
вЛжжTCP/IPаЖдив§ЧцМмЙЙЕФгІгУ
ЗЂВМЪБМфЃК2010-8-2 11:55
ЗЂВМепЃКlavida
|
tcp/ipЪЧвЛзщШЋЪРНчЙуЗКгІгУЕФавщЃЌВЛНіНігУгкinternetЃЌаэЖрЫНгаЭјТчвВЪЙгУtcp/ipзїЮЊЦфавщзщЃЌаэЖргВМўЩшМЦЖМЪЧЛљгкtcp/ipЛђепЯрЙиЕФавщРДПЊЗЂЕФЁЃДЋЭГЕФtcp/ipДІРэЭјТчЪ§ОнДЋЪфЙ§ГЬжаЃЌвЊеМгУДѓСПЕФжїЛњcpuзЪдДЃЌЮЊСЫМѕЧсcpuЕФбЙСІЃЌвЛжжНаtoe(tcp/ip offload engineЃЌtcp/ipаЖдив§Чц)ЕФММЪѕгІдЫЖјЩњЁЃtoeММЪѕЖдtcp/ipавщеЛНјааРЉеЙЃЌЪЙВПЗжtcp/ipавщДгcpuзЊвЦЕНtoeгВМўЃЌМѕЧсcpuЕФИКЕЃЁЃ toeММЪѕ ЫљЮНаЖдиЪЧжИНЋcpuЩЯЕФМЦЫуЛђДІРэзЊвЦЕНзЈУХЕФгВМўЕЅдЊЩЯНјааЁЃдкФПЧАЕФвдЬЋЭјЛЗОГжаЃЌtcp/ipЕФДІРэЖМЪЧЭЈЙ§ШэМўдкжааФДІРэЦїЩЯЪЕЯжЕФЃЌЕМжТЯЕЭГдкавщДІРэЁЂжаЖЯДІРэЁЂЪ§ОнПНБДЗНУцУцСйРЇФбЁЃРћгУtoeММЪѕЖдtcp/ipаЖдидђМђЛЏСЫЪ§ОнАќЕФДІРэЃЌШчЭМ1ЫљЪОЃЌtoeНЋtcp/ipавщДгcpuжавЦЕНгВМўжаДІРэЁЃдкжїЛњжаАВзАКЭtoeЭЈаХЕФЧ§ЖЏКѓЃЌФкКЫКЭгУЛЇЕФгІгУЖМПЩвджБНгКЭtoeЭЈаХЃЌетбљОЭПЩвдЪЙжїЛњcpuРДДІРэБ№ЕФЙЄзїЁЃtoeдкНгЪеЕНЭјТчЩЯЕФЪ§ОнКѓЃЌНјаавЛЯЕСаЕФавщДІРэЃЌНЋЪ§ОнЗХдкжИЖЈЕижЗЃЌНЛИјЩЯВугІгУЁЃЗЂЫЭЗНЯђдђЯрЗДЃЌНЋашвЊДІРэЕФЪ§ОнАќзАКѓЭЈЙ§гВМўЛКГхЗЂЫЭГіШЅЁЃtoeЕФДІРэМђЛЏСЫСїГЬЃЌжїЛњжЛашвЊжБНгДІРэЪ§ОнЖјВЛгУЖдЪ§ОнВ№АќжизщЃЌвђЖјЖдавщДІРэЃЌжаЖЯКЭЪ§ОнПНБДЖМДѓДѓМѕЩйЃЌНЕЕЭСЫжїЛњcpuЕФИКЕЃЁЃ 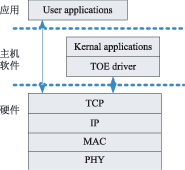 ЭМ1 toeММЪѕЕФдРэПђЭМ toeгВМўНсЙЙ Ёё гВМўЩшМЦЗНАИ ДгЦїМўЕФЪЕЯжЩЯЃЌtoeЪЕЯжЗНАИПЩвдВЩгУСНжжНсЙЙЃКвЛжжЪЧЗжРыдЊМўНсЙЙЃЌСэЭтвЛжжЪЧasicаОЦЌЁЃЗжРыдЊМўВЩгУЕчТЗАхЙЙНЈЃЌОпгааоИФСщЛюадЃЌЗНБуЩ§МЖИФНјЁЃВЩгУasicаОЦЌЪЕЯжЕФЗНАИЪЧНЋавщДІРэМЏГЩЕНЖЈжЦЕФаОЦЌжаЃЌдкадФмЩЯБШЗжРыдЊМўЕФЗНЪНгаЫљЬсИпЃЌЕЋЫќдкПЩБрГЬадЁЂРЉеЙадКЭСщЛюадЗНУцБШНЯВюЁЃЮЊСЫЬсИпСщЛюадгжБЃжЄДІРэЫйЖШЃЌПЩвдВЩгУfpgaРДЪЕЯжtoeЁЃ дкЩшМЦжаВЩгУСЫalteraЙЋЫОЕФFPGAРДЪЕЯжtoeЃЌВЂХфКЯnios iiЪЕЯжЧЖШыЪНДІРэЦїЕФЙІФмЁЃЭМ2ЮЊtoeЕФПђМмНсЙЙЃЌЫќгЩвЛИіЧЖШыЪНcpuЁЂНгЪеВПЗжЁЂЗЂЫЭВПЗжКЭЮяРэгВМўНгПкЙЙГЩЁЃдкетИіНсЙЙжаЃЌЫљгаЕФЗЂЫЭФЃПщдквЛБпЃЌНгЪеФЃПщдкСэвЛБпЃЌЪЧЮЊСЫФмжБНгЗУЮЪвЛИіЙВЯэЕФДцДЂЦїЃЌДгЖјМѕЩйЪ§ОнПНБДЁЃЮЊСЫжЇГжжкЖрЕФавщФЃПщЗУЮЪЃЌЭЈЙ§вЛЬѕФкВПзмЯпРДСЌНгавщФЃПщКЭЙВЯэДцДЂЦїЁЃгЩЧЖШыЪНcpuаЕїФЃПщМфЕФЭЈаХЃЌзДЬЌЙмРэвдМАКЭЩЯВуcpuЕФЭЈаХЁЃ 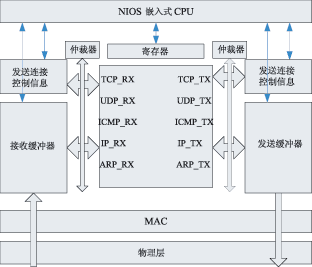 ЭМ2 toeгВМўНсЙЙ ЕБЭјТчЩЯЫЭРДвЛИіЪ§ОнАќЪБЃЌЮяРэНгПкПЊЪМЦєЖЏЃЌНјааМђЕЅЕФАќЭЗДІРэКѓЃЌЗЂЫЭжаЖЯИјЧЖШыЪНcpuЃЌcpuвЦЖЏЪ§ОнЕННгЪеЛКГхЦї(buffer)ЃЌНЋЯћЯЂЖгСажУЮЊгааЇЁЃавщНгЪеФЃПщМьВтЕНгаЪ§ОнашвЊДІРэЃЌЦєЖЏавщЗжЮіДІРэЁЃЕБЫљгаЕФДІРэЭъГЩКѓЃЌЧЖШыЪНcpuЗЂЫЭвЛИіжаЖЯИјжїcpuЃЌВЂНЋЪ§ОнЗХШыжИЖЈЕФЕижЗЁЃЗЂЫЭЙ§ГЬКЭНгЪеЙ§ГЬЯрЗДЃЌcpuАбашвЊДІРэЕФЪ§ОнЗХШыЗЂЫЭЛКГхЦїЃЌавщФЃПщМьВтЕНгаЯћЯЂКѓПЊЪМЦєЖЏДІРэЁЃЭъГЩКѓНЋЪ§ОнвЦЕНЮяРэВуЕФЗЂЫЭЛКГхжаЗЂЫЭГіШЅЁЃдкетИіЩшМЦжаЃЌЙВЯэДцДЂЦїЕФЗУЮЪПижЦКЭавщФЃПщЕФЩшМЦЪЧФбЕуЃЌЯТБпНЋЯъЯИНщЩмЁЃ Ёё ЙВЯэДцДЂЦїЕФЗУЮЪ дкfpgaжаЃЌЫљгаЕФавщФЃПщНЋЖдЪфШыгыЪфГіЛКГхЦїгаПижЦШЈЁЃетРяЪЙгУзмЯпЕФЗНЪНРДЗУЮЪЛКГхЦїЃЌВЂМгЩЯвЛИізмЯпжйВУЦїРДДІРэФЃПщЖдЛКГхЦїЕФЗУЮЪЁЃавщФЃПщдкетИізмЯпЩЯзїЮЊЗУЮЪЗЂЦ№епЁЃЕБФГвЛФЃПщашвЊЗУЮЪЛКГхЦїЕФЪБКђЃЌЫќашвЊЯђзмЯпжйВУЗЂЦ№вЛИіжаЖЯЃЌЕШД§ЦфЯьгІЁЃзмЯпжйВУЪЙгУТжбЏЕФЗНЪНРДДІРэУПИіФЃПщЕФЯьгІЁЃавщФЃПщЛёЕУЗУЮЪШЈЯоКѓЃЌОЭПЩвдЖдЛКГхЦїНјааВйзїСЫЃЌВйзїНсЪјКѓЃЌЪЭЗХЗУЮЪШЈЯоЁЃЪЙгУзмЯпжйВУЦїТжбЏЕФЗНЪНжЛЪЧФПЧАЩшМЦЕФвЛжжЗНЪНЃЌдкВЛЭЌЕФгІгУжаЃЌПЩФмЛсгаИќКУЕФЗНЪНРДДІРэЙВЯэДцДЂЦїЕФЗУЮЪЃЌашвЊКѓајЕФбаОПНјвЛВНбщжЄЁЃ Ёё ДцДЂЦїЙмРэ етРягаСНжжРраЭЕФДцДЂЦїЃКБОЕиЕФМАЙВЯэЕФДцДЂЦїЁЃБОЕиДцДЂЦїзЄСєдкУПИіФЃПщЕФФкВПЁЃетаЉБОЕиДцДЂЦїЪЧзЄСєдкетаЉФЃПщФкВПЕФМФДцЦїЛђепИпЫйЛКГхДцДЂЦїЁЃЙВЯэДцДЂЦїПЩвдБЛШЮКЮФЃПщЭЈЙ§жИеыРДЗУЮЪЁЃУПИіФЃПщЪЙгУЫќздМКЕФБОЕиДцДЂЦїРДБЃДцЫїв§КЭЦЋвЦСПЁЃетИіДцДЂЦїНЋБЃДцБОФЃПщдЫааЫљашвЊЕФСйЪББфСПЁЃУПИіФЃПщНЋПижЦгУРДжИЯђБЛДІРэЕФЪ§ОнАќв§гУЕФБрКХЁЃЬиЖЈФЃПщЕФБрКХЪ§СПНЋжБНгПижЦФЃПщЕФааЮЊЁЃ ЭМ3УшЪіСЫдкtcpНгЪеФЃПщжаЃЌвЛИіДцДЂЦїЧјгђЪЙгУЫїв§РДВщевЕФР§згЁЃЪфШыЫїв§КЭЪфГіЫїв§ЖдгкУПИіФЃПщРДЫЕЖМЪЧгаЗУЮЪПижЦЕФШЈЯоЃЌЫїв§ЪЙЕУФЃПщжЎМфБЃГжаЕїЁЃ 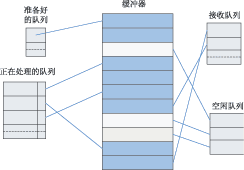 ЭМ3 ЙВЯэДцДЂЦїЕФВщевЫїв§ УПДЮвЛИіЪ§ОнБЈРыПЊЛђепЕНДявЛИіЪфШыЛКГхЦїЃЌЖМвЊЯШВщбЏДцДЂЦїЙмРэФЃПщЁЃетИіФЃПщЪЙгУвЛИіГЦзїПеЯаЖгСаБэЕФЫїв§РДЙмРэЪфШыЪфГіЛКГхЦїжаЕФПеЯаЕижЗЁЃЭЈЙ§ВщбЏетИіБэЃЌДцДЂЦїЙмРэФЃПщПЩвдЮЊНјШыЕФгааЇдиКЩЗжХфПеМфЁЃЕБвЛИіЪ§ОнБЈРыПЊЦфжавЛИіЛКГхЦїЃЌФЧУДвЛИіаТЕФжЕНЋЕЧМЧЕНетИіПеЯаЖгСаБэжаЁЃетИіБэЪЧгУРДЙмРэЛКГхЦїжаЕФПеЯаЕижЗЕФЁЃЫќЕФНсЙЙАќКЌЃКвЛИіЪфШыЛђепЪфГіЛКГхЦїЕФв§гУЃЛвЛИіЛКГхЦїЕФЪЖБ№КХЃЛПЩгУПеМфЕФДѓаЁЁЃЖЊЦњФЃПщвдМАФкДцЪЭЗХФЃПщвВМфНгЕигыПеЯаПеМфБэДђНЛЕРЁЃ Ёё авщФЃПщЕФЩшМЦ ЪЕЯжtcp/ipЕФаЖдиРыВЛПЊКЭЫќНєУмЯрЙиЕФавщЁЃЮЊСЫЪЕЯжВЂааДІРэЃЌећИіtcp/ipавщеЛЗжГЩСЫЭМ4жаЕФИїИіФЃПщЁЃВЛЭЌЕФБЈЮФОЙ§ВЛЭЌЕФЪ§ОнТЗОЖДІРэБЈЭЗаХЯЂЁЃУПИіавщФЃПщЕФЛКГхдкДцДЂЦїжаЪЧХХЖгЕФЁЃетбљЕФЩшМЦФмЙЛШУtcp_rxФЃПщДІРэБЈЮФЕФЪБКђЃЌip_rxФЃПщЛЙФмЮЊНгЯТРДЕФБЈЮФДІРэipВуЕФЪ§ОнЁЃМђЖјбджЎЃЌУПИіавщФЃПщЖМЪЧЖРСЂЕФТпМЕчТЗЃЌавщЕФДІРэЭЌШэМўРрЫЦЁЃНгЪеЪБАДЛКГхжаЕФЫГађДІРэБЈЮФЭЗКЭЪ§ОнЁЃЗЂЫЭЪБИљОнгУЛЇЕФжИСюдкЛКГхжаЬэМгБЈЮФЭЗКЭЫљашЪ§ОнЖЮЁЃ 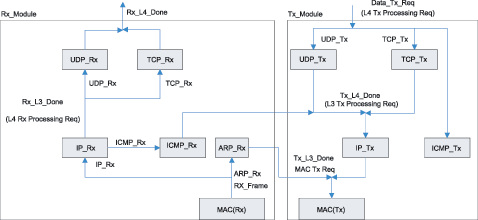 ЭМ4 авщФЃПщДІРэ Ёё авщФЃПщдЫаазДЬЌ авщФЃПщЩшМЦГЩАДееЯТУцЭМ5ЫљУшЪіЕФзДЬЌжмЦкРДЙЄзїЁЃШчЙћЪфШыЫїв§жаУЛгаЪ§ОнАќНјШыЃЌДІРэЙ§ГЬНЋБЛЫјЖЈЁЃдкНјШывЛИіЪ§ОнАќжЎКѓЃЌгВМўПЊЪМСЫЪ§ОнАќЕФДІРэЙ§ГЬЁЃДІРэЭъжЎКѓЃЌЩњГЩЕФЪ§ОнАќЗХдкЪфГіЫїв§жаЁЃЦфЫћЕФФЃПщАбетИіЪфГіЫїв§ЕБзїздМКЕФЪфШыЫїв§ЁЃЛКГхЦїЕФЫїв§жБНгвРРЕгкУПИіФЃПщЁЃдкtcpНгЪеФЃПщЃЌЪфШыЫїв§ЪЧipОЭаїЫїв§ЃЌетИіipОЭаїЫїв§ЪЧipНгЪеФЃПщЕФЪфГіЫїв§ЁЃtcpЕФЪфГіЫїв§НЋЪЧtcpОЭаїЫїв§ЁЃгІгУВувдМАЦфЫћДІгкtcpЩЯВуЕФавщНЋЪЙгУетИіЫїв§РДДІРэвбООЭаїЕФtcp/ipЪ§ОнАќЁЃвЛЕЉвЛИіФЃПщНЋвЛИіЫїв§ЗХШыЫќЕФЪфГіЫїв§ЃЌФЧУДетИіФЃПщНЋЗЕЛиЕНзДЬЌ1ЕШД§ЃЌжБЕНЯТвЛИіЫїв§ЕФЕНРДЁЃ 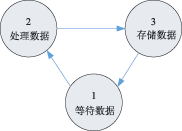 ЭМ5 зДЬЌЛњ адФмЗжЮіМАФЃФт дкетРяЃЌвЊЙРМЦдк100mb/sвдЬЋЭјЕФадФмЁЃЕБЪЙгУtcpзюДѓИККЩЪБКђЃЌвЛИіЪ§ОнАќЪЧ1460bЃЌМгЩЯtcpКЭipЭЗЃЌАќГЄДяЕН1500bЃЌМгЩЯ14bЕФmacЭЗКЭ4bЕФcrcаЃбщзжНкЃЌвЛЙВга1518bЁЃДЫЭтmacдкДЋЪфгааЇБЈЮФЪБЃЌЛЙга8bЕФЧАЮФЁЃетбљдк100mbвдЬЋЭјДІРэвЛИіТњИККЩжЁашвЊ1526ЁС8ЁС10nsЃН122 080nsЃН0.122 08msЁЃвВОЭЪЧЫЕЯЕЭГашвЊдк 0.122 08msЛђ12 208Иі100mbЕФЪБжгжмЦкФкЭъГЩећИіжЁДІРэЁЃетЪЧзюКУЕФЧщПіЁЃЕБtcpУЛгаШЮКЮИККЩЪБЃЌжЁЕФзжНкзмЪ§ЮЊ20(tcpЭЗ)ЃЋ20(ipЭЗ)ЃЋ14(macЭЗ)ЃЋ4(crc)ЃЋ8(macЧАЮФ)ЃН66bЁЃдк100mb/sЕФвдЬЋЭјжаашвЊ66ЁС8ЁС10ns=5.28ІЬsЪБМфДЋЪфЁЃОЭЪЧЫЕЯЕЭГашвЊдк5.28ІЬsФкДІРэЭъетИіЪ§ОнЃЌетЪЧзюЛЕЕФЧщПіЁЃ ЭЈЙ§ЯЕЭГЕФЗжЮіЃЌЖдТњИККЩЕФжЁРДЫЕЃЌДгmacЛКГхЦїПНБДЪ§ОнЕНФкВПДцДЂЦїПЊЪМЃЌжБЕНДІРэЭъБЯКѓЗХдкЯЕЭГжїДцДЂЧјетИіЪБМфФкЃЌзмЙВашвЊЕФЪБжгжмЦкЦНОљЮЊ1740ИіЁЃЗЂЫЭЕФЪБКђашвЊЕФ1784ИіЪБжгжмЦкЁЃУЛгаИККЩЕФЪБКђЗжБ№дкЗЂЫЭКЭНгЪеашвЊ280КЭ269ИіЪБжгжмЦкЁЃЫљвдЃЌЮвУЧПЩвдМЦЫуГідк100mb/sЕФвдЬЋЭјашвЊЯЕЭГЕФЯЕЭГЪБжгЃЌШчБэ1ЫљЪОЁЃИљОнзлКЯЕФНсЙћЃЌЯЕЭГФмДяЕНЕФзюДѓЪБжгЮЊ49mhzЃЌВюВЛЖрФмЙЛТњзузюЛЕЧщПіЕФашвЊЁЃШЛЖјЃЌзюЛЕЕФЧщПіЪЧКмЩйЗЂЩњЕФЃЌЫљвдФПЧАЩшМЦЕФtoeЯЕЭГФмЙЛКмКУЕиТњзуАйезЮЛвдЬЋЭјЕФашЧѓЁЃ 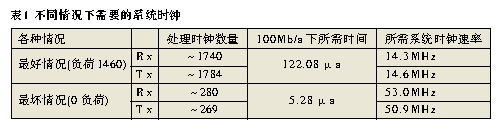 ЪЙгУpingЁЂudpКЭtcpГЬађНјааФЃФтЁЃФЃФтЛЗОГашвЊ2ЬЈЭЈЙ§ЭјТчСЌНгЕФМЦЫуЛњЃЌвЛЬЈзїЗўЮёЦїЃЌвЛЬЈзїПЭЛЇЛњЁЃЭЈЙ§quartus iiБрвыdhlЮФМўЃЌЯТдиЕНtoeЭјПЈЕФfpgaжаЃЌНЋtoeЭјПЈСЌНгЕНПЭЛЇЛњЁЃдкПЭЛЇЛњдЫааpingЁЂudpКЭtcpГЬађЃЌШЗШЯЗўЮёЦїЪЧЗёФмЙЛЯьгІПЭЛЇЛњЕФЪ§ОнАќЁЃЭЈЙ§ПЭЛЇЛњЩЯЕФnetwork analyzerШэМўЃЌПЩвдВЖЛёЗЂЫЭНгЪмЪ§ОнАќЃЌФмЙЛНјвЛВНШЗШЯЪ§ОнАќЕФе§ШЗадЁЃ НсЪјгя ИпЫйвдЬЋЭјЕФЗЂеЙЃЌЕМжТФПЧАcpuдкtcp/ipавщеЛЕФДІРэПЊЯњдНРДдНДѓЃЌашвЊЪЙгУзЈУХЕФгВМўРДжДааtcp/ipЕФавщеЛДІРэЁЃБОЮФИјГіСЫвЛжжгВМўЪЕЯжЕФtoeВЮПМЩшМЦЃЌдкгыЦеЭЈЭјПЈВтЪдЖдБШжаБэУїЃЌЪЙгУtoeММЪѕЕФЭјПЈФмЙЛДѓДѓНЕЕЭcpuЕФИКЕЃЃЌЖјБЃГжЭјТчИпЭЬЭТТЪЁЃ |
ЭјгбЦРТл