
高阶累积量在欠定盲源分离中信源数目估计的应用
发布时间:2010-8-18 16:21
发布者:lavida
|
盲源信号分离(Blind Source Separation,BSS)是指从观测到的多源混合信号中分离并恢复出相对独立的源信号过程。因为对源信号及混合过程知之甚少,无法直接观测得到混合信号中的有用信息,只有通过盲信号处理手段将它们从混合信号中分离出来,才能实现对所需信号的提取。由于该技术具有在相对宽松的条件实现有用信号的恢复等能力,使之在信号处理领域受到越来越多的关注,并已广泛应用于通信、语音处理、地震勘探、生物医学、图像处理、雷达以及经济数据分析等领域。 通常的盲源分离算法都不具备对未知信号源个数进行估计的能力,只能在假设信号源的个数已经事先确定的前提下才能进行计算。因此在处理过程中源数目估计对盲分离技术的发展具有重要意义,也是目前必须予以解决的问题。目前有关通信侦查中盲分离源数目估计的专门研究尚不多见,本文研究优化了一种基于累积量算法的源数估计算法,可在无先验知识的情况下估计出欠定条件下信号源个数。 1 信号模型和问题描述 盲源信号分离理论中,混合过程分为线性瞬时混合模型与卷积混合模型两类。对源信号统计性质的要求还与所采用的盲分离算法有关。本文着重讨论线性混合盲信号分离问题情况下信号源数目估计。 存在n个来自信号源的统计独立n维的信号矢量s1(t),s2(t),…,sn(t),通过m×n的混合矩阵A,线性瞬时混合后得到的m个观测信号x1(t),x2(t),…,xm(t)。 信号模型为:  式中:aij是混合矩阵系数;ni为随机观测噪声;矢量和矩阵表达式为: 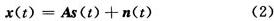 式中:n为m×1噪声矢量。该模型与标准阵列信号处理的观测信号模型相似,但在盲信号分离中,信号的混合系数并没有类似阵列信号模型中的波达方向角等先验信息可以利用。 因此信号源盲分离问题可以描述为计算一个n×m的分离矩阵W,使其输出y(t)=Wx(t)为对s(t)的一个估计。由于上式中的混合矩阵A和s(t)都未知,因此无法精确辨识源信号各分量的排列顺序和能量,这即是盲信号分离问题存在的不确定性问题,一是排列顺序的不确定性,即无法了解所抽取的信号应是s(t)中的哪一个分量;二是信号幅度的不确定性,即无法恢复信号波形的真实幅值。由于信息主要包含在信号的波形中,所以这两种不确定性并不影响盲分离技术的应用。但信号源盲分离的大多数实际问题中,不仅信号源的波形未知,其数目也是未知的。这就无法确定分离矩阵W的维数,从而使计算根本无法进行。故在进行盲分离前,须对信号源数目进行估计。 目前常用的源信号个数估计方法多是基于观测信号y(t)的协方差矩阵特征分解,易得观测信号y(t)的协方差矩阵为: 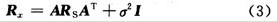 式中:Rs表示源信号的协方差矩阵,记协方差矩阵Rx特征值为λ1≥λ2≥…≥λn。由于A列满秩,ARSAT的秩等于k,Rx的特征分解后得到k个按降序排列的主特征值Λs=diag(λ1,λ2,…,λk)和(m-k)均等于σ2的噪声特征值Λn=diag(λk+1,λk+2,…,λn)=σ2。信源个数就等于k,即m减去相同的最小特征值的个数,仅由观察其最小特征值重复出现次数就可以确定源信号个数。但是通常观测信号y(t)的协方差矩阵是未知的,当Rx由一组观测向量估计得到时,Rx的特征值各不相同的概率几乎为1,当信噪比比较低时,就很难通过仅观察特征值来估计源信号个数。 Wax M和Kailath T提出应用信息论中模型AIC和MDL准则估计源信号个数,上述准则都是在标准阵列信号处理中,基于观测信号均服从高斯分布这一基本假设推导得到的,在标准阵列信号处理模型而源信号非高斯的情形下,H T Wu等给出了源信号个数的启发性GDE估计,许多国内学者也提出很多新的算法。传统的盲源分离算法都假设观测信号数目大于或者等于源信号数目,然而在一些实际应用中会发生观测信号数目小于源信号数目的情况,称为欠定盲源分离,即过完备盲源分离。由于混合系统是欠定的,此时混合系统不再可逆,从而不能简单地通过对混合矩阵求逆得到源信号。因为在混合过程中有信息丢失,即使混合矩阵A已知,也不能完全恢复出信号的独立成分。 2 基于高阶累积量的盲信号信源数目估计算法 2.1 四阶累积量的定义 在实际问题中,一阶和二阶统计量并不能完全描述信号的统计特性,采用高阶统计量的形式不仅可以获得比二阶统计量更好的性能,而且可以解决二阶统计量不能解决的很多问题。四阶统计量的重要特点是对任何形式下高斯过程的不敏感性,并且在数学形式有很多好的性质,这是二阶矩所不具备的,因此可以有效地从高斯过程中提取出非高斯信号或抑制高斯噪声。这点对于未知谱特性的高斯噪声情况显得尤其重要。由于基于高阶累积量的相关算法对高斯噪声嚏盲的,不仅在白高斯噪声下能正确估计信号源个数,而且对色高斯噪声和相关高斯噪声均能有效地抑制,仍能给出一致性的估计。 对于给定随机变量x1,x2,x3,x4零均值实随机变量,定义其四阶累计量:  2.2 累积量扩展矩阵的构造 在欠定条件下,传统信源数目估计方法完全失效,通过利用四阶累积量的阵列孔径扩展特性,构造适当的四阶累积量矩阵,对协方差矩阵进行扩展,使源信号个数的信息包含于该矩阵中,以估计出多于观测信号数目的非高斯信号源,借以提高估计算法的性能,突破子空间类算法对入射信号数的限制。 构造的累积量扩维矩阵可以用Kronecker乘积表示,易得实信号模型: 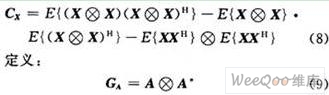 则新信号模型易得:  新的混合矩阵中系数位置和原有混合矩阵的位置十分类似,但构成的新矩阵仍然能保持原有信号的独立性,满足盲信号分离的基本条件。N个信源,M个通道,M>N,则对GX特征分解后,得到N2大特征值和M2-N2个小特征值。 2.3 算法提出 通过结合高阶累积量优化过程研究cum-奇异值算法。根据项目条件,在双通道条件下进行盲源数目的估计。计算过程如下: 设有n个信号(独立)经过m个通道混合: (1)采集数据x=[x1(n),x2(n),…,xm(n)]T; (2)通过高阶累积优化构造的四阶累积量矩阵CX; (3)对CX运用cum-奇异值算法得到m2个特征值,并将这些特征值从大到小排列σ1≥σ2≥…≥σm; (4)主特征值数εδ=k0+1,k0的取值为εδ=γ(kmax)的值,γk=σk+1/σk+2即所求信号源个数。 3 仿真实验 采用2通道3源信号的欠定条件下情形进行仿真实验,仿真根据项目背景选取的两组三个独立信号源分别为AM,FM,BPSK为第一组信号;BPSK,QAM,LFM为第二组信号。其中,AM,FM的载频为20 MHz,带宽10 MHz;BPSK和QAM信号的载频为20 MHz,码速率为5 MHz;线性调频信号的初始频率为20 MHz,带宽为20 MHz。 3.1 实验一:信源估计算法性能随混合信号SNR变化的图表 任取500点数据,SNR线性变化范围为-10~10 dB,步长为1 dB,每个SNR点做100次蒙特卡洛仿真。目标个数估计正确率如图1所示,在欠定条件下优化后,cum-奇异值算法不仅可以估计信源个数,而且随SNR的递增,正确估计的概率不断增大,但同其他经典算法相比,仍然是用时最短的最稳定算法。图2为第二组信号的正确估计概率。可以看出,该各个算法的性能均明显有所下降,说明对于不同的信号模型,算法的性能有所不同。盲分离中信源数目估计对模型信号具有一定的要求,不同的混合信号在不同的SNR下正确估计的概率有很大的区别,而通用的方法则不是很多。 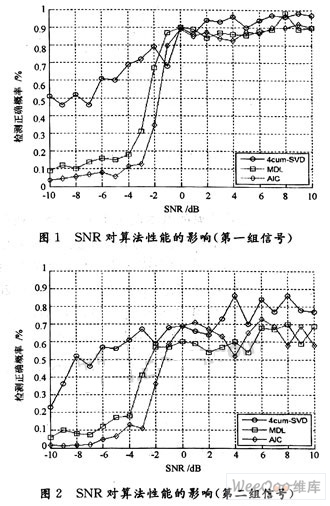 3.2 实验二:信源估计算法性能随混合信号采样点数变化的图表 仿真在SNR为8 dB下,数据长度从50~450递增,步长为50,每个点做100次蒙特卡洛仿真。如图3所示,四阶累积量SVD算法在小样本条件下性能突出,具有比AIC,MDL算法更高的正确率。但随快拍数逐渐增加,基于信息论的算法性能开始好转。图4说明在同等实验条件下,不同的信源组合,带来不同的算法性能。 4 结语 本文从盲信号分离的基本假设出发,研究了通信侦查中双通道盲信号个数的估计方法,通过借鉴阵列信号处理理论,证明了欠定条件下高阶累积量优化流程可以应用在信源数目估计的问题,并分别讨论了信噪比和采样点数这两个参数的变化对优化后算法性能的影响。结果表明,在不同的信号混合情况下,信源算法估计的性能会不同,因为受信源模型、传播环境等多个因素的影响,会造成性能下降。有关信号模型的多样性和信源估计算法的局限性及更多数目的情况还有待深入研究,解决方法在后续的修正算法中探讨解决。 |





网友评论