博客
块设备驱动(3)
|
在操作系统中块是文件系统最小寻址单位,而扇区是最小物理单位。 块设备由于其操作IO速度很慢,故而为了加快其操作速度需要将一个基本块读取到内存中将其缓存起来;当需要读取块设备某一扇区时先查找该扇区是否被缓存,若被缓存则直接读取缓存,反之则读取扇区。这样进过缓存后可以大大加快IO操作速度。 一个块不能超过页大小,但可包含一个或多个扇区,所以一个页可以包含多个块。每个块缓冲区由缓冲区头和相应的缓冲页面来描述。
??struct buffer_head {
?? unsigned long b_state;//状态标志
?? struct buffer_head *b_this_page;//页面中的缓冲区链表
?? struct page *b_page;//存储缓冲区的页面
?? atomic_t b_count; //计数
?? u32 b_size;//块大小
?? sector_t b_blocknr;//逻辑块号
?? char *b_data;//页面中的缓冲区
?? struct block_device *b_bdev;//该缓冲对应的块设备
?? bh_end_io_t *b_end_io;//io完成调用函数
?? void *b_private;//完成函数参数
?? struct list_head b_assoc_buffers; //相关的映射链表
??};但是由于操作的不便性该表述已经在2.6内核中被bio结构体所取代。
??
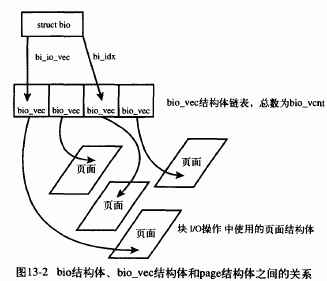
?? 在通用层或更底层,结构bio是IO的主要单位,结构bio使用bio_vec描述io缓冲。一次大的IO操作,数据通过bio_vec结构的链表传递到驱动程序。 bio向量结构描述io缓冲,代表一个片段,其结构如下:
??struct bio_vec {
?? struct page *bv_page;//缓冲所在页面
?? unsigned int bv_len;//缓冲大小
?? unsigned int bv_offset;//缓冲到页面起始处的偏移值
??};即缓冲所在的范围是page_to_phy(bv_page)+bv_offset -----page_to_phy(bv_page)+bv_offset+bv_len.
??
??struct bio {
?? sector_t bi_sector;//待传递的一个扇区
?? struct bio *bi_next; //下个
?? struct block_device *bi_bdev;//目标设备
?? unsigned long bi_flags; //状态命令
?? unsigned long bi_rw;//低位表示读写,高位表示优先级
??
?? unsigned short bi_vcnt;//io缓冲数量
?? unsigned short bi_idx;//当前数组的序号
??
?? unsigned short bi_phys_segments;//物理地址合并后的片段数
?? unsigned short bi_hw_segments;//DMA映射后的片段数
??
?? unsigned int bi_size;//总字节大小
?? unsigned int bi_hw_front_size;//
?? unsigned int bi_hw_back_size;//
??
?? unsigned int bi_max_vecs;//最大缓冲数
?? struct bio_vec *bi_io_vec;//指向实际的bio_vec链表即缓冲池首地址
?? bio_end_io_t *bi_end_io;//完成整个bio的IO后调用函数
?? atomic_t bi_cnt;// 计数
??
?? void *bi_private;//
??
?? bio_destructor_t *bi_destructor;//销毁函数
??};
??下列用图形来示意申请 申请队列 bio 以及块io缓存的联系关系:
? ? ??
struct biovec_slab {
int nr_vecs;
char *name;
kmem_cache_t *slab;
};该结构体将bio_vec不同数量组成slab对象便于管理。
#define BV(x) { .nr_vecs = x, .name = "biovec-"__stringify(x) }
static struct biovec_slab bvec_slabs[BIOVEC_NR_POOLS] __read_mostly = {
BV(1), BV(4), BV(16), BV(64), BV(128), BV(BIO_MAX_PAGES),
};
#undef BV
该结构体用于为bio和bio_vec分配内存池
struct bio_set {
mempool_t *bio_pool;//bio结构体的内存池
mempool_t *bvec_pools[BIOVEC_NR_POOLS];//bio_vec结构体的内存池
};??
init_bio函数用于建立和分配bvec_slabs中的slab对象,以及为bio和bio_vec建立内存池??
static int __init init_bio(void)//bio初始化
{
int megabytes, bvec_pool_entries;
int scale = BIOVEC_NR_POOLS;//定义对象池数量
bio_slab = kmem_cache_create("bio", sizeof(struct bio), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);//建立bio的以bio_slab为首地址slab池
biovec_init_slabs();//为bvec_slabs数组的6个biovec_slab成员建立slab缓存
megabytes = nr_free_pages() >> (20 - PAGE_SHIFT);//将所有空闲页换成多少M字节单位
//依据空闲内存大小对池的规模进行限制
if (megabytes <= 16)
scale = 0;
else if (megabytes <= 32)
scale = 1;
else if (megabytes <= 64)
scale = 2;
else if (megabytes <= 96)
scale = 3;
else if (megabytes <= 128)
scale = 4;
bvec_pool_entries = megabytes * 2;//确定池中元素数量
if (bvec_pool_entries > 256)
bvec_pool_entries = 256;//1M最多只能有256个bio_vec
fs_bio_set = bioset_create(BIO_POOL_SIZE, bvec_pool_entries, scale);
if (!fs_bio_set)
panic("bio: can't allocate bios\n");
bio_split_pool = mempool_create(BIO_SPLIT_ENTRIES,
bio_pair_alloc, bio_pair_free, NULL);//创建split内存池
if (!bio_split_pool)
panic("bio: can't create split pool\n");
return 0;
}??
??
static void __init biovec_init_slabs(void)
{
int i;
for (i = 0; i < BIOVEC_NR_POOLS; i++) {
int size;
struct biovec_slab *bvs = bvec_slabs + i;
size = bvs->nr_vecs * sizeof(struct bio_vec);
bvs->slab = kmem_cache_create(bvs->name, size, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
}//为bvec_slabs数组的6个biovec_slab成员建立slab缓存
}
??
struct bio_set *bioset_create(int bio_pool_size, int bvec_pool_size, int scale)
{
struct bio_set *bs = kmalloc(sizeof(*bs), GFP_KERNEL);
if (!bs)
return NULL;
memset(bs, 0, sizeof(*bs));
bs->bio_pool = mempool_create(bio_pool_size, mempool_alloc_slab,
mempool_free_slab, bio_slab);//为bio建立内存池
if (!bs->bio_pool)
goto bad;
if (!biovec_create_pools(bs, bvec_pool_size, scale))//为bio_vec建立内存池
return bs;
bad:
bioset_free(bs);
return NULL;
}??
??
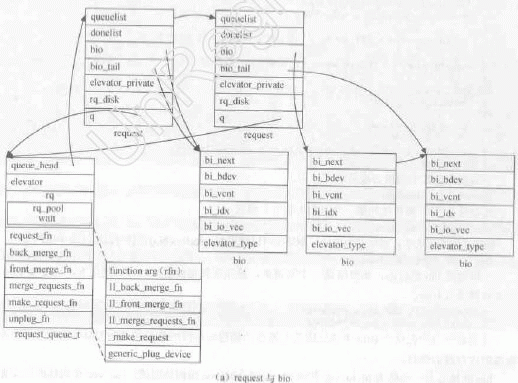
当系统对块设备进行读写操作时,它仅仅通过读写操作函数将一个请求发送给对应的设备,并保存在该设备的操作请求队列中,然后调用这个设备的底层处理函数,对请求队列中的操作进行逐一的执行。系统会把一部分内存最为块设备驱动程序与文件系统接口之间的一层缓冲区,每个缓冲区与某台块设备中的特定区域相联系。当访问文件时,文件系统首先在相应的缓冲区查找,如未找到就向该设备发出IO读写请求,有设备驱动程序对这些请求进行处理。
??blk_init_queue函数为一个设备建立一个请求队列来处理请求,如下:
request_queue_t *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)
{
return blk_init_queue_node(rfn, lock, -1);
}
request_queue_t *
blk_init_queue_node(request_fn_proc *rfn, spinlock_t *lock, int node_id)
{
request_queue_t *q = blk_alloc_queue_node(GFP_KERNEL, node_id);//从池中分配一个队列对象
if (!q)
return NULL;
q->node = node_id;
if (blk_init_free_list(q))//初始化读写等待队列头,并建立内存池
goto out_init;
if (!lock) {
spin_lock_init(&q->__queue_lock);
lock = &q->__queue_lock;
}
q->request_fn = rfn;//请求处理函数
q->back_merge_fn = ll_back_merge_fn;//请求块加入到末端
q->front_merge_fn = ll_front_merge_fn;//请求块加入到前端
q->merge_requests_fn = ll_merge_requests_fn;//是否可合并两个连续的请求块
q->prep_rq_fn = NULL;
q->unplug_fn = generic_unplug_device;//去掉堵塞函数
q->queue_flags = (1 << QUEUE_FLAG_CLUSTER);
q->queue_lock = lock;
blk_queue_segment_boundary(q, 0xffffffff);//设定请求片段的边界为4G
blk_queue_make_request(q, __make_request);//绑定制造申请函数到队列
blk_queue_max_segment_size(q, MAX_SEGMENT_SIZE);//设定最大片段尺寸
blk_queue_max_hw_segments(q, MAX_HW_SEGMENTS);
blk_queue_max_phys_segments(q, MAX_PHYS_SEGMENTS);
if (!elevator_init(q, NULL)) {//有关调度器的处理
blk_queue_congestion_threshold(q);
return q;
}
blk_cleanup_queue(q);
out_init:
kmem_cache_free(requestq_cachep, q);
return NULL;
}
对于有机械设备的块设备需要使用调度器来调整磁头,故而需要使用申请队列头来调度处理申请。而非机械块设备如flash sd ramdisk等不需调整磁头所以其直接使用制造申请函数。
文件系统同步文件时的块缓存提交函数submit_bh,直接IO操作中的提交函数dio_bio_submit,节点或块设备映射的数据回时提交函数mpage_bio_submit和内存页IO操作函数swap_writepage等最终调用了块层的函数submit_bio.该函数很复杂,等以后学习内核时再分析。?
??struct buffer_head {
?? unsigned long b_state;//状态标志
?? struct buffer_head *b_this_page;//页面中的缓冲区链表
?? struct page *b_page;//存储缓冲区的页面
?? atomic_t b_count; //计数
?? u32 b_size;//块大小
?? sector_t b_blocknr;//逻辑块号
?? char *b_data;//页面中的缓冲区
?? struct block_device *b_bdev;//该缓冲对应的块设备
?? bh_end_io_t *b_end_io;//io完成调用函数
?? void *b_private;//完成函数参数
?? struct list_head b_assoc_buffers; //相关的映射链表
??};但是由于操作的不便性该表述已经在2.6内核中被bio结构体所取代。
??
?? 在通用层或更底层,结构bio是IO的主要单位,结构bio使用bio_vec描述io缓冲。一次大的IO操作,数据通过bio_vec结构的链表传递到驱动程序。 bio向量结构描述io缓冲,代表一个片段,其结构如下:
??struct bio_vec {
?? struct page *bv_page;//缓冲所在页面
?? unsigned int bv_len;//缓冲大小
?? unsigned int bv_offset;//缓冲到页面起始处的偏移值
??};即缓冲所在的范围是page_to_phy(bv_page)+bv_offset -----page_to_phy(bv_page)+bv_offset+bv_len.
??
??struct bio {
?? sector_t bi_sector;//待传递的一个扇区
?? struct bio *bi_next; //下个
?? struct block_device *bi_bdev;//目标设备
?? unsigned long bi_flags; //状态命令
?? unsigned long bi_rw;//低位表示读写,高位表示优先级
??
?? unsigned short bi_vcnt;//io缓冲数量
?? unsigned short bi_idx;//当前数组的序号
??
?? unsigned short bi_phys_segments;//物理地址合并后的片段数
?? unsigned short bi_hw_segments;//DMA映射后的片段数
??
?? unsigned int bi_size;//总字节大小
?? unsigned int bi_hw_front_size;//
?? unsigned int bi_hw_back_size;//
??
?? unsigned int bi_max_vecs;//最大缓冲数
?? struct bio_vec *bi_io_vec;//指向实际的bio_vec链表即缓冲池首地址
?? bio_end_io_t *bi_end_io;//完成整个bio的IO后调用函数
?? atomic_t bi_cnt;// 计数
??
?? void *bi_private;//
??
?? bio_destructor_t *bi_destructor;//销毁函数
??};
??下列用图形来示意申请 申请队列 bio 以及块io缓存的联系关系:
? ? ??
struct biovec_slab {
int nr_vecs;
char *name;
kmem_cache_t *slab;
};该结构体将bio_vec不同数量组成slab对象便于管理。
#define BV(x) { .nr_vecs = x, .name = "biovec-"__stringify(x) }
static struct biovec_slab bvec_slabs[BIOVEC_NR_POOLS] __read_mostly = {
BV(1), BV(4), BV(16), BV(64), BV(128), BV(BIO_MAX_PAGES),
};
#undef BV
该结构体用于为bio和bio_vec分配内存池
struct bio_set {
mempool_t *bio_pool;//bio结构体的内存池
mempool_t *bvec_pools[BIOVEC_NR_POOLS];//bio_vec结构体的内存池
};??
init_bio函数用于建立和分配bvec_slabs中的slab对象,以及为bio和bio_vec建立内存池??
static int __init init_bio(void)//bio初始化
{
int megabytes, bvec_pool_entries;
int scale = BIOVEC_NR_POOLS;//定义对象池数量
bio_slab = kmem_cache_create("bio", sizeof(struct bio), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);//建立bio的以bio_slab为首地址slab池
biovec_init_slabs();//为bvec_slabs数组的6个biovec_slab成员建立slab缓存
megabytes = nr_free_pages() >> (20 - PAGE_SHIFT);//将所有空闲页换成多少M字节单位
//依据空闲内存大小对池的规模进行限制
if (megabytes <= 16)
scale = 0;
else if (megabytes <= 32)
scale = 1;
else if (megabytes <= 64)
scale = 2;
else if (megabytes <= 96)
scale = 3;
else if (megabytes <= 128)
scale = 4;
bvec_pool_entries = megabytes * 2;//确定池中元素数量
if (bvec_pool_entries > 256)
bvec_pool_entries = 256;//1M最多只能有256个bio_vec
fs_bio_set = bioset_create(BIO_POOL_SIZE, bvec_pool_entries, scale);
if (!fs_bio_set)
panic("bio: can't allocate bios\n");
bio_split_pool = mempool_create(BIO_SPLIT_ENTRIES,
bio_pair_alloc, bio_pair_free, NULL);//创建split内存池
if (!bio_split_pool)
panic("bio: can't create split pool\n");
return 0;
}??
??
static void __init biovec_init_slabs(void)
{
int i;
for (i = 0; i < BIOVEC_NR_POOLS; i++) {
int size;
struct biovec_slab *bvs = bvec_slabs + i;
size = bvs->nr_vecs * sizeof(struct bio_vec);
bvs->slab = kmem_cache_create(bvs->name, size, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
}//为bvec_slabs数组的6个biovec_slab成员建立slab缓存
}
??
struct bio_set *bioset_create(int bio_pool_size, int bvec_pool_size, int scale)
{
struct bio_set *bs = kmalloc(sizeof(*bs), GFP_KERNEL);
if (!bs)
return NULL;
memset(bs, 0, sizeof(*bs));
bs->bio_pool = mempool_create(bio_pool_size, mempool_alloc_slab,
mempool_free_slab, bio_slab);//为bio建立内存池
if (!bs->bio_pool)
goto bad;
if (!biovec_create_pools(bs, bvec_pool_size, scale))//为bio_vec建立内存池
return bs;
bad:
bioset_free(bs);
return NULL;
}??
??
当系统对块设备进行读写操作时,它仅仅通过读写操作函数将一个请求发送给对应的设备,并保存在该设备的操作请求队列中,然后调用这个设备的底层处理函数,对请求队列中的操作进行逐一的执行。系统会把一部分内存最为块设备驱动程序与文件系统接口之间的一层缓冲区,每个缓冲区与某台块设备中的特定区域相联系。当访问文件时,文件系统首先在相应的缓冲区查找,如未找到就向该设备发出IO读写请求,有设备驱动程序对这些请求进行处理。
??blk_init_queue函数为一个设备建立一个请求队列来处理请求,如下:
request_queue_t *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)
{
return blk_init_queue_node(rfn, lock, -1);
}
request_queue_t *
blk_init_queue_node(request_fn_proc *rfn, spinlock_t *lock, int node_id)
{
request_queue_t *q = blk_alloc_queue_node(GFP_KERNEL, node_id);//从池中分配一个队列对象
if (!q)
return NULL;
q->node = node_id;
if (blk_init_free_list(q))//初始化读写等待队列头,并建立内存池
goto out_init;
if (!lock) {
spin_lock_init(&q->__queue_lock);
lock = &q->__queue_lock;
}
q->request_fn = rfn;//请求处理函数
q->back_merge_fn = ll_back_merge_fn;//请求块加入到末端
q->front_merge_fn = ll_front_merge_fn;//请求块加入到前端
q->merge_requests_fn = ll_merge_requests_fn;//是否可合并两个连续的请求块
q->prep_rq_fn = NULL;
q->unplug_fn = generic_unplug_device;//去掉堵塞函数
q->queue_flags = (1 << QUEUE_FLAG_CLUSTER);
q->queue_lock = lock;
blk_queue_segment_boundary(q, 0xffffffff);//设定请求片段的边界为4G
blk_queue_make_request(q, __make_request);//绑定制造申请函数到队列
blk_queue_max_segment_size(q, MAX_SEGMENT_SIZE);//设定最大片段尺寸
blk_queue_max_hw_segments(q, MAX_HW_SEGMENTS);
blk_queue_max_phys_segments(q, MAX_PHYS_SEGMENTS);
if (!elevator_init(q, NULL)) {//有关调度器的处理
blk_queue_congestion_threshold(q);
return q;
}
blk_cleanup_queue(q);
out_init:
kmem_cache_free(requestq_cachep, q);
return NULL;
}
对于有机械设备的块设备需要使用调度器来调整磁头,故而需要使用申请队列头来调度处理申请。而非机械块设备如flash sd ramdisk等不需调整磁头所以其直接使用制造申请函数。
文件系统同步文件时的块缓存提交函数submit_bh,直接IO操作中的提交函数dio_bio_submit,节点或块设备映射的数据回时提交函数mpage_bio_submit和内存页IO操作函数swap_writepage等最终调用了块层的函数submit_bio.该函数很复杂,等以后学习内核时再分析。?




