
«Ε»κ Ϋ Β ±”Δ”ο”ο“τ Ε±πœΒΆ≥ΒΡ…ηΦΤΚΆ Βœ÷
ΖΔ≤Φ ±ΦδΘΚ2010-12-22 20:26
ΖΔ≤Φ’ΏΘΚconniede
|
ΥφΉ≈“ΤΕ·…η±ΗΒΡΩλΥΌΖΔ’ΙΘ§Τ»«––η“Σ“Μ÷÷Ηϋ”―ΚΟΓΔΗϋ±ψΫίΒΡ”ΟΜß≤ΌΉςœΒΆ≥ΓΘΉ‘Ε·”ο“τ Ε±πœΒΆ≥ΡήΙΜΧαΙ©±ψάϊΒΡ»ΥΜζΫΜΜΞΘ§ΫΪ≥…ΈΣ“Μ÷÷÷ς“ΣΖΫΖ®ΓΘΡΩ«ΑΘ§ Β―ι “ΜΖΨ≥÷–Ή‘Ε·”ο“τ Ε±πœΒΆ≥“―Ψ≠»ΓΒΟΝΥΚήΚΟΒΡ–ßΙϊΘ§ΒΪ–η“ΣΚή¥σΒΡ¥φ¥ΔΩ’ΦδΚΆ‘ΥΥψΉ ‘¥ΓΘΒ±Ή‘Ε·”ο“τ Ε±π”Π”Ο”Ύ“ΤΕ·…η±Η ±Θ§±Ί–κΕ‘ΡΘ–ΆΚΆ Ε±π≤Ώ¬‘Ϋχ––œύ”ΠΗΡΫχΘ§≤≈Ρή¬ζΉψΤδΕ‘‘ΥΥψΥΌΕ»ΓΔΡΎ¥φΉ ‘¥ΚΆΙΠΚΡΒΡ“Σ«σΓΘΈΣΝΥΫβΨω’βΗωΈ ΧβΘ§±ΨΈΡΫΪΫαΚœ”Δ”ο”ο“τΒΡΧΊΒψ,…ηΦΤ≤Δ Βœ÷«Ε»κ Ϋ”Δ”ο”ο“τ Ε±πœΒΆ≥Θ§Άξ≥…÷–Β»¥ ΜψΝΩΒΡΙ¬ΝΔ¥ Β ± Ε±π»ΈΈώΓΘ 1 ”≤ΦΰΤΫΧ® «Ε»κ ΫœΒΆ≥ΒΡ»μ”≤ΦΰΗΏΕ»ΫαΚœΘ§’κΕ‘œΒΆ≥ΒΡΧΊΕ®»ΈΈώΘ§“ΣΝΩΧε≤Ο“¬ΓΔ»Ξ≥ΐ»Ώ”ύΘ§ ΙΒΟœΒΆ≥ΡήΙΜ‘ΎΗΏ–‘ΡήΓΔΗΏ–߬ ΓΔΗΏΈ»Ε®–‘ΒΡΆ§ ±Θ§±Θ÷ΛΒΆ≥…±ΨΚΆΒΆΙΠΚΡΓΘ“ρ¥ΥΘ§œΒΆ≥”≤ΦΰΤΫΧ®ΒΡ―Γ”Ο «”ΑœλœΒΆ≥’ϊΧε–‘ΡήΒΡΙΊΦϋ“ρΥΊΓΘœΒΆ≥≤…”ΟInfineonΙΪΥΨUnispeech 80D51”ο“τ¥ΠάμΉ®”Ο–ΨΤ§ΉςΈΣΚΥ–ΡΒΡ”≤ΦΰΤΫΧ®Θ§ΗΟ–ΨΤ§Φ·≥…ΝΥ“ΜΗω16ΈΜΕ®ΒψDSPΚΥ(OAK)ΓΔ“ΜΗω8ΈΜMCUΚΥ(M8051 E-Warp)ΓΔΝΫ¬ΖADCΓΔΝΫ¬ΖDACΓΔ104KBΒΡSRAM“‘ΦΑΗΏΝιΜν–‘ΒΡMMUΒ»ΤςΦΰΓΘΤδ÷–DSPΉνΗΏΙΛΉςΤΒ¬ Ω…¥ο100MHzΘ§MCUΉνΗΏΙΛΉςΤΒ¬ ΈΣ50MHzΓΘ ”…”ΎœΒΆ≥ΒΡ”ο“τ¥ΠάμΉ®”Ο–ΨΤ§UniSpeechΦ·≥…ΝΥ¥σ≤ΩΖ÷ΒΡΙΠΡήΒΞ‘ΣΘ§Τ§ΆβΥυ–η‘ΣΦΰΚή…ΌΘ§“ρ¥ΥœΒΆ≥”≤ΦΰΤΫΧ®ΒΡΑεΦΕΫαΙΙΖ«≥ΘΦρΒΞΓΘΆΦ1ΈΣ”≤ΦΰΤΫΧ®ΒΡΑεΦΕΫαΙΙΆΦΓΘ 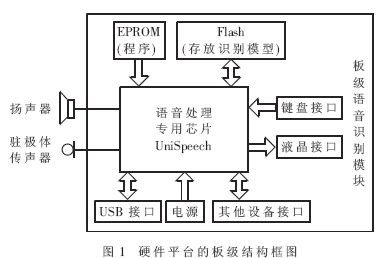 Ή®”Ο–ΨΤ§÷Μ–ηΆβΫ”ΘΚ (1)EPROMΘΚ¥φΖ≈œΒΆ≥≥Χ–ρΘΜ (2)Flash MemoryΘΚ¥φΖ≈”ο“τ Ε±πœΒΆ≥–η“ΣΒΡ…υ―ßΡΘ–Ά≤Έ ΐΚΆœΒΆ≥÷–ΒΡ”ο“τΧα ΨΓΔ”ο“τΜΊΖ≈ ΐΨίΘΜ (3)”ο“τ δ»κΤςΦΰΘΚΩ…÷±Ϋ”ΆβΫ”¬σΩΥΖγΘ§Ϋ” ’”ο“τ–≈Κ≈ΘΜ (4)”ο“τ δ≥ωΤςΦΰΘΚΩ…÷±Ϋ”ΆβΫ”―ο…υΤςΜρΕζΜζΘ§ δ≥ωœΒΆ≥ΒΡΧα Ψ“τΘΜ (5)Βγ‘¥ΘΚΆ®ΙΐΒγ―Ι±δΜΜ–ΨΤ§Θ§ΈΣΒγ¬ΖΑε…œΗς–ΨΤ§ΧαΙ©–η“ΣΒΡΒγ―ΙΘΜ (6)USBΫ”ΩΎΘΚΗΟΑεΦΕ”ο“τ Ε±πΡΘΩιΧαΙ©ΝΥUSBΫ”ΩΎΘ§“‘ΧαΗΏΗΟ«Ε»κ ΫœΒΆ≥ΚΆΆ®”ΟΦΤΥψΜζœΒΆ≥÷°Φδ ΐΨίΫΜΜΜΒΡΥΌΕ»ΘΜ (7)Φϋ≈ΧΘΚΧαΙ©ΆβΫ”Φϋ≈ΧΫ”ΩΎΘ§ΖΫ±ψœΒΆ≥ΩΊ÷ΤΘΜ (8)“ΚΨßΘΚΩ…ΆβΫ”“ΜΩι“ΚΨßœ‘ ΨΤΝΘ§“‘ δ≥ω Ε±πΫαΙϊΘΜ (9)ΤδΥϊ…η±ΗΫ”ΩΎΘΚΈΣΝΥ‘ω«ΩΗΟ”ο“τ–≈Κ≈¥ΠάμΡΘΩιΒΡΙΠΡήά©’Ι–‘Θ§UniSpeechΧαΙ©ΝΥΖαΗΜΒΡI/OΉ ‘¥Θ§Ι≤”–100ΧθΆ®”ΟI/OΘ§œΒΆ≥“≤‘ΛΝτΝΥ’β–©I/OΫ”ΩΎΘ§“‘ΖΫ±ψ”κΤδΥϊ…η±ΗΝ§Ϋ”ΓΘ 2 ΥψΖ®―–ΨΩ 2.1 ΝΫΫΉΕΈ Ε±πΥψΖ® ‘Ύ”Δ”ο”ο“τ Ε±πœΒΆ≥÷–Θ§≥Θ”ΟΒΡ…υ―ßΡΘ–ΆΜυ±ΨΒΞ‘Σ «ΒΞ¥ Θ®WordΘ©ΓΔ…œœ¬ΈΡΈόΙΊ“τΥΊΘ®MonophoneΘ©ΓΔ…œœ¬ΈΡœύΙΊ“τΥΊΘ®TriphoneΘ§BiphoneΘ©ΚΆ“τΫΎΘ®SyllableΘ©ΓΘΒΞ¥ ΡΘ–Ά”…”ΎΤδΝιΜν–‘ΧΪ≤νΦΑΦΤΥψ ±ΦδΚΆ’Φ”ΟΡΎ¥φΥφ¥ΐ Ε±πΒΞ¥ ΐΒΡ‘ωΦ”ΕχœΏ–‘‘ω≥ΛΘ§Υυ“‘‘Ύ«Ε»κ Ϋ”ο“τ Ε±πœΒΆ≥÷–Κή…Ό”Π”ΟΓΘMonophoneΡΘ–ΆΨΏ”–ΡΘ–ΆΦρΒΞΓΔΉ¥Χ§ ΐΫœ…ΌΓΔ Ε±πΥΌΕ»ΩλΓΔΡΎ¥φ’Φ”Ο…Ό«“”κ Ε±π¥ ΜψΝΩΈόΙΊΒ»”≈ΒψΘ§ΒΪΤδΕ‘ΖΔ“τΒΡœύΙΊ–‘Οη ω≤ΜΙΜΨΪ»ΖΘ§“Μ―Γ Ε±π¬ ≤ΜΗΏΓΘTriphoneΚΆSyllableΡΘ–ΆΕ‘ΖΔ“τœύΙΊ–‘ΡήΉΦ»ΖΫ®ΡΘΘ§ΒΪΡΘ–Ά ΐΝΩΨό¥σΓΔΉ¥Χ§ ΐΫœΕύΓΔ Ε±πΥΌΕ»¬ΐΓΔΡΎ¥φ’Φ”ΟΕύΓΘΈΣΝΥΫβΨωΡΎ¥φ’Φ”ΟΝΩ”κ Ε±πΥΌΕ»÷°ΦδΒΡΟ§ΕήΘ§±ΨΈΡ≤…”ΟΝΥΝΫΫΉΕΈΥ―ΥςΥψΖ®Θ§ΤδΜυ±ΨΝς≥Χ»γΆΦ2Υυ ΨΓΘ 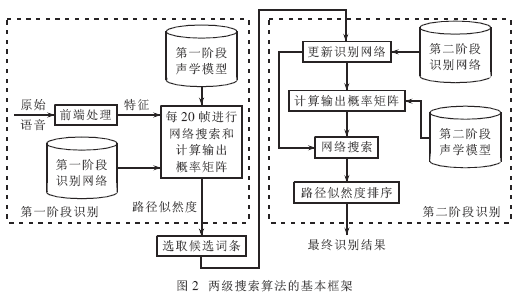 ‘ΎΒΎ“ΜΫΉΕΈ Ε±π÷–Θ§≤…”ΟmonophoneΡΘ–ΆΚΆΨ≤Χ§ Ε±πΆχ¬γΘ§ΒΟΒΫΕύΚρ―Γ¥ ΧθΘΜ‘ΎΒΎΕΰΫΉΕΈ Ε±π÷–Θ§ΗυΨίΒΎ“ΜΫΉΕΈ δ≥ωΒΡΕύΚρ―Γ¥ ΧθΘ§ΙΙΫ®–¬ΒΡ Ε±πΆχ¬γΘ§≤…”ΟtriphoneΡΘ–ΆΘ§Ϋχ––ΨΪ»Ζ Ε±πΘ§ΒΟΒΫΉν÷’ΒΡ Ε±πΫαΙϊΓΘ”…”ΎΒΎΕΰΫΉΕΈ Ε±πΒΡ¥ Χθ ΐΫœ…ΌΘ§”κ÷Μ≤…”ΟtriphoneΡΘ–ΆΒΡ“ΜΫΉΕΈ Ε±πœύ±»Θ§ Ε±πΥΌΕ»¥σ¥σΧαΗΏΘΜΆ§ ±Θ§ΒΎΕΰΫΉΕΈ Ε±πΩ…÷Ί”ΟΒΎ“ΜΫΉΕΈΒΡΡΎ¥φΉ ‘¥Θ§“≤Φθ…ΌΝΥ Ε±πœΒΆ≥ΒΡΡΎ¥φ’Φ”ΟΝΩΓΘ 2.2 ΧΊ’ςΧα»Γ”κ―Γ‘ώ ‘ΎΝ§–χ”ο“τ Ε±πœΒΆ≥÷–Θ§Ά®≥Θ≤…”Ο39Έ§ΒΡMFCC(Mel Frequency Cepstral Coefficient)ΧΊ’ςΘ§…θ÷Ν‘ΌΦ”»κ“Μ–©ΧΊ’ςΓΘΒΪ «Θ§ΩΦ¬«ΒΫ«Ε»κ ΫœΒΆ≥”–œόΒΡ”≤ΦΰΉ ‘¥Θ§‘Ύ≤ΜΫΒΒΆ Ε±π¬ ΒΡΜυ¥Γ…œΘ§”ΠΨΓΝΩΦθ…ΌΧΊ’ςΒΡΈ§ ΐΓΘ±ΨΈΡ≤…”ΟΉν–ΓΜΞ–≈œΔΗΡ±δΉΦ‘ρMMIC(Minimum Mutual Information Change)Ϋχ––ΧΊ’ς―Γ‘ώΓΘ“ΜΫΉΕΈ≤…”Ο22Έ§MFCCΧΊ’ςΘ®9 MFCCΘ§6 ΠΛMFCCΘ§4 ΠΛ2MFCCΘ§EΘ§ΠΛEΘ§ΠΛ2EΘ©Θ§ΕΰΫΉΕΈ≤…”Ο26Έ§MFCCΧΊ’ςΘ®10 MFCCΘ§7 ΠΛMFCCΘ§6 ΠΛ2MFCCΘ§EΘ§ΠΛEΘ§ΠΛ2EΘ©ΓΘ 2.3 ΐΨίΒΡ δ»κ δ≥ω Ε‘”Ύ”≤ΦΰœΒΆ≥Θ§»γΙϊ ΐΨίΒΡΕΝ»κΥΌΕ»Ϋœ¬ΐΘ§‘ρΕ‘‘ΥΥψΥΌΕ»”ΑœλΨΆΚή¥σΓΘ‘Ύ±Θ÷ΛœΒΆ≥ΗΏ Ε±π¬ ΒΡ«ΑΧαœ¬Θ§œΒΆ≥ΒΡΡΎ¥φœϊΚΡΝΩΚΆ Ε±π ±Φδ≥Θ≥Θ «“ΜΕ‘Ο§ΕήΧεΘ§ΚήΡ―±Θ÷ΛΝΫ’ΏΆ§ ±¥οΒΫάμœκΉ¥Χ§ΓΘ»γΙϊΫωΫωΩΦ¬«ΫΎ ΓΡΎ¥φΘ§ΫΪΟΩΗω¥ Χθ Ε±πΆχ¬γΚΆœύ”ΠΒΡΉ¥Χ§÷πΗωΕΝ»κΘ§ΦΤΥψΤΞ≈δΖ÷ ΐΘ§’β―υΥδ»ΜΩ…“‘Ήν¥σœόΕ»ΒΊΫΎ ΓΡΎ¥φΒΡ Ι”ΟΝΩΘ§ΒΪ « ΐΨίΒΡΕύ¥ΈΕΝ»κ’Φ”ΟΝΥ¥σΝΩ ±ΦδΘ§≤Δ«“Ζ¥Η¥ΦΤΥψΆ§“ΜΗωΉΣ“ΤΗ≈¬ Θ§“≤Ε‘ Ε±π ±Φδ”ΑœλΚή¥σΓΘΝμ“ΜΖΫΟφΘ§»γΙϊΫωΫωΩΦ¬«‘ΥΥψΥΌΕ»Θ§“Μ¥Έ–‘ΫΪΥυ”–¥ ΧθΒΡ Ε±πΆχ¬γΚΆΥυ”–Ή¥Χ§ΡΘ–ΆΕΝ»κΡΎ¥φΘ§Υδ»ΜΫω–η“Μ¥Έ ΐΨίΕΝ»κΘ§‘ΥΥψΥΌΕ»¥σ¥σΧαΗΏΘ§ΒΪ»¥Ε‘ΡΎ¥φΧα≥ωΝΥΗϋΗΏ“Σ«σΓΘΈΣΝΥΗϋΚΟΒΊάϊ”ΟœΒΆ≥ΒΡ”≤ΦΰΉ ‘¥Θ§±ΨœΒΆ≥ Ήœ»÷πΗωΕΝ»κΉ¥Χ§ΡΘ–ΆΘ§ΦΤΥψΥυ”–Ιέ≤λ ΗΝΩ‘ΎΗςΉ¥Χ§ΡΘ–Άœ¬ΒΡ δ≥ωΗ≈¬ Θ§¥φΖ≈‘ΎΡΎ¥φ÷–ΘΜ»ΜΚσ÷πΧθΕΝ»κ Ε±πΆχ¬γΘ§―ûìΖΨΕΥΤ»ΜΕ»ΉνΗΏΒΡ¥ ΧθΉςΈΣΉν÷’ΒΡ Ε±πΫαΙϊΓΘ’β―υΉέΚœΝΥ«ΑΟφΝΫ÷÷ΖΫΑΗΒΡ”≈ΒψΘ§ ”ΠΝΥ”≤ΦΰœΒΆ≥ΒΡ“Σ«σΓΘ 2.4 ΝΫΫΉΕΈΕΥΒψΦλ≤β ΕΥΒψΦλ≤β ««Ε»κ Ϋ”ο“τ Ε±π÷–ΉνΜυ±ΨΒΡΡΘΩιΓΘΕΥΒψΦλ≤β «ΖώΉΦ»Ζ÷±Ϋ””ΑœλœΒΆ≥ΒΡ‘ΥΥψΗ¥‘”Ε»ΚΆœΒΆ≥ΒΡ Ε±π–‘ΡήΓΘ“ρ¥Υ‘Ύ≤Μ‘ωΦ”Η¥‘”‘ΥΥψΝΩΒΡ«ΑΧαœ¬Θ§œΘΆϊΕΥΒψΦλ≤βΡήΨΓΝΩΉΦ»ΖΘ§Εχ«“Ρή ”Π«Ε»κ ΫœΒΆ≥Εύ±δΒΡ”Π”ΟΜΖΨ≥ΓΘ±ΨΈΡ Ι”ΟΝΥ“Μ÷÷”––ßΒΡΝΫΫΉΕΈΕΥΒψΦλ≤βΖΫΖ®ΓΘ‘ΎΒΎ“ΜΫΉΕΈ Ι”ΟΆΦœώΖ÷Ην÷–Ψ≠≥Θ Ι”ΟΒΡ±Ώ‘ΒΦλ≤β¬Υ≤®ΤςΖΫΖ®Θ§ΒΟΒΫ“ΜΗωΡήΑϋΚ§”ο“τΕΈΆ§ ±”÷±»ΫœΩμΥ…ΒΡΕΥΒψΫαΙϊΘΜ‘ΎΒΎΕΰΫΉΕΈΘ§Ε‘ΒΎ“ΜΫΉΕΈΒΡΫαΙϊΫχ––‘Ό≈–ΨωΘ§ Ι”Ο÷±ΖΫΆΦΆ≥ΦΤΖΫΖ®ΒΟΒΫΨ≤“τΕΈΒΡΡήΝΩΨέάύ÷––ΡΘ§≤Δ”Ο’βΗω÷––ΡΡήΝΩ÷ΒΕ‘’ϊΨδΡήΝΩ–ρΝ–Ϋχ––÷––Ρœς≤®Θ§Ε‘œς≤®ΚσΒΡΡήΝΩ–ρΝ–Ϋχ––Ήν÷’≈–ΨωΓΘΆ®≥ΘΉν÷’ΒΡΫαΙϊΜα‘ΎΒΎΕΰΫΉΕΈΕΥΒψΦλ≤βΒΡΜυ¥Γ…œΉς Β±ΒΡΖ≈Υ…Θ§«ΑΚσΖ≈Υ…4~5÷Γ(¥σ‘Φ64~80ms)Θ§’β–©Ζ≈Υ…‘Ύ«σ»ΓΧΊ’ςΒΡ≤νΖ÷Ζ÷ΝΩ ± «Κή”–±Ί“ΣΒΡΓΘ ‘Ύ Β―ι “ΜΖΨ≥œ¬(–≈‘κ±»¥σ”Ύ25dB)Θ§“‘8kHz≤…―υΤΒ¬ ¬Φ÷ΤΝΥ20»Υ(Τδ÷–Ρ–ΓΔ≈°Ης10»Υ)ΒΡ”ο“τ ΐΨίΓΘΕ‘”Ύ12 000Ψδ‘≠ Φ¬Φ÷Τ”ο“τΜρ¥χ‘κ”ο“τΘ§Ε‘¥ΪΆ≥ΒΡΙΧΕ®ΡήΝΩψ–÷ΒΖΫΖ®ΚΆΝΫΫΉΕΈΦλ≤βΖΫΖ®Ϋχ––ΝΥ±»Ϋœ≤β ‘ΓΘ≤β ‘ΒΡ–‘Ρή»γ±μ1Υυ ΨΓΘ 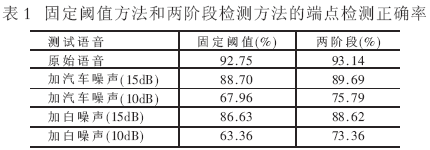 ¥ΪΆ≥ΒΡΙΧΕ®ψ–÷ΒΖΫΖ®ΨΆ «’κΕ‘ΜΖΨ≥‘κ…υ…ηΕ®“ΜΗωΙΧΕ®ΒΡΡήΝΩψ–÷ΒΫχ––ΕΥΒψΦλ≤βΓΘ Β―ι±μΟςΘ§ΝΫΫΉΕΈΦλ≤βΖΫΖ®Έό¬έ‘ΎΑ≤Ψ≤ΜΖΨ≥÷–ΜΙ «‘ΎΑϋΚ§“ΜΕ®‘κ…υΒΡΜΖΨ≥÷–Θ§ΕΦ±»ΙΧΕ®ΡήΝΩψ–÷ΒΒΡΕΥΒψΦλ≤βΖΫΖ®”–ΗϋΚΟΒΡ–‘ΡήΓΘ¥ΥΖΫΖ®ΡήΙΜΫχ“Μ≤ΫΗΡ…Τ«Ε»κ Ϋ”ο“τ Ε±πœΒΆ≥ΒΡ Ε±π–‘ΡήΓΘ 2.5 χΥ―Υς ”Δ”ο”ο“τΖΔ“τΩλΓΔΒΞ¥ ≥ΛΓΔΉ¥Χ§ ΐΕύΘ§“ρΕχΥ―Υς ±Φδ≥ΛΓΘ“Σ Βœ÷ Β ± Ε±πΘ§ΨΆ≤ΜΡή‘ΎΥυ”–ΒΡ”ο“τ ΐΨίΕΦΒΟΒΫΚσ‘ΌΫχ––Ϋβ¬κ Ε±πΓΘ‘ΎΝΫΦΕ Ε±πΆχ¬γ÷–Θ§ΒΎ“ΜΫΉΕΈ“Σ‘Ύ¥σΝΩΒΡ¥ Χθ÷–Υ―ΥςΘ§ΕχΒΎΕΰΫΉΕΈ÷Μ‘ΎN_BEST¥ Χθ÷–Υ―ΥςΘ§œύΕ‘ ±Φδ’Φ”ΟΝΩΚή…ΌΓΘΈΣΝΥ¬ζΉψ Β ±“Σ«σΘ§±ΨœΒΆ≥‘ΎΜώ»Γ”ο“τ–≈Κ≈ΒΡΆ§ ±Ϋχ––Χα»ΓΧΊ’ςΚΆΒΎ“ΜΫΉΕΈ Ε±πΓΘΗυΨί”≤ΦΰΒΡΡΎ¥φ»ίΝΩΘ§ΩΦ¬«ΒΫΤΞ≈δΖ÷ ΐΥυ’Φ”ΟΒΡΡΎ¥φΘ§―Γ»ΓΟΩ20÷ΓΘ®320msΘ©ΒΡ”ο“τΆξ≥…“Μ¥ΈΥ―ΥςΓΘ”…”ΎΥυΥ―ΥςΒΡ¥ Χθ≤ΔΟΜ”–Ϋα χΘ§≤ΜΡή«σ≥ωΉν÷’Ε‘”Π”Ύ¥ ΧθΒΡΖ÷ ΐΓΘ“ρ¥ΥΘ§±Ί–κ±ΘΝτΟΩ¥ΈΥ―Υς÷–ΟΩΗω¥ ΧθΒΡΟΩΗωΫΎΒψΒΡΤΞ≈δΖ÷ ΐΘ§’β¥χά¥ΝΥ–¬ΒΡΡΎ¥φΩΣœζΓΘ ΫβΨωΖΫΖ® «‘ΎΒΎ“ΜΫΉΕΈ Ε±πΆχ¬γ÷–Φ”»κ χΥ―ΥςΘ®Beam SearchΘ©ΩλΥΌΥψΖ®ΓΘΗΟΥψΖ®ΦΌ…ηΘΚViterbiΫβ¬κΙΐ≥Χ÷–ΒΡΉνΦ―¬ΖΨΕ‘Ύ»ΈΚΈ ±ΩΧΕΦΡή±Θ÷ΛΫœΗΏΒΡΥΤ»ΜΕ»Θ§‘ΎΥ―ΥςΙΐ≥Χ÷–Ε‘Άχ¬γΫχ––Φτ÷ΠΘ§÷Μ±ΘΝτΤΞ≈δΖ÷ ΐΉν¥σΒΡ”–œόΗω¬ΖΨΕΘ§“‘Φθ…Ό‘ΥΥψΝΩΚΆΡΎ¥φœϊΚΡΓΘΒΪ «Θ§“ΣΜώΒΟΤΞ≈δΖ÷ ΐΉν¥σΒΡΦΗΗωΉ¥Χ§Θ§‘ΎΟΩ¥ΈΥ―ΥςΙΐ≥Χ÷–ΕΦ“ΣΕ‘ΤΞ≈δΖ÷ ΐΫχ––≈≈–ρΘ§’β Ι‘ΥΥψΗΚΒΘΦ”÷ΊΘ§‘Ύ ΒΦ ÷–≤ΜΩ…»ΓΓΘΈΣΝΥΫβΨω’β“ΜΈ ΧβΘ§ΫαΚœ±ΨœΒΆ≥ Ε±πΆχ¬γΒΡΧΊΒψΘ§≤…”ΟΝΥ“Μ÷÷Μ§Ε·¥Α χΥ―ΥςΥψΖ®ΓΘΕ‘”ΎΟΩ“ΜΗω¥ ΧθΆχ¬γΘ§‘ΎViterbiΫβ¬κΙΐ≥Χ÷–Θ§ΫϋΥΤΒΊ»œΈΣ’φ Β¬ΖΨΕΉή «Β±«ΑΤΞ≈δΖ÷ ΐΉν”≈ΒΡ¬ΖΨΕΒΡΫϋΝΎ¬ΖΨΕΓΘ“ρ¥ΥΘ§…η÷ΟΝΥ“ΜΗωΙΧΕ®ΩμΕ»ΒΡ¥ΑΘ§‘ΎΥυ”– ±ΩΧΘ§¥Α÷–ΒΡ¬ΖΨΕΉήΑϋΚ§ΝΥΗΟ ±ΩΧΥΤ»ΜΕ»ΉνΗΏΒΡ¬ΖΨΕΦΑΤδœύΝΎ¬ΖΨΕΘ§ΕχΡ«–©¬δ‘Ύ¥ΑΆβΒΡ¬ΖΨΕ‘ρΫΪ±ΜΦτ÷ΠΓΘ”…”ΎΡΘ–ΆΉ¥Χ§≤ΜΩ…Ωγ‘ΫΘ§“ρ¥ΥΘ§œ¬“ΜΗωΜν‘Ψ¬ΖΨΕΒΡΈΜ÷ΟΘ§÷ΜΩ…Ρή «…œ“ΜΗωΜν‘Ψ¬ΖΨΕΒΡ‘≠”–ΈΜ÷ΟΜρ’ΏΜ§Ε·“ΜΗώΓΘ”…”Ύ÷–ΦδΒΡΤΞ≈δΖ÷ ΐœύΆ§Θ§±»ΫœΜ§Ε·¥ΑΝΫΕΥΒΡΤΞ≈δΖ÷ ΐΦ¥Ω…ΨωΕ®œ¬“ΜΗωΜ§Ε·¥ΑΒΡΈΜ÷ΟΓΘ’β―υΩ…¥σ¥σΦθ–Γ±»ΫœΒΡ‘ΥΥψΝΩΘ§ΧαΗΏ‘ΥΥψΥΌΕ»ΓΘ ”…”Ύ”ο“τ–≈Κ≈ΥφΜζ–‘Ϋœ«ΩΘ§ χΥ―ΥςΒΡ’β÷÷ΦΌ…η≤Δ≤ΜΉήΖϊΚœ’φ Β«ιΩωΘ§“ρ¥ΥΘ§Ιΐ’≠ΒΡ χΩμΚή»ί“ΉΒΦ÷¬ΉνΚσ Ε±πΫαΙϊΒΡ¥μΈσΓΘ“‘»ΐΕ‘Ϋ«ΗΏΥΙΡΘ–ΆΈΣάΐΘ§”ο“τΩβΈΣ10ΗωΡ–…ζΒΡΟϋΝν¥ ΓΘ¥ΑΩμ”κ Ε±π¬ ΒΡΙΊœΒ»γ±μ2Υυ ΨΓΘ 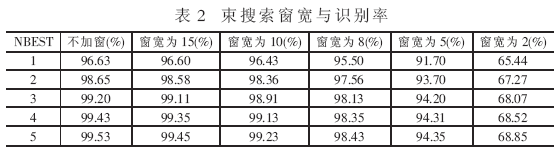 Ω…“‘Ω¥≥ωΘ§Β±¥ΑΩμΈΣ15 ±Θ§ Ε±π¬ Μυ±ΨΟΜ”–œ¬ΫΒΓΘ’βΗωΫαΙϊ”κΚρ―Γ¥ ΧθΒΡ≥ΛΕ»”–ΙΊΘ§¥ ΧθΒΡΉ¥Χ§ ΐ‘ΫΕύΘ§Ήν”≈ΫαΙϊ‘ΎΥ―ΥςΙΐ≥Χ÷–ΓΑ¬Ε≥ωΓ±¥ΑΆβΒΡΩ…Ρή–‘“≤ΨΆ‘Ϋ¥σΓΘΉέΚœ χΥ―ΥςΕ‘œΒΆ≥¬ ΚΆ Ε±π ±ΦδΝΫΖΫΟφΒΡ”ΑœλΘ§―ΓΕ®ΝΥ χΩμΈΣ10ΒΡΜ§Ε·¥ΑΥψΖ®ΉςΈΣœΒΆ≥ΒΡ χΥ―ΥςΥψΖ®ΓΘ 3 Β―ιΫαΙϊ Β―ι―ΒΝΖΦ·≤…”ΟLDC WSJ1―ΒΝΖΩβ(SI_TR_S)Θ§Αϋά®200»ΥΒΡΝ§–χ”ο“τΘ§Ι≤61Ηω–Γ ±Θ§ΫΒ≤…―υΈΣ8kHzΘ§16ΈΜΝΩΜ·ΓΘ≤β ‘Φ·ΈΣ”…WSJ1≤β ‘Φ·(CDTestΚΆHSDTestΘ©ΒΟΒΫΒΡ525ΗωΕΧΨδ(ΟΩΨδΑϋΚ§2ΗωΒΞ¥ )Θ§Κρ―Γ¥ ΧθΈΣ535ΗωΘ§Αϋά®637Ηω≤ΜΆ§ΒΡΒΞ¥ ΖΔ“τΘ§Ά§―υΫΒ≤…―υΈΣ8kHzΘ§16ΈΜΝΩΜ·ΓΘ ±μ3ΈΣ“ΜΫΉΕΈ Ε±πΚΆΝΫΫΉΕΈ Ε±πΒΡ Ε±π¬ ΓΔ Ε±π ±ΦδΚΆΡΎ¥φ’Φ”ΟΝΩ±»ΫœΓΘ¥”±μ3Ω…“‘Ω¥≥ωΘ§”κ÷±Ϋ”Ϋχ––ΒΡ“ΜΫΉΕΈ Ε±πœύ±»Θ§ΝΫΫΉΕΈ Ε±πΆ®Ιΐ≤…”ΟΝΫΫΉΕΈΕΥΒψΦλ≤βΖΫΖ®ΓΔMMICΧΊ’ς―Γ‘ώΥψΖ®ΓΔΧΊ’ςΧα»ΓΚΆΫβ¬κΆ§≤ΫΒΡ χΥ―ΥςΥψΖ®Θ§ΦΪ¥σΒΊΧαΗΏΝΥ Ε±π¬ Θ§Φθ…ΌΝΥΡΎ¥φ’Φ”ΟΝΩΚΆ Ε±π ±ΦδΓΘ  ±ΨΈΡΧα≥ωΝΥ“Μ÷÷Μυ”ΎΕ®ΒψDSPΒΡ«Ε»κ Ϋ”Δ”οΙ¬ΝΔ¥ Ε±πœΒΆ≥Θ§≤…”ΟΝΫΫΉΕΈ Ε±πΒΡΝ§–χHMMΡΘ–ΆΓΘΤδ÷–ΒΎ“ΜΫΉΕΈΈΣ Β ± Ε±πΘ§ΒΎΕΰΫΉΕΈΈΣΖ« Β ± Ε±πΓΘΆ®Ιΐ≤…”Ο–¬”±ΒΡΝΫΫΉΕΈΕΥΒψΦλ≤βΖΫΖ®ΓΔΉν–ΓΜΞ–≈œΔΗΡ±δΉΦ‘ρΧΊ’ς―Γ‘ώΥψΖ®ΓΔΧΊ’ςΧα»ΓΚΆΫβ¬κΆ§≤ΫΒΡ χΥ―ΥςΥψΖ®Θ§Ϋχ“Μ≤ΫΧαΗΏΝΥ Ε±π–‘ΡήΓΔΦθ…ΌΝΥΡΎ¥φ’Φ”ΟΝΩΚΆΦΤΥψΗ¥‘”Ε»ΓΘ |



Άχ”―Τά¬έ