
基于超大规模FPGA的FFT设计与实现
发布时间:2009-5-27 16:29
发布者:FPGA
|
在宽带数字接收机中,需要对接收机输出的零中频信号进行实时的谱分析,因此FFT的高速实现一直是宽带数字接收机的重要研究内容之一,而以DSP为代表的数字信号处理芯片的应用使得FFT的运行效率产生了质的飞跃,而超大规模FPGA的应用更是极大地提高了FFT的实现速度,这是由于当今最先进的FPGA芯片内部集成了大量乘法器和存储资源,其内部规模达到千万门量级,总线速度接近550 MHz,这些可编程硬件资源为FFT的高速实现提供了可能。 参考文献[1]论述了一种基于FPGA的FFT实现方法,在系统时钟为100MHz时,采用Xilinx公司Vertex-IIPro完成1 024点复数FFT运算仅需要2.56μs,但由于系统时钟速度较低,输入输出数据的速度较慢。参考文献[3]论述了基于FPGA的FFT算法实现,其设计的1024点复数基4-FFT处理器在100 MHz的主时钟频率下运算速度为51.29μs,其速度同样不能满足宽带数字接收机实时谱分析的要求。基于此,本文论述了一种基于单片FPGA的高速FFT设计与实现技术。 Virtex-IV SX 芯片中集成了XtremeDSPSlice,支持40多个动态控制的操作模式,包括乘法器、乘法器-累加器、乘法器-加法器/减法器,三输入加法器、桶形移位器、宽总线多路复用器或宽计数器,可以独立达到500 MHz的性能,或整列组合在一起以实现DSP功能。本系统即选用了XC4VSX55芯片,在单片FPGA上完成了2048点的FFT高速运算。 1 基4-FFT算法简介 系统需要对于2 048点实序列完成FFT实时处理,这里选用基4-FFT算法。基4-FFT共需log4N=r次迭代运算,每次迭代包含N/4个碟形单元,基4-蝶形运算单元见图1。  2 频域抽取基4-FFT的FPGA设计与实现 2.1总体实现结构设计 在得到1 024点复数序列的FFT结果后,再进行一级蝶形运算就可得到2048点实序列的FFT,这种算法减小了每一级蝶形运算的数据量,提高了整个FFT运算的工作频率。1024点复序列的基4-FFT共需5级蝶形运算,每一级需256个蝶形运算单元,再加上1级结果转换单元和1级求模值运算单元,完整的2048点实序列的基4-FFT共需7级运算,考虑到频域抽取基4-FFT算法的特点,本文采用级间顺序运算、级内并行加流水的实现结构。总体实现结构框图如图2所示。 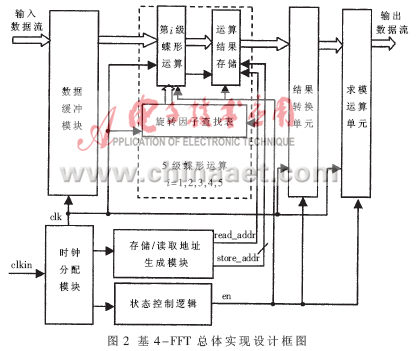 系统实现流程为:首先,数据缓冲模块暂存输入数据流,并进行必要排序处理,然后,状态控制逻辑单元启动蝶形运算,第i级蝶形运算利用第i-1级的输出结果和对应的旋转因子完成本级蝶形运算,把运算结果存储到对应的存储单元中,第i级运算完成后,使能第i+1级运算,以此类推,经过5级蝶形运算,就可以得到1 024点复序列的FFT结果,运算结果经数据转换单元就可以得到2048点实序列的FFT结果;时钟分配模块把输入时钟进行缓冲、分频、调理等处理,为各级运算单元、存储单元提供同步时钟,状态控制逻辑单元完成各级运算单元之间的转换控制功能。 2.2 数据存储单元设计 依据频域抽取基4-FFT算法的要求,输入数据是顺序输入的,设由实序列组合得到的1024点复序列为X(0)、X(1)、…、X(N-1),数据缓冲模块把该序列分成4组进行缓冲存储,具体为:数据X(0)、X(4)、…、X(1020)为第1组;X(1)、X(5)、…、X(1 021)为第2组;X(2)、X(6)、…、X(1022)为第3组;X(3)、X(7)、…、X(1023)为第4组,4组数据分别顺序存储于双端口RAM中(DPRAM1(0)、DPRAM2(0)、DPRAM3(0)、DPRAM4(0)),产生的存储地址为st_addr(i+1)=st_addr(i)+1,存储器的存储深度为256。输入数据的存储结构如表1所示。  依据基4-FFT算法的运算规则,第1级蝶形运算的数据量为4,即输入数据量、输出数据量都为4。对于1024点复序列,参与第1级蝶形运算的4个数据分别为X(i)、X(i+256)、X(i+512)、X(i+768),i=0,1,…,255,可以看出,第1级蝶形运算单元的输入数据可以分别从DPRAM1(0)、DPRAM2(0)、DPRAM3(0)及DPRMA4(0)读取,而不会出现交叉读取数据的现象,这样,可以方便地采用4个蝶形运算单元并行工作模式,从而提高工作速度。 记第1级蝶形运算的输出数据为X(i),i=0,1,…,255,其中,每个X(i)为一次蝶形运算结果,包括4个元素。把第1级运算的输出数据分成4组,分别顺序存储于4个双端口RAM中(DPRAM1(1)、DPRAM2(1)、DPRAM3(1)及DPRAM4(1)),存储地址也是顺序产生的,即st_addr(i+1)=st_addr(i)+1,第1级蝶形运算输出结果的存储结构如表2所示。 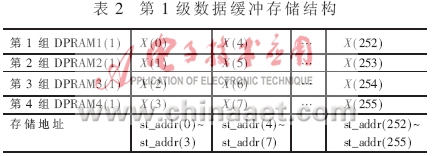 第2级蝶形运算的数据量为16,具体描述为:把数据组X(i)、X(i+64)、X(i+128)及X(i+192)分成一组,记为第i组,其中,i=0,1,…,63,运算时,从这4个数据组中依次读取对应元素作为蝶形运算单元的输入数据,例如,分别取X(i)、X(i+64)、X(i+128)及X(i+192)中的第1个元素作为一次蝶形运算的输入数据,依次类推。第2级蝶形运算的输出数据记作X(i,i),i=0,1,…,63,每个X(i,i)是第i组数据的运算结果,包含16个元素;该级蝶形运算的输出数据也分成4组,分别顺序存储于DPRAM1(2)、DPRAM2(2)、DPRAM3(2)及DPRMA4(2),其存储结构如表3所示。  第3级蝶形运算单元的数据量为64,把数据组X(i,i)、X(i+16,i+16)、X(i+32,i+32)及X(i+48,i+48)作为第i组数据,其中,i=0,1,…,15,运算时,从数据组X(i,i)、X(i+16,i+16)、X(i+32,i+32)及X(i+48,i+48)中依次取对应元素作为该级蝶形运算单元的输入数据。第3级蝶形运算的输出数据记为X(i,i,i),i=0,1,…,15,每个X(i,i,i)是第i组数据的运算结果,包含64个元素;该级蝶形运算的输出数据分成4组,分别顺序存储于DPRAM1(3)、DPRAM2(3)、DPRAM3(3)及DPRMA4(3),其存储结构如表4所示。  第4级蝶形运算的数据量为256,把数据组X(i,i,i)、X(i+4,i+4,i+4)、X(i+8,i+8,i+8)及X(i+12,i+12,i+12)分成一组,作为第i组数据,其中,i=0,1,…,15。运算时,从数据组X(i,i,i)、X(i+4,i+4,i+4)、X(i+8,i+8,i+8)及X(i+12,i+12,i+12)中依次取对应元素作为该级蝶形运算单元的输入数据。第4级蝶形运算的输出数据量记为X(i,i,i,i),i=0,1,2,3,每个X(i,i,i,i)有256个元素。把该级蝶形运算的输出数据分成4组,分别顺序存储于DPRAM1(4)、DPRAM2(4)、DPRAM3(4)及DPRMA4(4),其存储结构如表5所示。  第5级蝶形运算的数据量为1024,从数据组X(0,0,0)、X(1,1,1,1)、X(2,2,2,2)及X(3,3,3,3)中依次读取对应数据作为该级蝶形运算单元的输入数据。该级蝶形运算的输出数据量为1 024,也分成4组顺序存储于DPRAM1(5)、DPRAM2(5)、DPRAM3(5)、DPRAM4(5)。 2.3 流水结构的蝶形运算单元设计 本设计的基4-蝶形运算单元采用串行输入/输出、并行运算的结构,其中,串行输入/输出数据流是由时钟信号clk1控制的,而内部并行运算是由时钟信号clk2控制的,clk2是clk1四分频后的结果。同时,设计采用增加流水级的办法进一步提高运算速度,复数乘运算采用全并行结构实现,共需2级流水,整个蝶形运算共需6级流水,第1级是4个串行输入数据缓冲,第2、3级是复数乘,第4、5级是两级加减运算,第6级是4个输出结果在时钟clk1控制下串行输出。图3是蝶形运算单元的实现框图,图4是复数乘运算的并行实现框图。  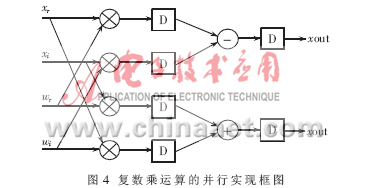 2.4 状态控制单元设计 状态控制单元主要完成每级运算之间的状态转换功能,产生相应的使能信号。根据前面的分析,2048点实序列的基4-FFT共需要5级蝶形运算、一级数据转换和求模值运算和一级数据读出单元,这样,整个基4-FFT功能模块共需7个状态,分别用stage1~stage7来表示,设计采样有限状态机加以实现,产生的控制使能信号分别为butter1_cal_en、butter2_cal_en、butter3_cal_en、butter4_cal_en、butter5_cal_en、change_en及read_en,每个状态对应于一级蝶形运算,实现的具体功能包括:使上一级存储器的读出使能信号有效,使本级蝶形运算单元和本级存储器的存储使能信号有效。状态控制单元的Modelsim仿真结果如图5所示。  3 基4-FFT模块的性能分析 3.1资源消耗及运算速度估计 按照本文设计,每个复数乘法器消耗4个硬件乘法器、而每个蝶形运算单元有3个复数乘法器,这样,每个蝶形运算单元共消耗12个硬件乘法器。并在设计时,根据数据存储结构特点,各级运算采用4个蝶形运算单元并行工作的方式,另外,数据转换单元的蝶形运算包含1个复数乘法器,也采用4路并行工作方式,由于第1级蝶形运算不需要复数乘法运算,所以,整个FFT模块共消耗3×4×12+12+4×4=172个硬件乘法器资源;本文设计的基4-FFT模块共需6个状态来完成,每个状态对应一级蝶形运算,每级蝶形运算消耗的总时间包括数据读出时间和流水延时时间两部分。这样,第1级蝶形运算共需256+4×4=272个clk时钟,第2、3、4级蝶形运算共需3×(256+6×4)=840个clk时钟,第5级需要256+4=260个clk时钟,这样,整个FFT模块共需要1 370个clk时钟周期完成,在clk频率为300 MHz时,完成FFT运算共需4.57 μs。 3.2 实现结果 本文利用单片FPGA实现2 048点FFT计算,采用实际信号数据注入实验验证,注入单点频信号并加入高斯白噪声时,信噪比SNR=0dB,图6(a)是FFT模块的输出结果,可以看出,输出结果将在归一化频率100和其镜像频率1948位置产生两个峰值点;注入3个点频加入高斯白噪声,SNR=0 dB,图6(b)是FFT模块的输出结果。 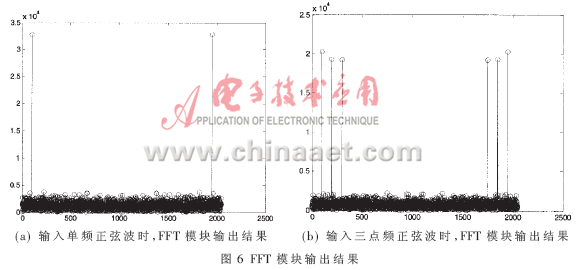 本文针对高速数字接收机频谱实时估计的需求,设计了基于Xilinx的Virtex-IV系列的XC4VSX55芯片的FFT算法设计并实现,实测结果与计算机仿真结果一致。可见随着总线速度可达550MHz的Virtex-V的出现及更加丰富的资源置于片内,使得全并行结构的实现成为可能,为FFT的高速实现与应用提供了更有效的手段。 |




网友评论