
ЛљгкFPGAЕФвЦЮЛМФДцЦїСїЫЎЯпНсЙЙFFTДІРэЦї
ЗЂВМЪБМфЃК2010-11-9 20:55
ЗЂВМепЃКtechshare
|
ПьЫйИЕРявЖБфЛЛ(FFT)дкРзДяЁЂЭЈаХКЭЕчзгЖдПЙЕШСьгђгаЙуЗКгІгУЁЃНќФъРДЯжГЁПЩБрГЬУХеѓСа(FPGA)ЕФЗЩЫйЗЂеЙЃЌгыDSPММЪѕЯрБШЃЌгЩгкЦфВЂаааХКХДІРэНсЙЙЃЌЪЙЕУFPGAФмЙЛКмКУЕиЪЪгУгкИпЫйаХКХДІРэЯЕЭГЁЃгЩгкAlteraЕШЙЋЫОбажЦЕФFFT IPКЫЃЌМлЧЎАКЙѓЃЌВЛЪЪКЯДѓЙцФЃгІгУЃЌдкЬиЖЈСьгђжаЃЌЩшМЦЪЪКЯгкздМКСьгђашвЊЕФFFTДІРэЦїЪЧНЯЮЊЪЕМЪЕФбЁдёЁЃ БОЮФЩшМЦЕФFFTДІРэЦїЃЌЛљгкFPGAММЪѕЃЌгЩгкВЩгУвЦЮЛМФДцЦїСїЫЎЯпНсЙЙЃЌЪЕЯжСЫСНТЗЪ§ОнЕФЭЌЪБЪфШыЃЌЯрБШДЋЭГЕФМЖСЊНсЙЙЃЌЬсИпСЫЕћаЮдЫЫуЕЅдЊЕФдЫЫуаЇТЪЃЌМѕаЁСЫЪфГібгЪБЃЌНЕЕЭСЫаОЦЌзЪдДЕФЪЙгУЁЃдкOFDMЯЕЭГЕФЪЕМЪгІгУжаЃЌвђЫќПЩвдВЩгУПьЫйИЕРявЖБфЛЛЃЌФмЗНБуПьНнЕиЪЕЯжЕїжЦКЭНтЕїЃЌЙЪНсКЯMIMOММЪѕЃЌЩшМЦЕФFFTДІРэЦїНсЙЙЃЌПЩвдКмКУЕигІгУгк2ИљЬьЯпЕФMIMO-OFDMЯЕЭГжаЁЃ 1 FFTДІРэЕФгІгУМАDIF FFTЫуЗЈдРэ ЭМ1ИјГівЛИі2ИљЬьЯпMIMO-OFDMЯЕЭГжаFFTЕФЪЙгУЁЃПьЫйИЕРявЖБфЛЛЫуЗЈЛљБОЩЯЗжЮЊСНДѓРрЃКЪБгђГщШЁ(DIT)КЭЦЕгђГщШЁ(DIF)ЃЌетРяЩшМЦЕФFFTДІРэЦїВЩгУЛљ-2 DIFЫуЗЈЁЃ 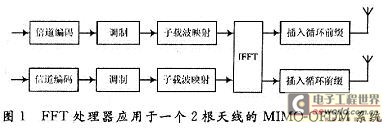 ЖдгкNЕуађСаx(N)ЃЌЦфИЕРявЖБфЛЛ 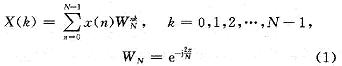 НЋx(n)ЗжГЩЩЯЁЂЯТСНВПЗжЃЌЕУЃК 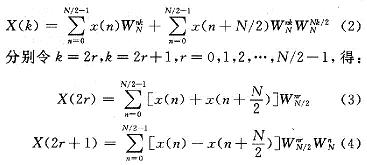 етбљНЋСНИіNЕуЕФDFTЗжГЩСНИіNЃЏ2ЕуЕФDFTЃЌЗжЕФЗНЗЈЪЧНЋx(k)АДађКХkЕФЦцЁЂХМЗжПЊЁЃЭЈЙ§етжжЗНЪНМЬајЗжЯТШЅЃЌжБЕНЕУЕНСНЕуЕФDFTЁЃВЩгУDIFЗНЗЈЩшМЦЕФFFTЃЌЦфЪфШыЪЧе§ађЃЌЪфГіЪЧАДееЦцХМЗжПЊЕФЕЙађЁЃ 2 вЦЮЛМФДцЦїСїЫЎЯпНсЙЙЕФFFT дкДЋЭГСїЫЎЯпНсЙЙЕФFFTжаЃЌашвЊНЋШЋВПЪ§ОнЪфШыМФДцЦїКѓЃЌПЩПЊЪМЕћаЮдЫЫуЁЃдкЛљ-2 DIFЫуЗЈжаПЩвдЗЂЯжЃЌЕБЧАNЃЏ2ИіЪ§ОнНјШыМФДцЦїКѓЃЌдЫЫуБуПЩвдПЊЪМЃЌДЫКѓНјШыЕФЕкNЃЏ2+1ИіЪ§ОнгыМФДцЦїЕквЛИіЪ§ОнНјааЕћаЮдЫЫуЃЌвдДЫРрЭЦЁЃ гЩгкВЩгУЦЕгђГщШЁЗЈЃЌВЛашвЊЖдЪфШыЕФЪ§ОнНјааЕЙађДІРэЃЌМђЛЏСЫЕижЗПижЦЃЌетбљЃЌПЩвдВЩгУвЦЮЛМФДцЦїЕФЗНЪНЃЌвРДЮНЋЧАNЃЏ2ИіЪ§ОнвЦШывЦЮЛМФДцЦїЃЌдкNЃЏ2+lЪБПЬЃЌЕквЛИіЪ§ОнвЦГівЦЮЛМФДцЦїЃЌВЮгыдЫЫуЁЃЯрЖдгкДЋЭГЕФRAMЖСаДЗНЪНЃЌВЩгУвЦЮЛМФДцЦїДцДЂНсЙЙзлКЯКѓЕФзюДѓЙЄзїЦЕТЪЮЊ500 MHzЃЌдЖДѓгкRAMЗНЪНЕФ166 MHzЁЃ ЕБвЦЮЛМФДцЦїЯрМЬгаЪ§ОнвЦГіЪБЃЌдквЦЮЛМФДцЦїжаЛсГіЯжПеАзЮЛЁЃДЫЪБЃЌв§ШыЕкЖўТЗЪ§ОнЃЌдкЕквЛТЗЪ§ОнвРДЮвЦГіНјааЕћЫуЪБЃЌЕкЖўТЗЪ§ОнвРДЮВЙГфЕНвЦЮЛМФДцЦїЕФПеАзЮЛжаЃЌЮЊдЫЫузізМБИЁЃЭЈЙ§етбљвЛжжРрЫЦЁАЦЙХвВйзїЁБЕФНсЙЙЃЌПЩвдЪЙЕћаЮдЫЫуФЃПщжаЕФЪ§ОнВЛМфЖЯЕиЪфШыЃЌдЫЫуаЇТЪДяЕН100ЃЅЁЃВЛЭЌгкДЋЭГЕФЁАЦЙХвВйзїЁБНсЙЙЃЌгЩгкЪЙгУвЦЮЛМФДцЦїЃЌВЛашвЊСНПщRAMЃЌПЩвдЪЁЕєвЛАыЕФМФДцЦїЁЃЭМ2ЮЊ256ЕуFFTДІРэЦїЕФЕквЛМЖНсЙЙЁЃ 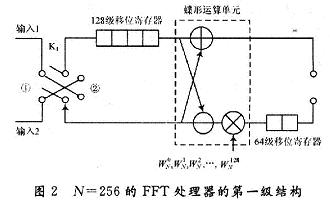 ЛљгкЩЯЪіЛљБОдРэЃЌНЋетжжвЦЮЛМФДцЦїНсЙЙРЉеЙЕНећИіFFTЯЕЭГЕФИїМЖЃЌПЩвдЗЂЯжИїМЖЪЙгУЕФвЦЮЛМФДцЦїЪ§СПЪЧЕнМѕЕФЁЃЯжЪЙгУвЛИі8ЕуНсЙЙРДНјааЫЕУїЁЃ ШчЭМ3ЫљЪОЃЌЪ§ОнгЩЪфШыlКЭЪфШы2НјШыЕквЛМЖЁЃЭЈЙ§ПЊЙиНјаабЁЭЈПижЦЁЃгЩгкЪЧN=8ЕФдЫЫуЃЌЫљвдИїМЖЗжБ№МгШы4МЖЁЂ2МЖКЭ1МЖЕФвЦЮЛМФДцЦїЁЃ 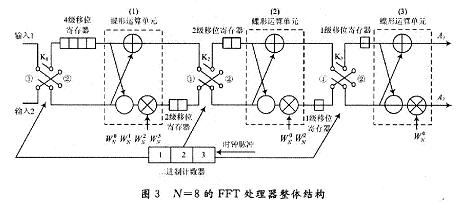 ЗжСНТЗРДЫЕУїдЫЫуЙ§ГЬЃК НЋK1ДђЕНЮЛжУЂйЃЌЕквЛТЗЪ§ОнНјШывЦЮЛМФДцЦїЃЌД§ЕквЛТЗЕФЧА4ИіЪ§ОнДцШы4МЖвЦЮЛМФДцЦїКѓЃЌЕквЛТЗНјШыЕФЕк5ИіЪ§ОнгывЦЮЛМФДцЦївЦГіЕФЕк1ИіЪ§ОнНјааЕћаЮдЫЫуЁЃ гЩгкЪфГіНсЙћгаЩЯЯТСНТЗЃЌЕкЖўМЖЪЧвЛИіЫФЕуЕФDFTЃЌЫљвдЖдгкЩЯТЗЕФЪфГіНсЙћx0(0)+x0(4)РрЫЦгкЕквЛМЖЃЌжБНгДцШыЯТвЛМЖМФДцЦїЃЌЮЊЫФЕудЫЫузізМБИЃЌЯТТЗЕФЪфГіЃЌЯШДцШыБОМЖ2МЖвЦЮЛМФДцЦїжаЃЌЕШЕНЩЯТЗЕФЫФЕудЫЫуПЊЪМЃЌЕкЖўМЖЕФвЦЮЛМФДцЦїгаПеАзЮЛЪБЃЌвЦШыЕкЖўМЖЃЌЮЊЯТТЗЕФЫФЕудЫЫузізМБИЁЃЫљвдЕквЛМЖЕћаЮдЫЫуЩЯТЗЪфГіЧАNЃЏ4=2ИіНјШыЯТвЛМЖМФДцЦїЃЌЯТТЗЪфГіЕФЪ§ОнвРДЮДцШыБОМЖвЦЮЛМФДцЦїжаЁЃ ЕБЕквЛМЖЕФЪфГіЧАNЃЏ4=2ИіЪ§Онx0(0)+x0(4)КЭx0(1)+x0(5)ДцШыЕкЖўМЖвЦЮЛМФДцЦїЪБЃЌдЫЫуБуПЩвдПЊЪМЃЌетЪБПЊЙиK2ДђЕНЮЛжУЂкЃЌДЫЪБЕквЛМЖЩЯТЗЪфГіЕФЪ§Онx0(2)+x0(6)ЃЌМДЕквЛМЖЩЯТЗЪфГіЕФЕкШ§ИіЪ§ОнгыЕкЖўМЖвЦЮЛМФДцЦївЦГіЕФЕквЛИіЪ§ОнЃЌМДx0(O)+x0(4)НјааЕћаЮдЫЫуЃЌЪфГіЕФЕкЫФИіЪ§Онx0(3)+x0(7)гыx0(1)+x0(5)НјааЕћЫуЁЃдкетИідЫЫуЙ§ГЬжаЃЌЕквЛМЖЕФ2МЖвЦЮЛМФДцЦївЦГіЪ§ОнвРДЮвЦЮЛДцШыЕНЕкЖўМЖЕФвЦЮЛМФДцЦїВњЩњЕФПеАзЮЛжаЁЃ СНИіЪБжгКѓЃЌЕквЛМЖЩЯТЗЪфГіЕФЫФИіЪ§ОнЭъГЩСЫЕћаЮдЫЫуЃЌK2ДђЕНЮЛжУЂйЃЌдкНгЯТРДЕФСНИіЪБжгРяЃЌЕквЛМЖжа2МЖвЦЮЛМФДцЦїЕФЪфГівРДЮгыДЫЪБЕкЖўМЖжа2МЖвЦЮЛМФДцЦїЕФЪфГіЪ§ОнНјааЕћаЮдЫЫуЃЌМДгыЃЌгыЭъГЩЕквЛМЖЯТТЗЪфГіЕФЫФИіЪ§ОнЕФЕћаЮдЫЫуЁЃ ДЫЪБЃЌЕквЛТЗдкЕквЛМЖдЫЫуКѓЕФЪфГіЪ§ОнЃЌдкЕкЖўМЖЭъГЩСЫШЋВПЕФЕћаЮдЫЫуЁЃЕкЖўМЖЕФЪфГіНсЙћЭЌЕквЛМЖвЛбљЃЌЕћаЮдЫЫуЕФЩЯТЗЪфГіЧАNЃЏ8=1ИіНјШыЯТвЛМЖМФДцЦїЃЌКѓвЛИіЪ§ОнжБНгНјШыКѓвЛМЖНјааЕњЫуЃЌЯТТЗЪфГіЕФЪ§ОнДцШыБОМЖвЦЮЛМФДцЦїжаЁЃ ЕкШ§МЖЕФдЫЫугыЕкЖўМЖКЭЕквЛМЖРрЫЦЃЌМДвЦШы1МЖМФДцЦїЕФЪ§ОнгыЦфКѓвЛИіЪ§ОнНјааЕњЫуЃЌЭЌЪБЪЙЧАвЛМЖМФДцЦїЕФЪфГіЪ§ОнНјШыКѓвЛМЖМФДцЦїЕФПеАзЮЛжаЃЌШЛКѓПЊЙиДђЕНЮЛжУЂкЃЌЖдЯТТЗЪфГіЪ§ОнНјааЕњЫуЁЃ ЖдгкЕкЖўТЗЪ§ОнЃЌЭЈЙ§ПЊЙиПижЦЃЌдкЕкЖўМЖжаЃЌД§ЕквЛТЗЕквЛМЖЯТТЗЪфГіЪ§ОнНјааЕћаЮдЫЫуЪБЃЌвЦШыМФДцЦїЕФПеАзЮЛЃЌЮЊдЫЫузізМБИЃЌгЩгкЧАМЖдЫЫужмЦкЪЧКѓМЖдЫжмЦкЕФСНБЖЃЌЖдгкЕкЖўМЖЕњЫуФЃПщЖјбдЃЌЪ§ОнШдШЛЪЧВЛМфЖЯЪфШыЕФЁЃЭЈЙ§етбљСНТЗЪ§ОнЕФНЛЬцдЫЫуКЭДцДЂЃЌЪЕЯжЁАЦЙХвВйзїЁБЃЌДгЖјЬсИпСЫЕћаЮдЫЫуФЃПщЕФдЫЫуаЇТЪЁЃЭМ4ЪЧ256ЕуFFTЕФОпЬхдЫЫуЪфШыКЭЪфГіЪБађЭМЁЃЖдгкжЛгавЛТЗЪ§ОнЕФгІгУГЁКЯЃЌПЩвддкЧАМЖМгШыЃЌУХПиПЊЙиКЭЪ§ОнЛКГхМФДцЦїЗжГЩСНТЗЪ§ОнЃЌЪЕЯжвЛТЗЪ§ОнЕФВЛМфЖЯЖСШыЁЃ 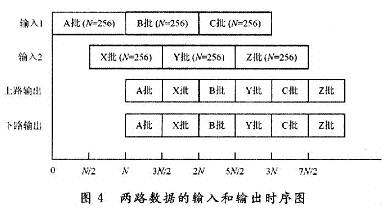 гЩгкВЩгУвЦЮЛМФДцЦїНсУЗЃЌИїМЖМФДцЦїЪЙгУЕФЪ§СПЖМЪЧЙЬЖЈЕФЃЌМДЮЊNЃЏ2+NЃЏ4ЁЃЦфжаЃЌNЮЊИУМЖDFTдЫЫуЕФЕуЪ§ЃЌИїМЖЪЙгУЕФвЦЮЛМФДцЦїЩюЖШж№МЖЕнМѕЃЌДгЖјДѓДѓНЕЕЭСЫМФДцЦїЕФЪЙгУЪ§СПЁЃ ДЫЭтЃЌгЩгкИїМЖНсЙЙЙЬЖЈЃЌЫљвдДѓЕуЪ§FFTжЛЪЧаЁЕуЪ§FFTЛљДЁЩЯМЖЪ§ЕФдіМгЃЌЖјЧвгЩгквЦЮЛМФДцЦїЕФЪфГіЯрЖдгкRAMЖјбдВЛашвЊИДдгЕФЕижЗПижЦЃЌЫљвдетжжНсЙЙЕФFFTДІРэЦїОпгаЗЧГЃКУЕФПЩРЉеЙадЁЃБШШчашвЊЪЕЯж512ЕуЕФFFTЃЌжЛашвЊдк256ЕуЕФЛљДЁЩЯдіМгвЛМЖМДПЩЁЃ 3 ОпЬхФЃПщЕФЩшМЦ 3ЃЎ1 ПижЦгыЕижЗВњЩњФЃПщ гЩгкСНТЗЪ§ОнЭЌЪБЪфШыЃЌЮЊСЫЗРжЙЗЂЩњСНТЗЪ§ОнМфЕФДЎШХЃЌЖдЪ§ОнЕФПижЦЯдЕУМЋЦфЙиМќЁЃДгЩЯУцЕФЫуЗЈНсЙЙЗжЮіжажЊЕРЃЌгЩгкКѓМЖЕФDFTдЫЫуЕуЪ§ЪЧЧАвЛМЖЕФвЛАыЃЌЫљвдКѓвЛМЖЕФПЊЙизЊЛЛжмЦквВЪЧЧАвЛМЖЕФвЛАыЃЌЛљгкетжжЙиЯЕЃЌПЩвдЪЙгУвЛИі8ЮЛМЦЪ§ЦїЕФУПвЛЮЛзДЬЌРДЖдИїМЖПЊЙиНјааПижЦЁЃзюИпЮЛПижЦЕквЛМЖЃЌЭЌЪБгЩгкЩЯвЛМЖЪ§ОнНјШыЯТвЛМЖашвЊвЛИіЪБжгЃЌЫљвдЯТвЛМЖЕФПЊЙизЊЛЛЪБПЬвЊБШЩЯвЛМЖбгГйвЛИіЪБжгжмЦкЁЃ ЖдгквЦЮЛМФДцЦїЃЌдкЪЕЯжЪБЃЌИїМЖЕФЧАМЖвЦЮЛМФДцЦїЩюЖШЮЊNЃЏ2-1ЃЌДгБОжЪЖјбдЃЌЪЧЪЙдЫЫуПЊЪМЕФЪБжгЩЯЩ§биЕНРДЪБЃЌЪ§ОнвбОГіЯждкЕњЫуФЃПщЪфШыЯпЩЯЃЌЖјВЛашвЊЯТвЛИіЪБжгЕФЧ§ЖЏРДвЦГіМФДцЦїЃЌБШШчЕкЖўМЖвЦЮЛМФДцЦїЕФМЖЪ§ЮЊ63ЁЃетбљЃЌдЫЫужмЦке§КУЪЧ2ЕФБЖЪ§ЃЌДгЖјЗНБуЪЙгУМЦЪ§ЦїЕФИїЮЛжБНгЖдПЊЙиНјааПижЦЁЃ ЭЌЪБЃЌМЦЪ§ЦїЛЙПЩвдгУРДВњЩњЫљаша§зЊвђзгЕФRAMЕижЗЁЃИљОнИїМЖЕћаЮдЫЫуЫљаша§зЊвђзгЕФЙцТЩЃЌПЩвдРћгУМЦЪ§ЦїЕФИпЮЛВЙСуРДВњЩњВщевБэЕФЕижЗЁЃБШШчЃЌЖдгкЕквЛМЖЃЌвђЮЊашвЊдкзюЕЭЮЛЕквЛДЮГіЯж1ЪБЬсЙЉЃЌЕкЖўДЮГіЯж1ЪБЬсЙЉЃЌЁЃЌвдДЫРрЭЦЃЌжмЦкЮЊ128ЃЌЫљвдПЩвдЪЙгУМЦЪ§ЦїЕФЕЭЦпЮЛзїЮЊЕижЗЁЃЖдгкЕкЖўМЖЃЌгЩгкЫљашвЊЕФЕижЗЮЊХМЪ§ЃЌПЩвдгЩМЦЪ§ЦїЕФ[6ЃК1]КЭзюЕЭЮЛжУOВњЩњЁЃБэlЮЊ8ЕуЪБЪЙгУШ§ЮЛМЦЪ§ЦїЪфГіа§зЊвђзгЕФЕижЗЧщПіЁЃ 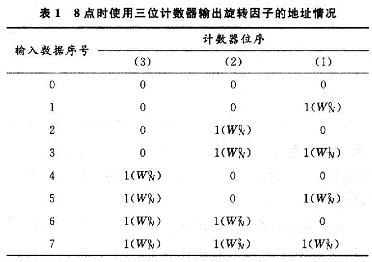 ПижЦКЭЕижЗВњЩњФЃПщЕФЗТецНсЙћШчЭМ5ЫљЪОЃЌЦфжаselДњБэПЊЙиПижЦЃЌaddrДњБэВњЩњЕФЕижЗЁЃ 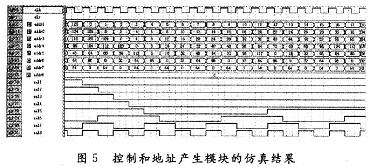 3ЃЎ2 ЕћаЮдЫЫуФЃПщ ЕћЫуФЃПщгЩвЛИіИДЪ§МгЗЈЦїЃЌвЛИіИДЪ§МѕЗЈЦїКЭвЛИіа§зЊвђзгЕФИДЪ§ГЫЗЈЦїЙЙГЩЃЌШчЭМ6ЫљЪОЁЃ 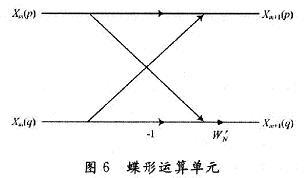 а§зЊвђзгГЫЗЈЦїЭЈГЃгЩ4ДЮЪЕЪ§ГЫЗЈКЭ2ДЮМгЃЏМѕЗЈдЫЫуЪЕЯжЃЌЕЋвђЮЊcosКЭsinЕФжЕПЩвддЄЯШДцДЂЃЌЭЈЙ§ЯТУцЕФЫуЗЈПЩвдМђЛЏИДЪ§ГЫЗЈЦїЃК ЃЈ1ЃЉДцДЂШчЯТШ§ИіЯЕЪ§ЃКCЃЌC+SЃЌC-S ЃЈ2ЃЉМЦЫуЃКE=X-YКЭZ=C*E=C*ЃЈX-YЃЉ ЃЈ3ЃЉгУR=ЃЈC-SЃЉ*Y+ZЃЌI=ЃЈC+SЃЉ*X-ZЃЌ ЕУЕНашвЊЕФНсЙћЁЃ етжжЫуЗЈЪЙгУСЫ3ДЮГЫЗЈЃЌ1ДЮМгЗЈКЭ2ДЮМѕЗЈЃЌЕЋЪЧашвЊЪЙгУДцДЂ3ИіБэЕФROMзЪдДЁЃ ЩшМЦжаЪ§ОнЕФЪфШыЮЊ16ЮЛИДЪ§ЃЌЫљвдНЋа§зЊвђзгcos(2kІаЃЏN)ЃЌsin(2kІаЃЏN)СПЛЏГЩДјЗћКХЪ§ЕФ16ЮЛЖўНјжЦЪ§КѓЃЌДцДЂЕНROMжаЃЌгЩгкжЕгђВЛЭЌЃЌашвЊзЂвтC+SКЭC-SЕФБэвЊБШCБэЖр1ЮЛОЋЖШЁЃ дЫЫуКѓЕФНсЙћашвЊГ§вдСПЛЏЪБГЫвдЕФБЖЪ§16b011111llllllllllЁЃОпЬхЪЕЯжЪБгЩгкГ§ЗЈдЫЫудкFPGAЦїМўашвЊЯћКФНЯЖрЕФзЪдДЃЌЩшМЦжаВЩгУЖўНјжЦЪ§вЦЮЛЕФЗНЗЈРДЪЕЯжГ§ЗЈдЫЫуЁЃЮЊСЫЗРжЙЪ§ОнвчГіЃЌЩшМЦЖдЪфГіНсЙћГ§вд2ЁЃЭМ7ЮЊЕћаЮдЫЫуФЃПщЕФRTLМЖНсЙЙЭМЁЃ 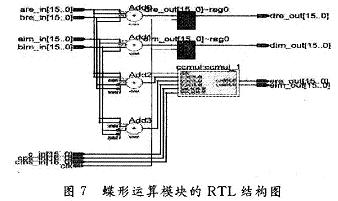 3ЃЎ3 ЕЙађЪфГіФЃПщ гЩЦЕгђГщШЁЕФЛљ-2ЫуЗЈПЩжЊЃЌдЫЫуНсЙћашвЊЕЙађЪфГіЁЃПЩвдЯШНЋНсЙћДцДЂЕНRAMжаЃЌШЛКѓЪЙгУOЁЋ255ЕФЖўНјжЦЪ§ЕЙађВњЩњRAMЖСШЁЕижЗЃЌвРДЮНЋНсЙћЖСГіЃЌЦфжаЪЕЯжвЛИі8ЮЛЖўНјжЦЪ§ЕЙађЕФЫуЗЈШчЯТЃК (1)НЋ8ЮЛЪ§зжЕФЯрСкСНЮЛНЛЛЛЮЛжУЃЛ (2)НЋЯрСкЕФСНЮЛПДзї1зщЃЌЯрСкСНзщНЛЛЛЮЛжУЃЛ (3)НЋЯрСкЕФ4ЮЛПДзї1зщЃЌЯрСкСНзщНЛЛЛЮЛжУЁЃ ОЙ§етбљЕФНЛЛЛЮЛжУКѓЃЌЪфГіМДЮЊдРД8ЮЛЖўНјжЦЪ§ЕФЕЙађЁЃ ОйР§Ждгк8ЮЛЖўНјжЦЪ§10110110РДЫЕЃЌЕквЛДЮНЛЛЛЮЛжУЕФНсЙћЪЧ01111001ЃЌЕкЖўДЮНЛЛЛЮЛжУЕФНсЙћЪЧ11010110ЃЌзюКѓНЛЛЛЮЛжУЕФНсЙћЪЧ01101101ЁЃПЩМће§КУЪЧдРДЪ§зжЕФЕЙађЁЃ СэЭтЃЌгЩгкЩшМЦЕФЪЧСНТЗЪ§ОнЭЌЪБаДШыЃЌвЛТЗЪ§ОнЖСГіЃЌЫљвдЖСШЁЕФЦЕТЪЪЧаДШыЦЕТЪЕФ2БЖЃЌЪЙгУPLLЪЕЯждЪМЪБжгЕФЖўБЖЦЕЃЌгУРДЖСШЁRAMЁЃЕЙађФЃПщЗТецНсЙћШчЭМ8ЫљЪОЁЃ 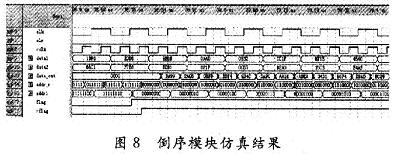 зюжеЩњГЩЕФFFTДІРэЦїФЃПщЭМШчЭМ9ЫљЪОЁЃ  4 ЗТецНсЙћ ИїМЖМфЪ§ОнЪБађЧщПіШчЭМ10ЫљЪОЃЌЩшМЦЕФFFTДІРэЦїЗТецНсЙћШчЭМ1lЫљЪОЁЃВЩгУвЛТЗНзЬнЕндіаХКХКЭСэвЛТЗЃКXXXXаХКХНјааЗТецЃЌЭЈЙ§гыMatlabМЦЫуНсЙћНјааЖдБШЃЌНсЙћЛљБОвЛжТЃЌПЩвдТњзуЯЕЭГвЊЧѓЁЃЯЕЭГзмЕФбгЪБгЩбгЪБзюДѓЕФЕквЛМЖОіЖЈЃЌЮЊЕквЛМЖдЫЫуЕФбгЪБМгЩЯЕЙађЪфГіЕФбгЪБЃЌзмЙВЪЧ(256+128)ЁСclkЃЌЯрЖдгквЛАуСїЫЎЯпНсЙЙ(256ЁСЖСШыжмЦк+7ЁС128ЁСЕћЫужмЦк+128ЁСЖСШыжмЦк)ЃЌЯЕЭГбгЪБДѓЮЊМѕЩйЁЃ 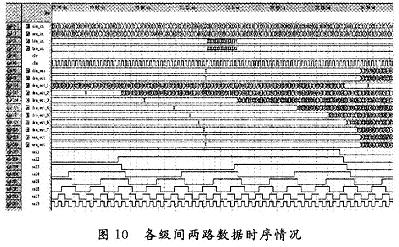 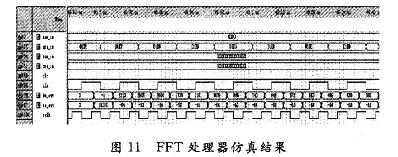 ЭЈЙ§ЗТецПЩжЊЃЌЯЕЭГзюДѓЦЕТЪгЩЕћаЮдЫЫуФЃПщЕФзюДѓЙЄзїЦЕТЪОіЖЈЁЃЪЙгУQuartusЂђШэМўЪБађЗТецКѓЃЌЕУЕНДІРэЦїЕФЙЄзїЦЕТЪЮЊ72 MHzЁЃ 5 Нсгя ЭЈЙ§ВЩгУвЦЮЛМФДцЦїСїЫЎЯпНсЙЙЃЌПЩвдгааЇЕиЬсИпFFTДІРэЦїжаЕћаЮдЫЫуЕЅдЊЕФаЇТЪЃЌМѕЩйМФДцЦїЕФЪЙгУЪ§СПЃЌВЂЧвМђЛЏСЫЕижЗПижЦЃЌЬсИпДІРэЦїЕФЙЄзїЦЕТЪЃЌОпгаСМКУЕФПЩРЉеЙадЃЌЭЌЪБПЩвдЪЕЯжСНТЗЪ§ОнЕФЭЌЪБЪфШыЃЌДгЖјдіДѓСЫвЛБЖЕФЪ§ОнЭЬЭТСПЁЃЖдгкЙЄзїЦЕТЪвЊЧѓНЯИпЃЌЪ§ОнЭЬЭТСПНЯДѓЃЌгШЦфЖдгкашвЊСНТЗЪ§ОнЪфШыЕФГЁКЯЃЌБШШчСНЬьЯпЕФMIMO-OFDMЯЕЭГЃЌОпгаКмДѓЕФЪЕгУМлжЕЁЃ |





ЭјгбЦРТл