
嵌入式Java运行平台数据库引擎的应用研究
发布时间:2010-11-16 16:04
发布者:eetech
|
介绍某嵌入式Java运行平台的总体框架;在此基础上,详细讨论为该平台开发的数据库(DB)引擎组件的框架和结构组成,描述该组件实现的SQL子集和数据表达方式以及逻辑算法的设计思路;提出该组件今后的改进设想。 随着嵌入式系统CPU硬件从8位到32位的发展,嵌入式系统软件的开发环境也得到迅猛的发展,编程语言从10多年以前的汇编为主流发展到现在C、C++、Java为主流。另外,面向对象设计技术、组件技术等在嵌入式系统软件设计中的应用也日益引起人们的重视。 在嵌入式系统软件开发领域,Java是一门较新的异军突起的编程语言。其优点是语言本身简洁优美,完全按照面向对象思想设计,并且语言引入许多较为先进的特性,如多线程、自动内存管理和垃圾回收,非常适合于大规模复杂软件系统的开发。其不足点是与硬件结合不够紧密,同时代码运行速度较慢。此外,对于内存的使用,程序难于管理和控制。 由于采用Java编程具有如上所述的众多优点,越来越多的嵌入式系统采用Java技术来构造软件系统。本文在介绍基于日本某自动售货机产品的控制板的Java运行平台基础上,详细讨论笔者为其平台开发的DB引擎的组成和设计思路。 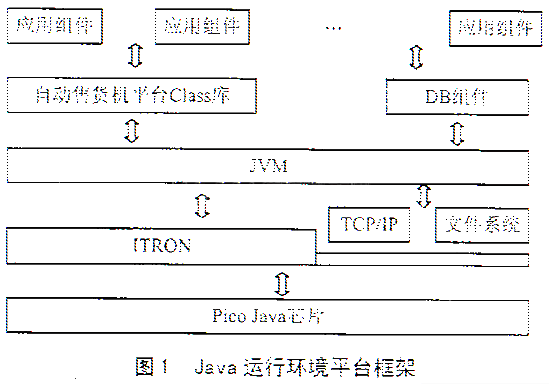 1 Java运行环境平台 图1所示为Java运行环境的总体框架示意图。本系统为克服Java的解释执行机制所引起的执行速度慢的问题,在硬件上采用了Sun公司开发的Pico Java芯片。它能够直接执行Java的二进制代码,使Java的执行速度提高一个数量级以上。在硬件层的上面是OS层,本系统采用的是ITRON(日本东京大学坂村键教授设计的一种嵌入式操作系统,虽然在日本以外的市场影响不大,但在日本本地市场,占有率达90%以上)。由于ITRON规格制定得比较早,并且为兼顾低端嵌入式应用的场合,ITRON总体上功能比较简单,并未把诸如TCP/IP、文件系统等内容包含在其里面,因此与嵌入式Linux等不一样的是,TCP/IP、文件系统是以独立的组件形式存在的。在OS层的上面是JVM层。与其它一般Java虚拟机不同的是,本系统的Java执行代码不需要由JVM解释执行,而是由CPU硬件直接执行。在JVM的上层是自动售货机的基础平台类库和公共组件层。本文介绍的DB引擎组件正是处于这一层。该层的上面是应用程序层,用于实现自动售货机的各种控制、管理机能。 2 嵌入式系统DB引擎 2.1 DB引擎组件的引入 众所周知,在台式机领域,DB是一个十分关键的基础软件。以往嵌入式系统的软件可能更侧重于与硬件的交互与控制,但随着对嵌入式系统功能需求的日益复杂化,嵌入式系统软件中,信息、数据的保存与管理的比重也日益增加。在这样的背景下,嵌入式系统软件开发中,通过引入DB组件,对实现软件整体框架结构的组件化与简单化,有着十分明显而重要的意义。 2.2 DB引擎组件的总体框架 如图2所示,将整个DB组件设计为3层结构,分别为JDBC接口层、SQL解释层和动作执行层。这3层之间呈单向依赖关系。也就是说,SQL解释层依赖于动作执行层,但动作执行层不依赖于其上面的两层,可以单独存在而直接被使用。如果用户以使用方便为主要目的,可采用完全配置方式,应用程序通过JDBC接口层存取数据。反之,如果用户对空间和效率要求较高,可仅配置动作执行层组件,应用程序直接调用动作执行层的API进行数据的检过和更新等操作。 (1)JDBC接口层 如前文所述是可选组件,旨在为应用程序提供一个标准的DB调用接口。 (2)SQL解释层 本DB组件实现的SQL解释层,只实现了标准SQL的一个小子集,主要完成select、delete、insert、update、create table、drop table等功能。其中数据操作语句(select、delete、insert、update)的解释要点之一是where条件子句的解释执行,类似于数学表达式求值算法。本文采用简单直观的“算符优先法”。该算法使用两个工作栈,一个称作OPTR栈,用以寄存运算符;另一个称作OPND栈,用以寄存操作数或运算结果。算法的基本思想是: 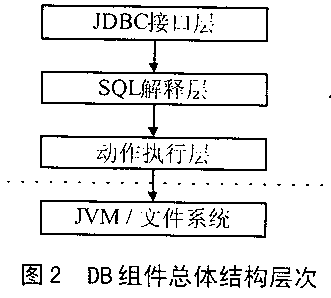 ①首先置操作数栈为空,表达式起始符“#”为运算栈的栈底元素; ②依此读入表达式中每个Token。若是操作数,则进OPND栈adk是运算符,则和OPTR栈的栈顶运算符比较优先权后作相应操作,直至整个表达式求值完毕(即OPTR栈的栈顶元素和当前读入的Token均为“#”。 本文实现的SQL子集描述如下: 预定义 := := :=[,[,[…]]] :=[,[…] ]] := =│==│!=││>│>=│:=[,[,[…]]] :=MIN│MAX│COUNT│SUM :=() :=,[,[,[…]]] :=INT│UNMBER│CHAR│DATE :=文递归定义式 :=() :=NOT :=OR :=AND SQL文定义式 ①SELECT*|FROM[table][WHERE][ORDER BY[ASC|DESC]] ②SELECTFROM[table][WHERE] ③UPDATE[table]SET[WHERE] ④INSERT INTO[table][()]VALUES() ⑤DELETE FROM[table][WHERE] ⑥CREATE TABLE[table]([,[,[…]]]) ⑦DROP TABLE[table] 注:|表示多选个,表示某定义项目,[]表示可选项目,…代表循环省略表示。 (3)动作执行层 动作执行层是整个DB组件的核心和关键,因为所有的DB操作最终都由该层完成,同时用户也可以跳过上面的两层,直接调用该层的API,以实现相同的数据操作功能。下面介绍其主要设计要点和思路。 2.3 数据的表达与存储 由于嵌入式系统的资源十分有限,不能引入复杂的算法和数据存储格式,同时由于Java对二进制数据的处理十分不便,本文最终采用CSV格式来保存表数据。其要点是: ①各字段数据之间采用「,」分开; ②如果字段数据本身包含有「,」,则将整个字段数据用引号「」括起来; ③如果字段数据本身包含有引号「”」,则将引号「”」改写为两个重叠的引号「””」,依次类推。其次,每个记录占文本文件的个行,每一个数据表与一个物理数据文件一一对应。 采用这种方式处理的优点是: ①全部数据都是采用字符串保存,Java处理起来十分方便; ②对不定长字段的保存处理与定长字段处理统一,不需要额外的附加处理,而且存储效率高; ③对多字节文字的处理程序不需要额外的编码转换处理,由JVM平台本身的功能可以自动完成。 当然,采用这种处理方式也存在其不足之处: ①由于在数据文件中,每条记录的长度不定,数据即使局部更新,也必须重写整个文件; ②由于同样原因,单条记录的检索难于直接定位,而必须读入整个数据文件。 为弥补由此产生的性能下降,本文采用数据Cache加以克服。也就是说,尽可能将数据缓存在内存中,通过减少对物理文件的读写操作来提高数据的性能。 2.4 多线程数据存取的同步与互斥 在Java虚拟机环境下,没有多进程的概念,但对于多任务的处理提供了多线程的手段。本DB引擎组件是公共组件,供上层多个应用程序组件共同使用。由于上层的每个应用程序组件本身由一个或数个线程来执行,因此,DB引擎组件必须考虑多个线程同时存取某个数据时可能引起的冲突问题。对于该问题的解决办法,一般是采用DB锁定的方法。关于DB锁定,进一步细分的话,可区分为读锁和写锁;根据锁定粒度的粗细可分为按表锁、按Page锁、按记录锁等,不一而足。 为设计和实现的简单起见,本DB引擎组件提供按表锁定的方式,同时不区分读写锁之间的区别。这样,大大简化了SQL语句的分析和处理过程,并且可以直接把锁定操作与表的open操作相关联,锁解除与表的close操作相关联。实现时,对应表对象Table的每一个实例,设置一个field变量,用于保存锁定状态,再利用Java语言提供的synchronized手段同,可以较为方便地实现数据表的锁定功能。代表示例如下: //表锁定。为了避免死锁,有超时判断逻辑 synchronized void lock()throws DBError{ long t2,t1; t1=System.currentTimeMillis(); //由于可能出现在wait语句被唤醒而却得不到表锁的情况,为提高超时逻辑判断精度,采用循环 while(isLocked){ try{ wait(DBError.TIMEOUT/10); }catch(Exception e){e.printStackTrace();} //超时判断 t2=System.currentTimeMillis(); if(t2-t1>DBError.TIMEOUT)break; } //发生超时退出循环情况,抛出例外 if(isLocked){ throw new DBError(DBError.TIMEOUT_ERR,name); } //设定锁定标志 isLocked=true; } //表打开操作 //参数ro只读打开标志 void open(Boolean ro)throws DBError{ lock(); readOnly=ro; //表数据读入 load(); } //表关闭操作(同时释放锁) public synchronized void close() throws DBError{ if(isLocked==false)return; //关闭前,保存数据 if(isDirty)save(); if(isUnload)unload(); //释放锁,通知其它等待线程 isLocked=false; notify(); } 图3 DB引擎组件主要类的关系 2.5 DB组件实现的结构设计 图3所示为DB引擎组件的主要类之间的关系。其中,Database为数据库类,用于描述和管理整个数据库对象Table为数据表类,用于描述和管理表对象;TableData用于描述和管理保存表数据的物理介质(文件);Field为字段类,用于描述和管理字段类型信息;Record为记录类,描述一条数据记录。为简化处理,本组件将Database类设计为singleton模式,即本组件只能创建一个Database实例。这对于嵌入式系统来说,大部分场合已经足够。与数据库的一般物理概念相对应,1个Database实例包含n个Table实例,1个Table实例包含n个Field实例。同时,1个Table实例包含1个TableData实例,1个TableData实例包含n个Record实例。 Connection类用于管理用户访问数据库的会话(Session)过程。对应一个用户的一次会话过程,生成一个Connection实例。Connection类对象保存着当前Session打开的Table列表,当用户提交执行某SQL语句而需要锁定某个Table时,系统首先检查该表是否已经在当前Session已打开的Table列表中。如果已经被打开,则不需要进行重复的锁定操作,直接反回对应的Table对象实例。反之,如果尚未包含在打开的Table列表中,表明当前Session尚未打开和锁定该表,必须执行该表的打开和锁定操作(如果该表已被其它Session打开,则必须等待到其它Session翻放该表为止)。 本DB组件还支持commit与rollback事务处理。能够在如此微小的DB组件实现事务处理,主要得益于上述的Session管理框架。在Table类commit与rollback处理基础上,当一个Session执行commit或rollback操作时,对包含在打开列表中的每个Table实例,调用执行相应的commit或rollback处理即可。 3 结语与展望 本DB组件已实际运行了大约两年时间。这期间除了对该组件进行一些功能追加以外,主体框架上基本保持不变,从而在一定程序上表明了该设计框架的可行性和合理性。该组件编译以后,class文件形成的jar包大小约为68KB,短小精度悍,便于使用。当然,该DB组件目前仍然存在一些不足:首先,较为关键的一点是速度问题。一直以来,Java的执行速度问题就是受批语的缺点所在,因此采用它实现自然也避免不了这人瓶颈。今后改进的思路之一是,将其中Java处理效率不高的部分移出Java,采用C实现;二者通过JNI手段加以连接,以提高总体的运行速度。第二点需要改进的地方是表锁定的粒度问题。由于目前只能整个表进行锁定,并且不区分读锁定与写锁定,因此粒度较粗。虽然这样实现起来较为简单,但在多任务处理环境中可能增加不必要的时间等待。最后,JDBC接口的实现目前还不完全,需要加以完善。 |




网友评论