储空间无限,比方说内存连续,更不要说如何绑定DSP特殊的硬件支持。所以要充分发挥DSP的能力,C语言优化是一下一张DSP工程师的名片。不会C语言优化,OK,你可以回火星,地球很危险。 1. 拳谱总纲 闲话不表。在深入到细节之前,我想先从宏观的角度讨论一下C语言优化一些大的原则。就好像我们在学七伤拳之前先来背背拳谱总纲,提纲挈领很重要。这些原则可以用图1来说明。 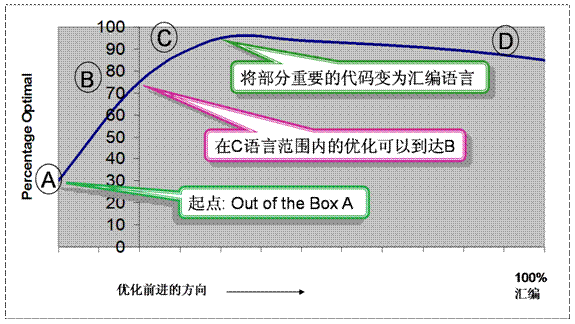 图1:C语言优化性能曲线。 对整条性能曲线可以做这样的总结,1)最佳性能产生在C和汇编按一定比例分配的情况下,80-20可以作为一个参考;2)将所有代码都转为汇编并不会带来性能的进一步提高;3)在C语言编译器的帮助下,将大多数控制代码保留在C语言范畴中是可能的;4)要想达到最佳性能,那些消耗cycle最多的代码应转化为C语言可以调用的汇编函数。简单说就是让C和汇编语言做各自擅长的事情,在动态平衡中达到最佳性能。内事不决问张昭,外事不决问周瑜,各司其职。 在DSP性能大幅提高的今天,如果可以如图中B点那样用Optimized C将C语言在DSP上的性能提高到%70以上,很有可能对于大多数应用场景就已经足够了,并不是一定要接触汇编语言的。这个从A点到B点的过程也正是这篇文章要讨论的重点。 2. 是骡子是马您先别溜 说到这里,有很多朋友等不及要开始做优化了:打开程序,一条语句、一条语句立刻看起来。很多时候我们在工作中都遇到这样的情况,所以第一刻就要喊停,等我先讲讲一些容易被忽略的东西。 首先最容易被忽略的是数据类型。通常编译器对ANSIC所有数据类型都是支持的,但是硬件呢,是不是对所有的数据类型都很有效的支持呢?举个例子,很多DSP都有专门针对16-bit定点运算的指令,特别是一些并行指令。如果在算法中可以将数据类型设计为16-bit就可以充分利用到这些指令。Blackfin每个cycle可以做2个16-bit乘法,而每个32-bit乘法则要消耗3个cycle。这中间有6倍的差距,是值得我们考虑的。另外定点芯片不直接支持浮点操作,如果算法中有浮点类型和浮点运算,则首先应该考虑在不影响动态范围和精度的基础上进行定点化。因为在定点芯片上每个浮点操作都可能消耗成百上千个cycle来得到近似的结果。对于小数类型,Blackfin直接支持1.15和1.31小数类型的操作,这给程序员很大的灵活度。所以我们首先要尽可能依托当前DSP最擅长的操作来确认数据类型被支持的程度,并对算法进行调整。 另一个容易被忽略的地方是算法本身。也就是被采用的算法本身是不是已经是最高效,最优的。考虑一下正在用的排序算法是不是还有余地改进;要用的正弦波形是计算还是查表;又或者整个算法或者部分可以被更高效的算法代替。这样的考虑往往可以达到事半功倍的效果,就好像换了三趟公交去看朋友,下车一抬头发现有条地铁直达。 在现代高性能DSP中通常都有比较深的指令流水线。流水线的作用是把一个cycle里要做的事情分在多个步骤里来做。对于高主频的芯片而言,流水线的深度是很重要的,它从某种程度上决定了可能的最高主频速度。每一个节拍,指令流水线上不同功能单元同时并行运作,每条指令按顺序流经这些功能单元。可惜事物总有两面性,当流水线遇到了条件跳转,它的另外一面就充分暴露出来了。那就是在跳转的时候,当前指令之后已经在流水线里的指令全部都要被清空,然后再让要跳转到的目的指令重新进入流水线。如果流水线的深度是N,那么这里损失的cycle通常为N-1。流水线越深,损失越大。如果不巧这个条件跳转在循环里面,这个N-1的损失就会被放大了。用一些方式替代条件跳转可以减轻这样的损失,比方说尽可能的使用条件执行和条件赋值,或者max和min语句,因为这些语句的执行通常可以在DSP的汇编级找到对应的单周期语句。另外就是要尽可能的避免在循环中使用条件跳转。 除法运算是我们需要注意的一种操作,因为通常除法在DSP中都是一段近似算法来实现的。比如说在Blackfin提供两种除法近似,精度较低的一种需要大约40 cycle而32bit除法则需要大致400cycle。想想一个1000次的for循环里如果有3次除法,您就大致知道您的程序会跑多慢了。所以我们要在算法中考虑到除法的影响和可能的替代方式,例如利用不等式原则可以把除法变成乘法,又或者模2的除法可以变成移位。当然了,我在这里提到的替代,包括针对前面的数据类型,算法和条件跳转,都是遵循“尽可能”的原则,没有绝对的意思。优化的后程序效率的高低就是体现在这个尽可能上。 3. 编译器,睡在上铺的兄弟 这一刻,你不是一个人在战斗…,这话听起来好像有点耳熟。如果把C语言优化比作是程序员在进行的一场战斗的话,程序员并不孤独,因为我们有一个隐形的战友,就是编译器,而编译器的优化功能就是我们最有力的武器。以VisualDSP++为例,通常新建的工程C语言优化缺省是不打开的,程序员可以按照程序运行的需要打开优化。这个从不优化到优化的过程实际上反映了VisualDSP++编译器在处理C语言程序过程中的两步走。 在优化开关没有打开的情况下,编译器对C代码的处理是一一对应的直译,就是把C代码一句一句按照先后顺序翻译为相应的一条或者多条汇编语句。在直译的同时,编译器也会注意到对中间变量和中间结果的保护——不管他们接下来会不会被用到,他们都会被写入存储器,尽管这样做会增加很多冗余。经过这样的直译,一段C代码对应的汇编代码可能是多一个数量级的。一个典型的例子是,只有两条乘累加指令的for循环代码对应的汇编代码是几十条之多。可想而知,这样不经优化的代码执行速度是很慢的。一个参考数据是打开优化开关以后的代码运行速度平均可以提高20倍。也就是说,一个600MHz的芯片,不打开优化,相当于主频降到30MHz。所以绝大多数情况下我们要打开编译器的优化开关。 编译器的第二步走,就是对直译产生的代码进行优化,这个过程就是充分利用DSP的硬件实现指令和事件最大可能并行的过程。这里的并行既有运算单元本身的并行也有运算单元和其他功能单元的并行。以Blackfin为例,每一个core里都有两个乘法器和加法器。编译器在优化的时候第一个层次的并行是运算的并行,就是尽可能同时使用两个运算单元,做乘法就尽可能做到两个乘法器同时运算,做加法就尽可能做到两个加法器同时运算。接下来一个层次的并行是指令的并行,就是运算单元和memory存取、或者其他功能单元之间的并行,仍以Blackfin为例,在同一个cycle中,可以有两个乘累加和两个数据的存或取并发执行。这些并行都是DSP硬件本身支持的,编译器优化的工作就是充分利用DSP的硬件能力。 循环是编译器在第二步走的过程中重点处理的对象。这比较好理解,因为那些大量消耗cycle的代码往往是在循环当中的。下面我就结合编译器对循环的处理,来看看在优化的过程中程序员要怎么和编译器并肩战斗。编译器对循环处理的目标就是希望在每一次循环中尽可能的并行。为了实现这个目标,编译器采取的措施就是不停的打开循环、降低循环次数,增加循环内的指令个数,提高指令之间并发的几率。举个例子,一个100次的循环中有一个乘累加,编译器打开循环,将循环次数降低一半,循环内每次就会出现两个乘累加,编译器就有可能安排Blackfin的两个乘累加单元同时运算,从而将执行的效率提高一倍,这个优化过程叫做矢量化(Vectorization)。如果这个循环中还有加法、减法、存数、取数,或者其他运算,编译器还会安排这些指令和乘累加并发,或者这些指令之间并发,这个优化的过程也是实现软件流水线的过程(SoftwarePipeline)——在优化后的代码中往往出现当前的运算和以往的存数或者未来的取数并行。编译器对循环的打开可能是多次的,直到编译器有足够的指令可以充分安排并发。 说到这里我们对这位睡在上铺的兄弟已经有一些了解了,那么程序员在这个优化的过程中应该做什么呢?这就要从矢量化和软件流水线受到的限制谈起。刚才提到在优化过程中编译器一个重要的操作就是打开循环,如果循环次数是2的N次方例如8,16,32…,编译器就可以很舒服的按照需要多次打开循环。但如果在上面的例子里循环次数是101,编译器是无法打开循环的,对这个循环的优化就不能有效的展开。这个时候就需要程序员做工作了:我们可以将循环里面的运算在循环外实现一次,让循环次数变为100,从而给编译器两次打开循环的机会(2x2x25)。矢量化和软件流水线对操作数的存放也是有要求的。首先,对memory中操作数读取和计算结果存放必须是顺序(地址递增或者递减)的,如果是乱序或者随机的,不管是运算的并行和是指令的并行都很难实现。我们在编写程序和对C程序进行优化的时候就要注意到尽可能安排数据访问的顺序性。其次,根据操作数的宽度,程序员还要注意保证数据的2字对齐或者4字对齐。这有助于在指令并行执行时对操作时的有效读取。程序员可以通过在定义数据(组)的时候用编译器提供的相应编译选项来实现数据的对齐。在进行矢量化和软件流水线的过程中往往要对程序执行的顺序做局部调整,这种调整对程序整体来说虽然是微调,但在某些情况下改变原始程序执行的顺序会影响到程序执行结果的正确性。最典型的情况就是运算的操作数和结果之间存在某种联系和依赖。比方说数组中靠后的成员数值取决于靠前的成员运算的结果,这意味着数组成员之间有依赖性,不独立,从而不能实现并行计算。这在for循环中经常体现为一个运算的两个操作数指针可能是指向同一个数组的不同位置。数据独立性是到目前位置我们看到影响客户C代码优化效率最严重的因素。 编译器在进行优化的时候永远都遵循一个基本原则,那就是优化不能影响程序运行的正确性。所以当编译器发现矢量化和软件流水线需要满足的那些条件不确定的时候,它的行为往往是保守的。这是一种宁可放弃性能也要保证正确性的态度,无可厚非。该出手时就出手,到了程序员帮编译器一把的时候了。因为编译器面对的这些不确定性,在程序员看来通常是确定,一定,以及肯定的。以前面数据独立性的问题为例,编译器很难判断当前for循环中两个指针pa,pb在运行的时候是不是会指向同一个数组,因为对编译器来说它们只是两个指针,对它们后面实际操作的对象毫无头绪。而程序员却可能清楚的知道这段程序处理的两个数组是定义在两段不同的物理内存上的,也就是说这两个指针不会指向同一段地址,数据的独立性是有保证的。这个时候我们就可以通过相应的编译选项通知编译器:下面这个for循环里的数据是独立的,放心大胆的优化吧。这里提到的编译选项,包括前面说的关于循环次数,数据对齐,以及存储位置等其他编译选项都可以在VisualDSP++关于C语言编译器的手册中找到。 了解了编译器的工作方式,针对矢量化和软件流水线对代码和数据存储的要求,在C语言范围内对相关代码进行调整,并通过编译选项将有利于优化的确定信息通知编译器,依托C语言编译器的能力实现代码的高效优化,就是程序员在这里要做的工作。 4. 打完收工,还是刚刚开始 我们已经简单的谈了C语言优化,特别是性能曲线从A点到B点应该遵循的主旨和一些技巧。个人认为,嵌入式系统上高效的C代码优化不是在代码写好以后才开始的一个独立的步骤,而应该是在系统设计和编写代码的时候就已经开始考虑硬件平台有效执行的因素,妥善安排算法,精度,数据类型,存储空间和性能之间的关系。再加上灵活应用上面提到的技巧,可以做到事半功倍。由于篇幅的限制,这里只能提纲挈领的讲一讲。有兴趣的读者可以访问http://www.analog.com/zh/embedde ... ng/fca.html#ADEV001 到此为止,C语言优化告一段落,而嵌入式系统的优化才刚刚开始。片内片外代码和数据的分配,主频和外频的选择,系统带宽和DMA的使用,这些都会影响到优化后的代码在嵌入式系统里最终的性能。火星人的地球之旅,才刚刚开始。 |
网友评论