
Linux下ColdFire片内SRAM的应用程序优化设计
发布时间:2010-8-18 10:59
发布者:lavida
|
本文以MP3解码器为例,介绍了一种在嵌入式Linux系统下配置使用处理器片内SRAM的应用方案,有效提高了代码的解码效率,降低了执行功耗。该方案不论在性能还是成本上都得到了很大改善。 1 硬件平台和软件架构 硬件平台采用Freescale公司的MCF5329EVB开发板。终端硬件包括ColdFire5329处理器、32 KB的片内SRAM、1 800×600矩阵LCD显示屏、9×3阵列矩阵键盘、I2S音频解码芯片、64 MB的SDRAM、10/100M以太网接口,以及3个UART接口。软件构架如图1所示,主要包括MP3解码器、音频驱动、键盘驱动和用户图形界面(GUI)等模块。采用μClinux作为操作系统。μClinux针对嵌入式应用的特点作了较大的简化和修改,支持多种文件系统和多任务处理,而且具有相对完整的网络体系协议,因而特别适合嵌入式应用。  2 MP3解码算法分析 本文选用MP3解码程序作为方案验证代码。MPEG-1/2 Audio Layer 3是专门针对音乐和语音数据设计的有损压缩算法。该算法的解码过程比较复杂,主要包括反向修正离散余弦变换(IMDCT)、逆量化、Huffman解码、子带综合等功能模块。读入一段MP3数据后,首先要检测数据流中的同步字,以确定一帧数据的开始;然后提取帧头信息,特别是解码所需要的一些参数,同时分离出帧边信息和主数据;之后对边信息数据解码得到Huffman解码信息和逆量化信息,再经过重新排序、立体声处理、反混叠处理、IMDCT变换和子带综合滤波器组后,就可以得到PCM输出。 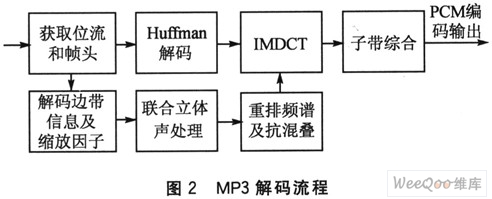 MP3解码流程如图2所示。大致分为两个阶段,即数据流控制阶段和数值计算阶段。数据流控制阶段包括帧同步、边带信息解码和Huffman解压缩等过程。其中,Huffman解压缩是对编码数据进行操作,其他过程则是对帧控制部分进行操作。 3 基于片内SRAM的优化设计方案 3.1 方案分析 SRAM指令执行速度要比DRAM快得多。Cold-Fire5329处理器内部集成了32 KB的SRAM,本设计方案将充分利用处理器片内SRAM来对解码程序进行优化。首先对源代码中的主要解码函数进行分析,如表1所列。可以看到驱动写函数(write)、子带综合(MPEGSUB_synthesis)、反向修正离散余弦变换(imdct_I)和快速离散余弦变换(fast_dct)对处理器资源消耗较大,几乎占用80%的解码时间。根据分析结果,分别把音频驱动程序和上述解码函数放进SRAM中执行,以提高流媒体解码器的执行速度,降低其对处理器资源的消耗。 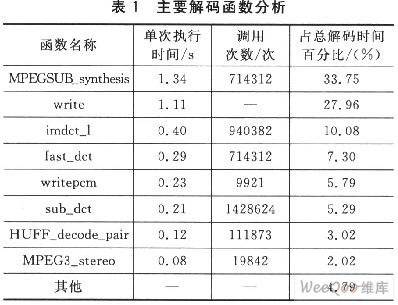 3.2 配置音频驱动程序到片内SRAM中执行 Linux操作系统把内核和运行在其上的应用程序分成两个管理层次,也就是常说的“内核态”和“用户态”。内核态具有较高的应用权限,可以控制处理器内存的映射和分配方式。音频驱动程序是系统内核的重要组成部分,工作在内核态,实现不断从用户空间解码文件中读取音频信息,以及驱动音频芯片播放声音等相关功能。通过修改μClinux-2.6内核代码,可以将音频驱动程序配置到片内SRAM中执行,主要通过修改系统链接文件来实现。系统链接文件用于将输入文件根据一定的规则合并成一个输出文件,并对符号与地址进行绑定。 为了在修改内核代码的同时不影响系统其他文件的正常运行,要在内核链接脚本中添加新的段区定义(.sramcode),指定该段区链接加载地址为处理器片内SRAM,并在.sramcode段区内定义代码段(.sramtext)和数据段(.sramdata),分别用于存储驱动中的代码和数据。对齐方式采用ALIGN(4),因为对32位微处理器来说,该对齐方式将有效减少处理器执行周期,提高执行效率。然后,使用2个指针_lsramcode和_lsramcodeend分别指向,sramcode段区的段首和段尾,具体实现如下:   完成对操作系统链接文件的修改之后,使用宏定义在音频驱动程序中把相关函数和数据分别指定链接到,sramcode代码段和数据段,并由copy函数把相关函数复制到SRAM中执行。编译、链接完成后,可以在系统内核存储映射文件Sys-tem.map中查看驱动函数和数据在内存中的地址。图3显示了音频驱动函数在处理器片内SRAM中的映射地址。  3.3 配置实时数据和函数到片内SRAM中执行 把用户空间的实时数据和函数放置到片内SRAM中执行,由于处理器可以直接从片内SRAM中存取数据和指令,减少了处理器存取数据和指令的周期,提高了程序的执行效率。首先,放置实时数据到处理器片内SRAM中。通过S_malloc和S_free函数来实现:S_malloc用来申请处理器内存空间,S_free用来对这一申请的空间进行释放。为了灵活使用定义的S_malloc和S_free函数,需要定义一个结构体和地址指针:  然后,通过动态内存分配方式可以把MP3解码程序中的实时数据放入处理器内存中执行。加载函数到SRAM中与加载实时数据不同,需要通过指针和枚举变量来实现。首先通过一个宏定义设置每个函数大小为4 KB,并使用枚举变量为函数分配处理器片内SRAM执行的起始地址。  SRAMFUNC2=SRAM_BIG_FUNC1+BIG_FUNC_SIZE,…}; 在定义完函数运行时加载的存储地址之后,把MP3解码程序中的MPEGSUB_synthesis和imdct_1等函数通过字符串拷贝的方式复制到处理器片内SRAM中执行,经过编译、链接这些函数在执行时将会加载到相应的SRAM单元块中。这样就减少了处理器执行解码函数所需的时间,提高了程序的执行效率。 4 性能测试与分析 为了验证基于处理器片内SRAM的优化设计方案,我们在MCF5329EVB开发板上对经该方案优化过的MP3解码器进行了验证和测试。 首先,进行功能测试,应用MPEG组织推荐的测试码流(128 kb/s,44.1 kHz)。选用一段音频test.mp3,分别用标准浮点解码器和本文设计的音频解码器进行本地解码测试,并对其解码波形进行比较分析。从图4的波形比较可以看到,经过本方案优化设计的解码器解码波形与标准浮点解码器基本无差别。经人耳测试,无法辨别出两者解码输出的差别。所以,从功能上讲本文设计的基于片内SRAM的应用程序优化方案是可行的。  其次,进行性能测试。在测试平台上分别对优化前后解码器的MIPS消耗数和空间消耗量进行比较分析,如表2所列。 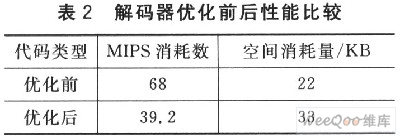 优化前,解码器MIPS消耗数为68 MIPS@240MHz;优化后,解码器MIPS消耗数为39.2 MIPS@240 MHz。在硬件条件允许的情况下,消耗的内存虽然有一定的增加,但是经过本文方案优化后,解码效率得到了很大的提高。 结 语 本文提出了在嵌入式Linux操作系统下基于处理器片内SRAM的应用程序优化设计方案。以MP3解码器为例,通过从配置音频驱动程序、实时数据和函数到处理器片内SRAM中执行来对解码器进行优化设计,并在ColdFire5329开发平台上成功实现该方案。优化后的MP3播放器不仅解码效率高,而且音质好,完全可以在中低端处理器上实现实时播放,使低性能CPU处理复杂应用程序成为可能。该方案有效地提高了应用程序的执行效率,降低了功耗,对嵌入式Linux应用产品开发有着重要参考价值。 |



网友评论