
Ν§–χ Β ±–≈Κ≈¥ΠάμΤςΒΡ–‘ΡήΖ÷Έω
ΖΔ≤Φ ±ΦδΘΚ2010-9-16 10:29
ΖΔ≤Φ’ΏΘΚtechshare
|
Ε‘”ΎΗ¥‘”、 Β ±–≈Κ≈Υψ «œΒΆ≥ΒΡ…ηΦΤ»Υ‘±ά¥Ϋ≤,Ήν―œΨΰΒΡΧτ’Ϋ «’κΕ‘ΗχΕ®»ΈΚΈ―Γ‘ώ“ΜΗωΉν”––ßΒΡ¥ΠάμΤς。“ρΈΣ¥ΠάμΤς–߬ “άάΒ”Ύ”Π”Ο,…φΦΑΒΫΫαΙΙΚΆ”Π”ΟΒ»ΗςΗωΖΫΟφ,“ρ¥Υ’έ÷–ΒΡΑλΖ®ΚήΡ―Ε®“εΚΆΤάΙά。”ΟΆ®≥Θ Ι”ΟΒΡΖΫΖ®ΤάΦέ¥ΠάμΤς,ΆυΆυΈσΒΦ»ΥΟ«。“ρΈΣΥϋ―ΎΗ«ΝΥ–μΕύ“άάΒ”Π”Ο≤Δ Ι ΒΦ –‘Ρήœ¬ΫΒ“ρΥΊ;‘Ύ≤ΜΆ§ΒΡ¥ΠάμΤς…œ÷¥––”Π”Ο,»ΜΚσΤάΙάΟΩΗω¥ΠάμΤς÷¥––ΒΡ ΒΦ –‘Ρή,’β÷÷ΖΫΖ®Ζ―”ΟΑΚΙσ、Μ®Ζ― ±Φδ,≤Μ«–Κœ ΒΦ 。 1 ¥ΠάμΤςΗ≈Ωω ADΙΪΥΨΒΡTigerSHARC DSP(ADSP-TS101S)ΚΆΡΠΆ–¬όΈΜΙΪΥΨPowerPCœΒΝ–¥ΠάμΤς¥ζ±μΝΥΜώΒΟΗΏ–‘ΡήΦΤΥψΡήΝΠΒΡ≤ΜΆ§ΫαΙΙΚΆΖΫΖ®。TigerSHARC¥ζ±μDSPΒΡ¥ΪΆ≥ΉωΖ®,ΥϋΨΏ”–ΒΆΩΣœζ、»ΖΕ®–‘ΚΆDMA“ΐ«φΒ»ΧΊΒψ,Ή®Ο≈”Ο”ΎΩΣΖΔ«Ε»κ Ϋ Β ±”Π”ΟœΒΆ≥,άΐ»γάΉ¥ο、…υΡ…、ΈόœΏΆ®–≈ΚΆΆΦœώ¥Πάμ。œύΖ¥,PowerPC «“Μ÷÷RISC¥ΠάμΤς,”Ο”ΎΩΣΖΔΗ±ΤΜΙϊΦΤΥψΜζΉνΗΏ–‘ΡήΒΡG4ΙΛΉς’Ψ;ΨΏ”–ΚήΗΏΒΡ ±÷”ΤΒ¬ “‘ΦΑ«Ω¥σΒΡAltiVec ΗΝΩ¥Πάμ“ΐ«φ,‘Ύ“Μ–©«Ε»κ Ϋ–≈Κ≈¥Πάμ”Π”ΟΖΫΟφ“≤»ΓΒΟΝΥΚή¥σΒΡ≥…ΙΠ。 ΚήΟςœ‘,ΨΏ”–AltiVecΚΥΒΡPowerPC G4(74xx)ΨΏ”–ΫœΗΏΒΡΚΥ ±÷”ΥΌ¬ ”κ–‘Ρή。PowerPCΒΡΚΥ ±÷”ΥΌ¬ ΦΗΚθ «ΡΩ«ΑTigerSHARCΒΡ3.3±Ε(≤ΜΨΟΗϋΩλΑφ±ΨΒΡTigerSHARCΫΪΖΔ≤Φ)。AltiVecΚΥΟΩΗω÷ήΤΎ÷¥––ΒΞΧθ÷ΗΝν,ΟΩ128ΈΜœρΝΩΑϋΚ§4ΗωΕάΝΔΒΡ32ΈΜ ΐΨίΒΞ‘Σ,’βΨΆ «÷ΎΥυ÷ή÷ΣΒΡSIM-D(ΒΞ÷ΗΝνΕύ ΐΨί)ΫαΙΙ。Β±÷¥––“Μ¥Έ≥ΥΦ”(MAC) ΗΝΩ‘ΥΥψ ±,¥οΒΫΖε÷Β¥ΠάμΡήΝΠ,ΟΩ÷ήΤΎΩ…Άξ≥…8¥ΈΗΓΒψ≤ΌΉς。Ε‘”Ύ1GHzΒΡMPC7455,Ζε÷Β¥ΠάμΡήΝΠΩ…¥ο8000M¥Έ/sΗΓΒψ‘ΥΥψ。AltiVecΟΩ÷ήΤΎΡή÷¥––8¥Έ’ϊ ΐΜρΕ®Βψ≤ΌΉς,Ζε÷Β’ϊ ΐ‘ΥΥψΡήΝΠΈΣ8000MOPS(ΑΌΆρ¥Έ≤ΌΉς/s)。 œύΖ¥,TigerSHARC”–ΝΫΗωΕάΝΔΒΡ32»ρ¥ΠάμΤςΚΥ,Μρ≥ΤMIMD(Εύ÷ΗΝνΕύ ΐΨί)ΫαΙΙ。ΟΩΗωΦΤΥψΒΞ‘ΣΟΩ÷ήΤΎΡή÷¥––“Μ¥Έ≥ΥΖ®“‘ΦΑΚΆ≤νΖ÷‘ΥΥψ,Ε‘”Ύ300MHz ADSP-TS101SΟΩ÷ήΤΎΆξ≥…6¥ΈΗΓΒψ‘ΥΥψΜρ1800MFLOPSΖε÷Β‘ΥΥψΡήΝΠ。Β±÷¥––16ΈΜ ΐΨί‘ΥΥψ ±,TigerSHARCΩ…“‘άϊ”ΟΥϋΒΡ≥§±ξΝΩΧεœΒΫαΙΙ,Ζ÷άκΝΫΗωΕάΝΔ32ΈΜΦΤΥψΒΞ‘Σ≥…2ΗωΒΞΕάΒΡ16ΈΜSIMDΒΞ‘Σ,’β―υΟΩΗω≤ΌΉς‘ΎΝΫΗω ΐΨίΒΞ‘Σ,ΟΩΗω÷ήΤΎΩ…“‘‘ωΦ”≥§Ιΐ12¥ΈΒΡ≤ΌΉς。ΝμΆβ,TigerSHARC”–ΝμΆβΝΫΗωΉ®Ο≈ΒΡ16ΈΜ’ϊ ΐ“ΐ«φ,ΟΩΗω÷ήΤΎΩ…“‘‘ωΦ”≥§Ιΐ12¥ΈΒΡ≤ΌΉς,’β―υΟΩΗω÷ήΤΎΙ≤ΦΤ24¥Έ’ϊ ΐ‘ΥΥψ,7200MOPS。 2 I/O¥χΩμ”κ¥ΠάμΡήΝΠΒΡ±»÷Β ‘Ύ–μΕύ–≈Κ≈¥ΠάμΒΡ”Π”Ο÷–, ήœό”Ύ ΐΨίΝςΕχ≤Μ «¥ΠάμΡήΝΠ,“ρ¥ΥάμΫβ¥ΠάμΤςI/OΡήΝΠ“‘ΦΑ”κ¥ΠάμΤςΡΎΚΥΒΡ ΐΨίΫΜΜΜΒΡ–‘Ρή °Ζ÷÷Ί“Σ。ΚβΝΩΒΡ≥ΏΕ» «I/O¥χΩμ”κ¥Πάμ¬ ÷°±»(BPR),Φ¥¥ΠάμΤςΖε÷ΒI/O¥χΩμ(MB/s)≥ΐ“‘Ζε÷Β¥ΠάμΡήΝΠ(MFLOPS)。1B/FLOPΒΡBPR÷Η ΨΥϋ «“ΜΗω±»ΫœΤΫΚβΒΡΝ§–χ–≈Κ≈¥ΠάμΫαΙΙ,“βΈΕΉ≈¥ΠάμΤςΕ‘ΟΩΗωΗΓΒψ≤ΌΉςΡήΆξ≥…1B ΐΨί¥Ϊ δ。“ΜΗω¥ΠάμΤςΒΡBPRΟςœ‘ΗΏ”ΎΜρΒΆ”Ύ1B/FLOP,±μ Ψ’β÷÷ΫαΙΙ±»Ν§–χ–≈Κ≈¥ΠάμΤςΗϋ Κœ ΐΨίΝςΑα“ΤΜρΚσœρ ΐΨί¥Πάμ。 ΆΦ1Υυ ΨΈΣPowerPC¥ΠάμΤςΫΎΒψΖΫΩρΆΦ。¥”ΆΦ÷–Ω…“‘Ω¥≥ωΥυ”–¥ΠάμΤςI/OΒΡΖΟΈ ±Ί–κΆ®ΙΐMPCΚΆΩΊ÷ΤΤς/«≈–ΨΤ§÷°ΦδΒΡ64ΈΜ,128MHz(Ε‘”ΎMPC7455ΈΣ133MHz)œΒΆ≥ΉήœΏ。Ε‘”ΎMPC7410»ΈΚΈ“ΜΗω¥ΠάμΤςΒΡΉνΗΏI/O¥χΩμ «1000MB/s,Ε‘MPC7455ΒΡΉνΗΏI/O¥χΩμ «1064 MB/s。 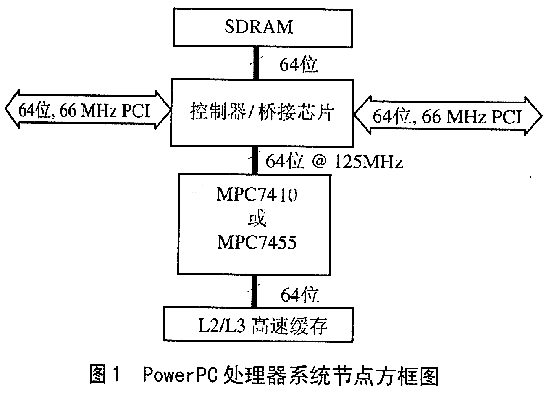 »ΜΕχ”…”ΎAltivecΚή«Ω¥σ,’β÷÷ “ΥΒΡΗΏ¥χΩμ≤Μ“ΜΕ®ΉήΡήΗζ…œΚΥΒΡΥΌΕ»。Β±MPC7455÷¥––8000MFLOPS ±, ΐΨίΑα“ΤΒΡΥΌΕ»ΫωΈΣ1064MB/s。BPR÷Β÷Μ”–0.13,ΥΒΟς’β÷÷ΫαΙΙΒΡI/O¥χΩμΚΆ¥ΠάμΡήΝΠ «≤ΜΤΫΚβΒΡ。“ρ¥Υ,PowerPCΕ‘Ωι¥Πάμ «”––ßΒΡ(±»»γΨΏ”–ΗΏΒΡΦΤΥψΚΆœύΕ‘ΒΆΒΡ ΐΨίΝςΕ·),ΒΪΕ‘Ν§–χΒΡ、ΗΏ ΐΨίΝςΕ·、Ϋœ…ΌΦΤΥψΒΡΝ§–χ–≈Κ≈¥Πάμ, «ΒΆ–߬ ΒΡ。 TigerSHARC «ΈΣΕύ¥ΠάμΤς…ηΦΤΒΡ,Εχ«“ΧαΙ©ΝΥ64ΈΜ、100MHzΙ≤œμœΒΆ≥ΉήœΏ“‘ΦΑ4Ηω8ΈΜ,250MHzΒΡLinkΩΎΉςI/OΚΆ¥ΠάμΤς÷°ΦδΒΡ ΐΨίΆ®–≈,¥ΊΉήœΏΒΡΑα“Τ ΐΨίΥΌ¬ ΈΣ800MB/s。 ΐΨίΜΙΩ…“‘Ά®ΙΐLinkΩΎ“‘50MB/sΥΌΕ»Ϋχ––¥ΪΥΆ,ΟΩΗωTigerSHRCΧαΙ©ΉήΒΡI/O¥χΩμΩ…¥ο1800MB/s。TigerSHARCΒΡBPR «0.1,±μΟςΕ‘Ν§–χΒΡ–≈Κ≈¥Πάμ «ΤΫΚβΒΡ”≈Μ·ΫαΙΙ。 3 –≈Κ≈¥ΠάμΡήΝΠΓΣcFFT 1024ΒψΗ¥ ΐFFT(cFFT) «ΤάΦέ–≈Κ≈¥Πάμ–‘Ρή Ι”ΟΉνΙψΖΚΒΡΜυΉΦ。‘≠“ρ»γœ¬:ΒΎ“Μ,«εΈζΕχ«“»ί“Ή“ΉΜ·;ΒΎΕΰ,‘Ύ¥σΕύ ΐ”Π”Ο÷–,Υϋ «ΉνΤ’±ι Ι”ΟΒΡ–≈Κ≈¥ΠάμΚ· ΐ;ΒΎ»ΐ,cFFTΩ…“‘ΤάΙά¥ΠάμΤςΒΡ ΐΨί¥ΠάμΡήΝΠΚΆ¥ΠάμΥΌΕ»。 ÷ΒΒΟΉΔ“βΒΡ «,”…”ΎPwerPCΒΡΥΌΕ»ΚΆ–‘Ρή,‘ΎΦΤΥψ1024ΒψcFFT”–Οςœ‘”≈‘Ϋ–‘;»ΜΕχTigerSHARC «ΈΣDSP≤ΟΦτΕ®÷ΤΒΡ,‘Ύ÷¥–––≈Κ≈¥ΠάμΥψΖ® ±ΜαΗϋΦ””––ß。’β «”…”Ύ–ΨΤ§ΨΏ”–ΦΪΚΟΒΡ ΐΨίΑα“ΤΒΡΡήΝΠ、ΤΫΚβ“‘ΦΑΒΞ÷ήΤΎ÷¥––Βϊ–Έ‘ΥΥψΡήΝΠ(≥ΥΖ®、Φ”Ζ®、≤νΖ÷)。AltiVecΚΥ±»TigerSHARCΚΥΩλ3.3±Ε,«±‘Ύ¥ΠάμΥΌ¬ «TIgerSHARCΒΡ4.4±Ε,»ΜΕχΥϋ÷¥––“ΜΗω1024ΒψcFFTΫω±»TIgerSHARCΩλ2.5±Ε。TigerSHARC‘Ύ9750÷ήΤΎΩ…“‘Άξ≥…CFFT‘ΥΥψ,ΕχPowerPC±Ί–κ”Ο13000Ηω÷ήΤΎ,“ρ¥Υ,‘Ύ÷¥––“ΜΗω1024ΒψCFFT ±,TigerSHARCΒΡΦΤΥψ–߬ ±»PowerPCΗΏ33%。ΜΜΨδΜΑΥΒ,»γΙϊ“‘œύΆ§ΒΡ ±÷”ΤΒ¬ ‘Υ––,TIgerSHARCΜα≥§ΙΐPowerPC 33%。ΥφΉ≈TigerSHARC ±÷”ΥΌ¬ ΦΧ–χΧα…ΐ,ΩΦ¬«≥…±ΨΚΆΙΠΚΡΒ»Έ Χβ,Β±Υϋ÷¥––FFT–≈Κ≈¥Πάμ”Π”Ο ±,ΥϋΒΡΡήΝΠ“Σœ‘Ος≥§ΙΐAltiVec。 4 Ν§–χΒΡcFFT ΤάΦέ¥ΠάμΤςΡήΝΠ ±,Ά®≥ΘΩΦ¬«ΥϋΒΡ¥ΠάμΡήΝΠ、I/O¥χΩμ,…θ÷ΝΥψΖ®ΒΡ÷¥––,ΒΪ“≈ΚΕΒΡ «’β–©ΤάΙάΟΜ”–“ΜΗωΡή’φ ΒΖ¥”≥ ΒΦ ”Π”Ο。 ΒΦ ”Π”Ο ±,’β–©“ρΥΊΆυΆυœύΜΞ”Αœλ。 ΐΨί±Ί–κΑ¥ΥυœΘΆϊΒΡΡ«―υΆ§ ± δ»κ、¥Πάμ、 δ≥ω。ΟΩΗω1024ΒψcFFT–η“Σ8KB ΐΨί δ»κ(1024Ηω―υ±ΨΓΝ2Ηω―υ±Ψ/IQΕ‘ΓΝ4Ή÷ΫΎ/―υ±Ψ )ΚΆ8KB ΐΨί δ≥ω,Ι≤16KBΒΡ ΐΨίΝς。Ά®Ιΐ±»Ϋœ1024ΒψcFFTΜυΉΦ”κ16KB≥ΥΜΐ”κ¥ΠάμΤςΒΡI/O¥χΩμ,ά¥ΨωΕ® « ήœό”Ύ¥ΠάμΤςΒΡΦΤΥψΡήΝΠΜΙ «I/O¥χΩμ。 Ε‘”ΎTigerSHARC,ΤδΉΦΒΡΒΙ ΐ±μ ΨΟΩΟκ÷”Ρή÷¥––30 769¥Έ1024ΒψcFFT,”…”ΎTIgerSHARC‘ΎΚσΧ®ΡήΑα“ΤΥυ–η“ΣΒΡ ΐΨί,–η“Σ”–504MB/sΒΡ ΐΨίΝς(30769/sΓΝ16KB),Ω…“‘±Θ÷Λ¥ΠάμΤςΒΡI/O¥χΩμ,“ρ¥ΥTigerSHARCΆξ»Ϊ Κœ»γ¥Υ”Π”Ο。 Ε‘”ΎMPC7410,1024ΒψCFFTΤδΉΦΤδ Β «ΈσΒΦ。“ρΈΣΥϋ≤ΜΡήΆ§ ±Αα“Τ ΐΨίΚΆΫχ–– ΐΨί¥Πάμ,Εχ«“‘Ύ¥Πάμ ±Φδάο,8KBΒΡ δ»κ ΐΨί±Ί–κΑα»κΗΏΥΌΜΚ¥φ(cache),8KBΒΡ δ≥ω ΐΨί±Ί–κΑα≥ωΒΡΗΏΥΌΜΚ¥φ(cache)。Αα“Τ ΐΨί–η“Σ‘ωΦ”16.4ΠΧsΒΡ¥Πάμ ±Φδ,÷¥––1024ΒψCFFTΙ≤–η“Σ38.4ΠΧs ΒΡ ±Φδ。ΩΦ¬«ΒΫ ΐΨίΒΡΉβ”Ο“Τ,1024ΒψCFFTΜυΉΦΒΡΒΙ ΐΈΣ1/38.4ΠΧs。 »ΜΕχΕ‘”ΎMPC7455ΒΡ«ιΩω≤ΜΆ§,ΜυΉΦΒΡΒΙ ΐœ‘ Ψ¥ΠάμΤςΡΎΚΥΟΩΟκ¥Πάμ76 923¥Έ1024ΒψCFFT,–η“Σ1260MB/s ΐΨίΝςΝΩ。ΨΓΙήPowerPCΫχ––¥ΠάμΒΡΆ§ ±ΡήΑα“Τ ΐΨί,ΒΪΥϋΒΡΖε÷Β¥χΩμΫωΈΣ1064MB/s,“ρ¥Υ‘Ύ’β“Μ”Π”Ο÷–¥χΩμ ήΒΫΝΥœό÷Τ。ΦΌ…ηΥϋΡήΝ§–χ±Θ≥÷Ζε÷ΒI/O¥χΩμ(cacheΙήάμΚΆΩΊ÷ΤΤςΤΩΨ±ΜαΟςœ‘Φθ–ΓI/O¥χΩμ,≤Μ‘Ύ±ΨΈΡΧ÷¬έΙήάμ),PMC7455ΟΩΟκΫωΡή÷¥––64941¥Έ1024ΒψcFFT(1064MB/s≥ΐ16KB/1024ΒψcFFT),Οςœ‘±»ΜυΉΦΒΡΒΙ ΐ“Σ–Γ。 5 ΑεΦΪ”Π”Ο »γ…œΥυ ω,ΡΩ«ΑΩ…ΜώΒΟΜυ”ΎΥυ”–¥ΠάμΤςcPCIΚΆVMEΉήœΏΒΡCOTSΑε。»ΜΕχ,Β±”κΑεΦΕ”Π”ΟœύΝΣœΒ ±,Μα¥σ¥σΗΡ±δ“‘…œΒΡΤάΙάΫαΙϊ。 “ρΈΣMPC7455¥χΩμ ήœό,ΑεΦΕΒΡΫαΙΙΜα‘ωΦ”I/OΒΡœό÷Τ,Ϋχ“Μ≤ΫΕώΜ·¥ΠάμΤςΝ§–χCFFTΒΡ–‘Ρή。≤ΜΩΦ¬«±≥ΑεΒΡ ΐΨίΝς,Ε‘”ΎPowerPCά¥Ϋ≤,ΡΩ«ΑΉνΚΟΒΡI/OΖΫ Ϋ «ΝΫΗω64ΈΜ/66MHz PMC,ΥΪ528 MB/s PMC,Ω…¥οΒΫΒΡ ΐΨίΝςΙ≤1056MB/s。’β“―Ψ≠–Γ”ΎMPC7455ΒΡ1064MB/sΖε÷ΒI/O¥χΩμ。 ΒΦ …œPMC¥οΒΫΝ§–χ、≥÷–χΒΡΆΧΆ¬¬ “≤ «≤ΜΩ…ΡήΒΡ。ΦΌ…η1056MB/s≥÷–χΒΡI/O¥χΩμ,PowerPCΑε≥÷–χ1024ΒψcFFTsΈΣΟΩΟκ64453¥Έ(1056MB/s±Μ16KB≥ΐ)ΓΣΓΣ≤Μ“άάΒ”ΎPowerPCΒΡ ΐΝΩΜρΥΌΕ»。 œύΖ¥,TigerSHARCΨΏ”–Ά®ΙΐlinkΩΎΩ…ά©’ΙΒΡI/O,ΆΦ2Υυ ΨΈΣΒδ–ΆΒΡ4ΗωTigerSHARC¥ΠάμΤςΒΡΫαΙΙΩρΆΦ。‘Ύ¥ΥάΐΉ”÷–,ΟΩΗω¥ΠάμΤς±Ί–κΙ≤œμ“ΜΗω¥ΊΉήœΏ¥χΩμ,ΟΩΗω¥ΠάμΤς Ι”Ο2ΗωLinkΩΎΉςΈΣ¥ΠάμΤςΦδΒΡ ΐΨί¥Ϊ δ,ΟΩΗωTigerSHARCΒΡΤδΥϋ2ΗωLink±Μ”ΟΉωI/O。’β―υΟΩΗω¥ΠάμΤςI/OΉή¥χΩμΨΆΦθ…Ό÷Ν700MB/s(LinkΩΎ2ΓΝ250MB/s+1/4ΓΝΙ≤œμ¥ΊΉήœΏ800MB/s)。»ΜΕχ,Ε‘”ΎΟΩΗω¥ΠάμΤς,‘ΎΉν¥σΝ§–χCFFTΥΌ¬ ΒΡ«ιΩωœ¬,TigerSHARC–η“Σ504MB/sΒΡ¥χΩμ。Υδ»Μ’β“ΜΥΌ¬ ‘ΎTigerSHARCΦΪœόΖΕΈß,ΒΪΑ―Ν§–χΒΡI/OΖ÷Ν―≥…LinkΩΎΚΆ¥ΊΉήœΏ“≤ «≤Μ«–Κœ ΒΦ ΒΡΉωΖ®。 ΒΦ …œ,Ε‘”ΎΝ§–χCFFTΒΡΉν¥σI/O ΐΨί¬ «500MHz,”…ΟΩΗωTIgerSHARCΒΡΝΫΗωLinkΩΎΧαΙ©。Κή–Γ¥χΩμΒΡœό÷ΤΫΒΒΆΝΥΝ§–χ1024ΒψcFFTΒΡ–‘Ρή,ΟΩΗωTigerSHARCΡή¥Πάμ30 517¥Έ。TigerSHARCΒΆΙΠΚΡ、–Γ≥Ώ¥γΚΆΙΠΡήΒΡΦ·≥…,ΡΩ«ΑΩ…ΒΟΒΫ¥ΊΉήœΏ(8Τ§TigerSHARC)6U cPCIΑεΩ®。8Τ§TigerSHARCΟΩΟκΡή÷¥––244 135¥ΈΝ§–χ1024ΒψCFFT‘ΥΥψ,ΦΗΚθ «άμœκPowerPCΑεΩ®ΒΡ4±Ε。 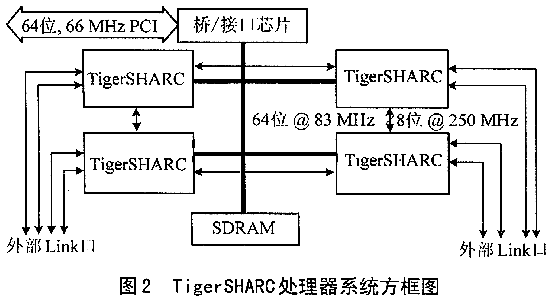 6 Ϋα¬έ Έ“Ο«Χ÷¬έΒΡΗς÷÷COTSΑεΒΡ”Π”Ο,¥ζ±μΝΥΝ§–χ Β ±–≈Κ≈¥Πάμ”Π”ΟΒΡ ΒΦ –‘Ρή。Ε‘”ΎΤδΥϋ“ρΥΊΒΡΖ÷Έω(»γ÷–Εœ、ΩΣΖΔΜΖΨ≥、DMAs、¥φ¥ΔΤςΒΡάϊ”Ο、CacheΙήάμ、Βγ‘¥Β»)≤Μ‘Ύ±ΨΈΡΧ÷¬έΖΕΈß。»γΙϊ”Π”ΟœΒΆ≥–η“Σ¥σΝΩΒΡΦΤΥψ、±»Ϋœ…ΌΒΡ ΐΨίΑα“ΤΚΆΥυΈΫΒΡΚσœρ ΐΨί¥Πάμ,”…”ΎΫœΗΏΒΡ ±÷”ΤΒ¬ ΚΆ«Ω¥σΒΡΡΎΚΥ,PowerPC «άμœκΒΡ―Γ‘ώ;Ζ¥÷°,Ε‘”Ύœώ≥…œώ、άΉ¥ο、…υΡ…ΚΆΦύΧΐΒ»”Π”ΟΒΡΝ§–χ、 Β ±–≈Κ≈¥Πάμ,”…”Ύ–η“Σ±»ΫœΗΏΒΡ ΐΨίΆΧΆ¬¬ ,TigerSHARC”ΠΗΟ « Ή―Γ。 |



Άχ”―Τά¬έ