
基于ADSP TS201的雷达信号处理机设计
发布时间:2011-1-29 17:41
发布者:conniede
|
现代雷达信号处理已成为雷达功能实现的关键,本文根据某型雷达信号处理机的系统需要,对其硬件结构及软件设计做了系统优化。设计了1套以4片TS201和1片FPGA为核心信号处理板,该系统仅用l副板卡即实现空时二维信号处理。实现了自适应副瓣相消,4路脉冲压缩与MTI/MTD,副瓣匿影和差波束测角等算法,可以完成对目标距离,方位偏差量的测算,满足系统需求。 1 系统组成分析 回波信号在天线上进行部分微波合成,形成和、差通道信号及两路辅助天线信号,进行IQ正交插值,1/8抽取后,形成4路待测数据,数据率共为128MB/s。系统算法结构,如图1所示,主要由旁瓣相消模块,数字脉压模块,MTD处理模块由3部分组成。和路信号MTD(FFT-CFAR)后经副瓣匿影若判定有目标则再由和、差两路数据计算方位偏差量。  以雷达工作的低重频模式为例,IQ数据为5 388点,重频为140 Hz,考虑到一定的时间余量,4路信号的传输及处理必须在<6.7 ms的时间内完成。因此系统的数据速率、数据量及运算规模决定了系统设计必须具有以下特点: (1)具有高性能浮点处理芯片,可完成旁瓣相消、脉冲压缩、相参积累、杂波图、恒虚警处理。 (2)内部各处理芯片间可进行高速数据传递且可外部扩展存储芯片,保存大量数据。 (3)具备对外的数据接口和控制接口,并可输出故障检测信号。 (4)软件设计中必须进行大量优化,保证上述所有处理模块在1个脉冲周期内完成。 2 雷达处理机实现 2.1 硬件平台设计 系统运算量及时间要求,信号处理板需采用多DSP并行处理的结构,为达到高速浮点处理能力、高数据吞吐率及大内存空间的要求,DSP芯片选用ADSP-TS201,它是ADI公司最新型号的TigerSHARC架构高性能浮点数字信号处理器。它具有最高达600 MHz的工作时钟,且每周期可完成4条指令;包括双独立运算模块及用于地址计算的双独立整型ALU,可完全并行操作;拥有24 MB/s的片内存储器,内存容量大;此外还有14路DMA控制器及外部端口、4个链路口,可进行高速数据吞吐;拥有4个SDRAM控制器,可外部扩展存储芯片;拥有4个可编程flag引脚,可对外输出所需标志信号。 多DSP设计通常有共享总线方式和链路口耦合方式两种结构。共享总线结构的优点是可以提供全局地址空间,把多DSP的地址空间映射到主机的内存空间进行统一访问。任一DSP也可通过总线读写其它处理器内存,操作方便。然而,当多DSP间数据交换频繁时,总线竞争往往造成数据通信的总线瓶颈,因而该方法有明显的缺点。采用链路口耦合方式则具有明显的优点,各DSP总线独立,拥有完全独立的内存空间,各DSP程序设计可完全独立,减小了程序调试的难度。各DSP之间仅通过链路口无缝连接,片间连线少,降低了PCB布线难度和层数,节约了制板成本。此外,数据传输采用链路口的DMA方式并不占用DSP内核的运算时间,可以提高处理板的实时性能。因而采用将4片ADSP-TS201通过链路口两两互连,形成松耦合的多DSP结构,如图2所示。各DSP通过链路口可在任意两个DSP之间进行最高达500 MB/s的数据传输。 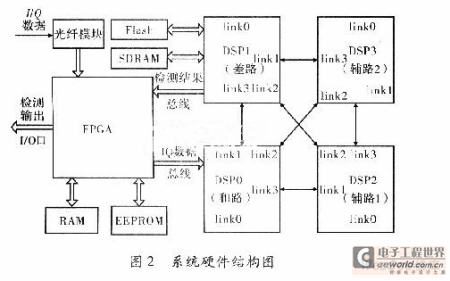 板卡主要以4片TS201与1片FPGA为核心,外加FLASH,SDRAM与光纤及其配置芯片协同完成数据存储及传输。FPGA主要完成系统中与雷达匹配的时序控制,对板外的数据传输与对DSP的总线通信。FPGA通过两套独立的32位外部数据总线与DSP0和DSP1连接,采用流水协议,外部总线工作频率为50 MHz,可以实现400 MB/s的数据传输速度,达到了系统可进行高速数据传输的要求。系统时钟为50 MHz,TS201经12倍频工作在600 MHz,单板卡的系统峰值处理能力可以达到14.4 Gflops,板卡运算速度满足了系统需求。 2.2 系统软件设计及优化 系统算法的复杂性与计算中的动态范围的要求,系统算法在DSP中软件化设计,调试方便。回波经微波合成后形成和、差路及两路辅助通道信号,A/D采样正交差值后形成4路数据经光纤传入FPGA,DSP0经总线以DMA方式接收4路数据,并分发至其它3片DSP。各DSP单独处理一路数据,如图2所示,MTD后回传至DSP1进行副瓣匿影及门限检测,并估算目标方位偏差量,检测结果由DSP1经总线以DMA方式返还至FPGA,所有的模块限制在1个脉冲周期内完成,形成了图3的软件流程图。 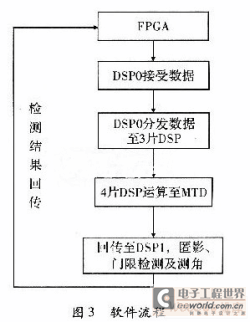 (1)数字脉冲压缩。 系统中采用频域方法实现脉冲压缩。其基本原理是先对回波信号做FFT得其频谱S(ω),将S(ω)与匹配滤波器频谱H(ω)频域点乘,最后对乘积结果做IFFT即得脉压结果Y(n),整个过程由两次FFT,一组频域点乘,及一次IFFT运算组成,由下式表示 Y(n)=IFFT{FFT[s(n)]*FFT[h(n)]} (1) 1)针对TS201芯片内存量大的特点,将H(ω)直接存入DSP内存,以H(ω)所需内存换取了一次FFT执行时间。 2)脉冲压缩结果是否乘以N对后续处理无实质影响。 故IFFT的实现省略了除以N的操作,在此基础上DSP中可由两种方法实现:一种是通过改变旋转因子中正弦项的符号,调用FFT函数实现,运算速度与FFT完全一致,但保存新的旋转因子多耗费了一倍内存;另外一种则为实虚交换后做FFT,再实虚交换即实现IFF-T,该方法优点是不占用新的内存。这里在DSP程序中对第二种方法稍加改进可使处理时间与FFT完全一致:在频域点乘中结果输出时完成第一次实虚反序不占用额外指令,稍后中可看出在MTD模块中稍加改动可使脉压输出的实虚顺序并不引起系统指令的增加。原脉冲压缩处理时间为:经改进后处理时间可缩短为。内核时钟工作在600 MHz时,1 024,4 096,8 192点的频域脉压时间42.24μs、272.63μs、632.1μs,远小于脉冲重复后期,保证了系统功能的实现。 (2)MTD模块实现 相参积累技术进一步提高了系统信噪比,使雷达在各种杂波背景下的目标检测能力提高。MTD模块用16点FFT实现,由于设计中脉冲压缩输出为先虚后实,故需对时域抽取的16点FFT第一级蝶形运算稍作修改,使对保存+j寄存器的操作与对保存re寄存器的操作互换,执行时间可与原16点FFT完全一致。 DSP1还需处理杂波图,正常视频检测,测角等,内存消耗大,因此占用部分SDRAM空间辅助存放了8周期的脉压结果,数据传输量为5388×2×8=86 208,数据量较大,因此MTD模块的主要实现难点是数据传输时间问题。 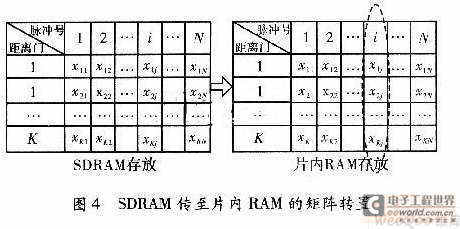 MTD是对同一距离单元上的脉压数据进行处理,因此要求在DMA传输的过程中实现矩阵行列转置,8个脉冲周期的数据量已经超出了普通一维DMA传输方式的上限,且若在SDRAM中跳址传输,遭遇频繁的跨页寻址时会耗费更多时间。采用二维DMA传输方式,通过改变TCB配置使DMA传输在SDRAM中连续寻址,而在DSP端接收地址自动跳变,在矩阵传输的同时实现行列转置。系统时钟为50 MHz,传输时间为86 208/50=1.73 ms,DMA传输方式无需消耗内核时钟,占用总线时间仅为1.73 ms,满足了传输时间的要求。 经MTD后和路信号经副瓣匿影及门限检测后判定有目标,则差路信号在相同距离门上按滤波器号选取对应多普勒通道的处理结果,按式(2)查找误差曲线完成和差波束测角 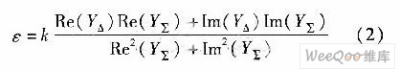 式中,Y△为差路信号数据;Y∑为和路信号数据;k为一常数;ε为所求方位误差角。回波的脉压结果,正常视频输出,MTD检测结果,目标方位角误差角均按距离波门顺序由FPGA返还至伺服系统,控制相控阵天线调整波束指向对准目标。 3 结束语 本文以4片ADSP-TS201与1片FPGA为核心实现了信号处理系统。该系统对硬件结构和程序流程进行了优化设计,单板卡完成了信号处理,系统硬件结构简单、程序易调试、整体可靠性高,对处理机的系统更新具有现实意义。 |





网友评论