
РћгУЖрФкКЫДІРэЦїЕФВЂааБрГЬЙІФмЪЕЯжЪгЦЕДњТызЊЛЛ
ЗЂВМЪБМфЃК2009-3-4 11:33
ЗЂВМепЃКгнУРШЫ
|
ЪгЦЕДњТызЊЛЛЪЧжИДгвЛжжбЙЫѕЪгЦЕИёЪНзЊЛЛЮЊСэвЛжжбЙЫѕЪгЦЕИёЪНЃЌЭЈГЃЯШвЊАбФГжжИёЪННтТыЮЊдЪМЪгЦЕжЁЃЌШЛКѓгУаТЕФИёЪНжиаТБрТыЁЃдкаэЖргІгУжаИпаЇЕФДњТызЊЛЛжСЙиживЊЁЃР§ШчЃЌЮЊСЫжЇГжЪгЦЕЕуВЅЪ§ОнСїЃЌЪгЦЕЪ§ОнвЊвдФГжжжїСїИёЪНДцДЂЦ№РДвдНкЪЁПеМфЃЌЕЋБиаыжЇГжжкЖрВЛЭЌЕФЙлПДЩшБИКЭНтТыЦїЁЃЮЊСЫзіЕНетвЛЕуЃЌашвЊдкЪ§ОнЗЂЫЭЧАвдЪЕЪБЛђепПьгкЪЕЪБЕФЫйЖШНјааДњТызЊЛЛЁЃдкЪгЦЕНкФПжЦзїНзЖЮНјааЪгЦЕБрМЪБЃЌвВБиаыЖдЪгЦЕЪ§ОнНјааНтТыЁЂаоИФКЭжиаТБрТыЁЃдкЦеЭЈМвЭЅЃЌЮЊСЫФмдкМвгУЪгЦЕЗўЮёЦїЩЯЪЙгУЪгЦЕЃЌЪгЦЕЪ§ОнПЩФмвВашвЊзЊЛЛВХФмЪЪгІЗўЮёЦїжЇГжЕФИёЪНЁЃжЇГжИпЧхЪгЦЕЕуВЅвЊЧѓИпадФмЕФДњТызЊЛЛЁЃRapidMindЙЋЫОПЊЗЂЕФШэМўПЊЗЂЦНЬЈРћгУЭГвЛЕФВЂааБрГЬФЃаЭГфЗжЗЂЛгИїжжЖрФкКЫДІРэЦїЕФадФмЁЃЭЈЙ§дкRapidMindЦНЬЈЩЯНЈСЂДњТызЊЛЛЦїЃЌгІгУГЬађШчНёФмдЫаадкЖржжДІРэЦїЩЯЃЌАќРЈCPUЁЂGPUКЭCell BEЃЌВЂЧвЛЙФмЭЈЙ§РЉеЙЪЪгІЮДРДЖрФкКЫ(КЭжкФкКЫ)ДІРэЦїЛЗОГЁЃ ДњТызЊЛЛЦїздШЛашвЊжЇГжИїжжЪгЦЕбЙЫѕИёЪНЁЃШЛЖјЃЌаэЖрИёЪНдкЪЕЯжЫќУЧЫљашЕФдЫЫуРраЭЗНУцгаКмЖрЯрЫЦадЁЃСэЭтЃЌБрТыЦїЭЈГЃвЊБШНтТыЦїЙѓЕУЖрЁЃвЛАувЛжжЪгЦЕБъзМНіЙцЖЈСЫбЙЫѕЪ§ОнСїжаДцДЂЪВУДРраЭЕФЪ§ОнвдМАНтТыЦїИУдѕбљвыТыЃЌВЂВЛЙцЖЈБрТыЦїШчКЮДгдЪМЪфШыЪ§ОнСїжаЬсШЁашвЊЕФаХЯЂЁЃ ЭЈГЃвЛжжбЙЫѕЪгЦЕИёЪНВЛНівЊЧѓЪЕЯжЖдЕЅжЁЕФбЙЫѕЃЌЖјЧввЊЧѓЪЙгУЪгЦЕађСажаЕФЯрСкжЁЪЕЯжЖджаМфжЁЕФдЄВтЁЃЮЊСЫФмДгДЋЪфВњЩњЕФШЮКЮДэЮѓжаЛжИДЪ§ОнЃЌВЂдЪаэгУЛЇДгЪгЦЕађСажаМфЮЛжУПЊЪМНтбЙЫѕЃЌгааЉжЁЪЧдкВЛВЮПМЦфЫќжЁЕФЧщПіЯТНјаабЙЫѕЕФЁЃ ЕЅжЁбЙЫѕ ЕЅжЁбЙЫѕгаЕуРрЫЦгкЦеЭЈЕФЭМЯёбЙЫѕЃЌЭЈГЃАќКЌСЫЕНВЛЭЌЛљДЁжЁЕФзЊЛЛЃЌШчЪЙгУВЛЭЌЦЕТЪКЭЗНЯђЕФгрЯвБфЛЛ(РыЩЂгрЯвБфЛЛЛђDCT)ЃЌЛђаЁВЈБфЛЛЁЃетжжзЊЛЛЭЈГЃзїгУгкПщЃЌВЂЧвДгЪ§бЇЩЯПЩОЋМђЕНПщжаЯёЫиЩЯЕФвЛзщЕуЛ§(ЫфШЛвЛаЉЛљБОКЏЪ§дЪаэРэТлЩЯИќПьЕФвђЪ§ЗжНт)ЁЃзЊЛЛКѓЕФЯЕЪ§дйОЙ§СПЛЏЩОГ§ФЧаЉЖдЭМЯёПЩЪгЮогУЕФаХЯЂЃЌаЮГЩвЛЗљНќЫЦЕФЭМЯёЃЌзюКѓЪЙгУБрТыЦїБрТыШЅГ§Ъ§ОнжаШЮКЮВаСєЕФШпградЁЃ ЩЯЪізЊЛЛЕФФПЕФВЛНіЪЧЭЈЙ§НЋЭМЯёжаЕФФмСПМЏжаЮЊИќаЁЕФвЛзщЪ§зжЖјЪЙДњТыЦїБфЕУИќгааЇТЪЃЌЖјЧвдЪаэСПЛЏЦїЯджјЕиШЅГ§ИажЊЩЯВЛФЧУДживЊЕФаХЯЂЁЃР§ШчЃЌDCTОЭЛсЖдЭМЯёЕФИпЦЕКЭЕЭЦЕГЩЗжНјааЗжЮіЁЃгЩгкШЫблЖдИпЦЕЪБЕФСПЛЏЮѓВюВЛЩѕУєИаЃЌвђДЫетаЉЦЕТЪЕФСПЛЏПЩвдДжЗХвЛаЉЁЃСэЭтЃЌдкЩЯЪібЙЫѕВНжшжЎЧАЭЈГЃЯШвЊДгССЖШжаЗжРыГіЩЋЖШ(беЩЋ)КЭНЋЩЋЖШЧЗВЩбљЕННЯЕЭЗжБцТЪЃЌвђЮЊШЫблЖдССЖШБпдЕНЯУєИаЃЌЕЋЖдЩЋЖШБпдЕВЛЬЋУєИаЁЃ вЛаЉНЯИДдгЕФбЙЫѕИёЪНЛЙжЇГжИљОнПеМфЯрСкЕФПщЖдвЛаЉЭМЯёПщзїГідЄВтЁЃбЁдёФФИіПщгУгкдЄВтМЋОпЬєеНадЃЌЖјЧвжЇГжНтТыЦїжаЕФБивЊХХађдкВЂааЯЕЭГжавВЯрЕБИДдгЁЃШЛЖјЃЌШчЙћПщЕФФкШнФмЙЛБЛзМШЗдЄВтЃЌФЧУДЖдИУПщбЙЫѕЪБжЛашБрТыдЄВтжЕКЭЪЕМЪжЕжЎМфЕФ(ЩйСП)ВювьЁЃ ШчДЫЯъЯИЕиНщЩмЕЅжЁЭМЯёбЙЫѕЕФдвђЪЧЃЌЪЕМЪЩЯзїЮЊБрТыЙ§ГЬЕФвЛВПЗжЃЌЮоТлЪЧПщЛЙЪЧЕЅжЁбЙЫѕ/НтбЙЫѕЖМгаБивЊЁЃЬиБ№ЪЧжаМфжЁ(Ъ§ОнСїжаЕФДѓВПЗжжЁ)ЙРМЦЃЌЫќЪЧЭЈЙ§ШкКЯКЭЛьКЯЪ§ОнСїЧАКѓЗЂЩњЕФжЁЁЂШЛКѓДгЪфШыЪ§ОнжаМѕШЅетИіШкКЯКѓЕФжЁЁЂзюКѓбЙЫѕВювьЭМЯё(вЛАуЪЙгУРрЫЦгкЕЅжЁБрТыЦїЕФБрТыЦї)ЪЕЯжЕФЁЃЖдетжжШкКЯЕФЙРМЦБЛГЦЮЊдЫЖЏЙРМЦЃЌЪЧБрТыЙ§ГЬжадЫЫуСПзюДѓЕФВНжшжЎвЛЁЃ ШЛЖјдкНтТыЦїжаЃЌдЪМЕФдДЪ§ОнжЁЪЧУЛгаЕФЃЌжЛгаНтбЙЫѕКѓЕФжЁЁЃвђДЫЃЌетжжШкКЯвЊЧѓЭМЯёФмдкНтТыЦїжЎЧАЛЙдЁЃвђДЫЫќУЧВЛНіБиаыдкБрТыЦїжабЙЫѕЃЌЖјЧвашвЊБЛНтбЙЫѕЁЃетжжЖдЧАУцбЙЫѕЕФЪ§ОнНјааНтбЙЫѕЕФашЧѓНЋЕМжТЪ§ОнЕФвРРЕадЃЌВЂгАЯьЕНдкОпгаВЛЭЌДцДЂЦїЯЕЭГЕФДІРэЦїжЎМфШчКЮВЂааЪЙгУКЭЗжХфБрТыЦїЁЃ ЪгЦЕађСажаЕФЭМЯёзщ(GOP)жаЕФвЛаЉжЁ(IЃЌжЁФкБрТыжЁ)ЪЙгУЕЅжЁбЙЫѕЫуЗЈНјааБрТыЃЌЕЋЛљгкдЫЖЏЙРМЦЕФжЁМфдЄВтБЛгУРДИФНјжЁФкжЁМф(ЫЋЯђдЄВтБрТыжЁBЃЌЧАЯђдЄВтБрТыжЁP)ЕФбЙЫѕЁЃжЛгадЄВтжЁКЭЪЕМЪжЁжЎМфЕФВювьжЕашвЊБЛбЙЫѕЁЃгЩгкBжЁКЭPжЁЪЧИљОнIжЁЕФНтбЙЫѕАцБОдЄВтГіРДЕФЃЌвђДЫгаБивЊзїЮЊБрТыЙ§ГЬЕФвЛВПЗжЖдIжЁНјаабЙЫѕКЭНтбЙЫѕЁЃ 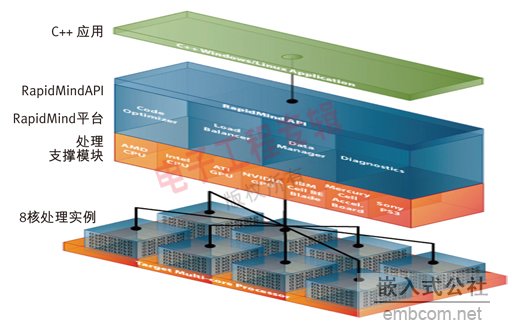 ЭМ1ЃКRapidMindЪЧвЛИіПЊЗЂКЭдЫааЪБМфЦНЬЈЃЌЫќжЇГжФмГфЗжРћгУЖрФкКЫДІРэЦїЕФЕЅЯпГЬПЩЙмРэгІгУГЬађЁЃПЊЗЂШЫдБПЩвдгУБъзМЕФC++гябдБраДДњТыЃЌRapidMindЦНЬЈдђПЩвдНЋетаЉДњТыдкЖрИіФкКЫМфЁАВЂааРћгУЁБЁЃ дЫЖЏЙРМЦ дЫЖЏЙРМЦЪЧКмгаМлжЕЕФЁЃвЛАуашвЊЗЂЯжНЋЯёЫиДгЪфШыЭМЯёжаЕФвЛИіЮЛжУПцБДЕНШкКЯКѓЕФЭМЯёЩЯЕФетжжШкКЯЃЌвдБуШкКЯКѓЕФЭМЯёгыИУжЁЪЕМЪЭМЯёМфЕФВювьОЁПЩФмаЁЁЃЪзЯШЃЌЯёЫиПщжЎМфЕФЯрЫЦаджИБъашвЊБЛЖЈвхЃЌЭЈГЃЪЧSSD(ВюжЕЦНЗНКЭ)ЛђSSA(ОјЖдВюжЕКЭ)ЁЃШЛКѓЪЙгУетжжЯрЫЦаджИБъВтЪдИїИіКђбЁдДПщЕФЮЛжУЃЌвдШЗЖЈСМКУЕФЦЅХфЁЃ гаСНЕуашвЊзЂвтЁЃЕквЛЃЌШчЙћгаНЯЧПЕФдЫЫуФмСІЃЌФЧУДПЩвдВтЪдНЯЖрЕФКђбЁЮЛжУЃЌДгЖјПЩФмевЕНИќКУЕФЦЅХфЃЌВЂЬсИпбЙЫѕТЪЁЃПЩвдгУдЫЫуФмСІЕФдіЧПРДНЕЕЭДјПэвЊЧѓЃЌЗДжЎврШЛЁЃЦфДЮЃЌЯрЫЦаджИБъЪЧЗЧЯпадЕФЁЃетвтЮЖзХЪЙгУЖрЗжБцТЪЕШММЧЩРДМгПьЯрЫЦадЦЅХфЫйЖШЪЧВЛКЯЪЪЕФЁЃЕЭЗжБцТЪЪБЕФзюМбЦЅХфВЛвЛЖЈЪЧИпЗжБцТЪЪБЕФзюМбЦЅХфЁЃ етРягаСНИіЛљБОЕуЃКЪ§ОнЮЛжУКЭВЂааЬхЯЕЁЃЪзЯШЃЌGPUЪЧОпгаКмИпадФмЕФДІРэЦїЃЌЕЋФПЧАЮЛгкPCIExpressПЈЩЯЃЌетаЉПЈгаздМКЕФДцДЂЦїЁЃвђДЫЮЊСЫбЙЫѕЪгЦЕСїЃЌЪ§ОнашвЊДЋЫЭЕНЪгЦЕПЈЩЯЕФДцДЂЦїжаЃЌШЛКѓНЋбЙЫѕНсЙћДЋЛиРДЁЃетвЛЙ§ГЬашвЊвдСїЕФаЮЪНЭъГЩЃЌЖјетжжСїЪНДІРэгыдЫЫуЫцЪБНЛЕўЃЌвђДЫЪ§ОнДЋЫЭВЛЛсГЩЮЊЦПОБЁЃRapidMindЦНЬЈе§ГЃЧщПіЯТПЩздЖЏЙмРэЪ§ОнЃЌЖјЧв(ФмдкФкВПгВМўAPIжЇГжЕФЕиЗН)ЬсЙЉЩюВуЗжЮіЙІФмРДЙмРэетжжжиЕўЪНСїДІРэЁЃGPUДцДЂЦїМмЙЙЕФЦфЫќвтвхЛЙдкгкЛЅЯрвРРЕЕФвЛЯЕСаВНжшгІОЁПЩФмБЃГждкЯрЭЌЕФДцДЂЦїПеМфжаЁЃ зюДѓГЬЖШЕФМгЫй ЭЈГЃдкПМТЧвЛИігІгУЪЧЗёФмБЛМгЫйЪБЃЌШЫУЧЪзЯШЛсЗжЮігІгУГЬађЕФИїИіЕЅдЊЃЌХаЖЯУПИіЕЅдЊЩЯашЛЈЖрГЄЪБМфЃЌВЂРћгУАЂФЗДяЖћЖЈТЩЙРМЦПЩФмЕФМгЫйГЬЖШЁЃ ОйР§РДЫЕЃЌПМТЧЕНФГИігІгУГЬађдкЕЅдЊAЩЯвЊЛЈ10%ЕФЪБМфЃЌдкЕЅдЊBЩЯвЊЛЈ75%ЕФЪБМфЃЌЕЅдЊCЩЯЛЈ5%ЕФЪБМфЃЌЕЅдЊDЩЯЛЈ10%ЕФЪБМфЁЃИУгІгУГЬађЕФСїГЬЪЧAдЫаавЛДЮЃЌШЛКѓBКЭCТжСїЖрДЮЗДИДдЫаа(ШЁОігкБЫДЫЙиЯЕ)ЃЌзюКѓВХЪЧдЫааDЁЃ ЭЌЪБМйЩшЕЅдЊAЙРМЦФмМгЫй1.5БЖЃЌBФмМгЫй20БЖЃЌCФмМгЫй2БЖЃЌDВЛФмзіШЮКЮМгЫйЁЃ етбљРэТлЩЯЕФзюДѓЪБМфЫѕЖЬжЕЪЧЃК 0.1/1.5+0.75/20+0.05/2+0.1/1=0.23 ЯрЕБгкМгЫй1/0.23(е§КУГЌЙ§4)БЖЁЃжЕЕУзЂвтЕФЪЧЃЌЫфШЛЕЅдЊB(75%ЕФдЫааЪБМф)ЕФМгЫйЯЕЪ§ДяЕНСЫКмДѓЕФ20ЃЌЕЋжЛгаЪЙЫљгаМгЫйВНжшЖдзмдЫааЪБМфЕФгАЯьБШНЯНгНќЕФЧщПіЯТВХФмШЁЕУзюКУЕФаЇЙћЁЃ ЪТЪЕЩЯЃЌШчЙћжЛЪЧвдBЮЊФПБъЃЌВЂЩшЗЈЪЙжЎЮоЯоМгЫйЃЌЕЋзмЕФадФмШдНЋЪмЯогкЦфгрЕЅдЊЁЃ ЪЙгУGPU НјвЛВНПМТЧЪЙгУGPUЁЃДѓМвПЩвдПДЕНBКЭCЪЧЗДИДНјааЕФЁЃШчЙћжЛЪЧдкGPUЩЯМгЫйBЃЌЖјШУCСєдкжїЛњЩЯЃЌФЧУДашвЊВЛЖЯЕиДгжїЛњФЧЖљРДЛиДЋЫЭЪ§ОнЃЌДгЖјбЯжигАЯьадФмЁЃвђДЫЃЌМДЪЙЕЅдЊCЕФМгЫйЗљЖШКмаЁЃЌЕЋИљОнАЂФЗДяЖћЖЈТЩЃЌЫќЖдзмЕФМгЫйаЇЙћгАЯьвВКмаЁЁЃЪТЪЕЩЯЃЌЮвУЧПЩФмвВЯыАбCвЦЖЏЕНGPUЩЯвдБмУтетаЉДЋЫЭЁЃ ете§ЪЧЪгЦЕБрТыЫљУцСйЕФОГПіЁЃМДЪЙдЫЖЏЙРМЦЪЧЪгЦЕбЙЫѕжазюАКЙѓЕФГЩЗжЃЌЮвУЧвВВЛФмКіТдЦфЫќвђЫиЃЌгШЦфЪЧЕЅжЁбЙЫѕКЭНтбЙЫѕЃЌвђЮЊдЫЖЏЙРМЦЕФЦфЫќНзЖЮЛЙашвЊетаЉНсЙћЁЃдкПМТЧетаЉвђЫиКѓЃЌНзЖЮгХЛЏЙЄзїСПОЭашвЊе§БШгкЫќЖдзмЬхадФмЕФгАЯьГЬЖШЁЃ RapidMindЦНЬЈ RapidMindЦНЬЈФмЙЛгУРДПьЫйЪЕЯжКЭВтЪдЫуЗЈЃЌВЂНЋЫуЗЈгІгУгкGPUЛђЪЕМЪЩЯЖрФкКЫЕФCPUЁЃШчЙћгаДѓСПвРИНгкЪ§ОнЕФЫуЗЈЕЅдЊЃЌRapidЪЕЯжОЭЯрЕБживЊЃЌвђЮЊЫљгаЕЅдЊБиаывЦЖЏЕНМгЫйЦїЕФДцДЂПеМфЃЌвдБмУтГіЯжЩЯЪіЪ§ОнАсвЦЮЪЬтЁЃШЛЖјЃЌИљОнЫќУЧЕФзмЬхгАЯьЃЌгХЛЏЫљгаетаЉЕЅдЊПЩФмВЛОпГЩБОаЇвцЃЌЛђУЛгаЬЋДѓзїгУЁЃгХЛЏЙЄзїШнвзЪЙДњТыИДдгЛЏЃЌВЂЧвИќФбЮЌЛЄЁЃ RapidMindЭЈЙ§ЙЋЙВЬиадМЏЯђЫљгажЇГжЕФгВМўФПБъЬсЙЉПЩвЦжВадЁЃНіЪЙгУетзщЙЋЙВЬиадвВПЩФмЛёЕУгХвьЕФадФмЁЃШЛЖјЃЌRapidMindЛЙЬсЙЉСЫЩюВуЛњжЦРДЗУЮЪЬиЪтгВМўЬиадЃЌетжжЩюВуЛњжЦЖдгХЛЏПЩФмгагУЃЌЕЋвВЛсгАЯьПЩвЦжВадЁЃвђДЫЭЦМіЕФзіЗЈЪЧШэМўЯюФПЪзЯШжЛгУЙЋЙВЬиадЪЕЯжЫљгаБивЊЕФЕЅдЊЃЌШЛКѓ(дкЪЕЯжЭъећЙІФмКѓ)ЖдЕЅдЊНјааЦЪЮівдШЗЖЈЦПОБМАзюгаПЩФмЕФИФНјжЎДІЃЌзюКѓЕїећЬиЪтЕЅдЊЃЌПЩФмЕФЛАЕїећгІБЃГждкФкКЫПЩвЦжВЙІФмМЏжаЁЃШчЙћгаБивЊНјааЬиЪтгВМўЕФЩюВуЗжЮіЃЌЪЙгУRapidMindЕФЬсШЁЙІФмПЩвдИєРыЫќЕФгАЯьЃЌдЪМЕФФкКЫЬиадВЮПМЪЕЯжвВПЩвдгУгкЪЕЯжПЩвЦжВадЁЃ |





ЭјгбЦРТл