
Mali GPU: ГщЯѓЛњЦї(Жў) ЈC ЛљгкЧјПщЕФфжШО
ЗЂВМЪБМфЃК2016-7-11 15:07
ЗЂВМепЃКdesignapp
|
ЖЈвхвЛЬЈГщЯѓЛњЦїЃЌгУгкУшЪі Mali GPUКЭЧ§ЖЏГЬађШэМўЖдгІгУГЬађПЩМћЕФааЮЊЁЃДЫЛњЦїЕФгУвтЪЧЮЊПЊЗЂШЫдБЬсЙЉ OpenGL ES API ЯТгаШЄааЮЊЕФвЛИіаФжЧФЃаЭЃЌЖјетЗДЙ§РДвВПЩгУгкНтЪЭгАЯьЦфгІгУГЬађадФмЕФЮЪЬтЁЃЮвдкБОЯЕСаКѓУцМИЦЊВЉЮФжаМЬајЪЙгУетвЛФЃаЭЃЌЬНЬжПЊЗЂШЫдБдкПЊЗЂЭМаЮгІгУГЬађЪБГЃГЃгіЕНЕФвЛаЉадФмШБПкЁЃ етЦЊВЉЮФНЋМЬајПЊЗЂетЬЈГщЯѓЛњЦїЃЌЬНЬж Mali GPUЯЕСаЛљгкЧјПщЕФфжШОФЃаЭЁЃФугІИУвбОдФЖССЫЙигкЙмЯпЛЏЕФЕквЛЦЊВЉЮФ;ШчЙћЛЙУЛгаЃЌНЈвщФуЯШЖСвЛЯТЁЃ ЁАДЋЭГЁБЗНЪН дкДЋЭГЕФжїЯпЧ§ЖЏаЭзРУц GPU МмЙЙжа ЁЊ ЭЈГЃГЦЮЊжБНгФЃЪНМмЙЙ ЁЊ ЦЌЖЮзХЩЋЦїАДееЫГађдкУПвЛЛцжЦЕїгУЁЂУПвЛдгяЩЯжДааЁЃУПвЛдгяфжШОНсЪјКѓдйПЊЪМЯТвЛИіЃЌЦфРћгУРрЫЦгкШчЯТЫљЪОЕФЫуЗЈЃК 1. foreach( primitive ) 2. foreach( fragment ) 3. render fragment гЩгкСїжаЕФШЮКЮШ§НЧаЮПЩФмЛсИВИЧЦСФЛЕФШЮКЮВПЗжЃЌгЩетаЉфжШОЦїЮЌЛЄЕФЪ§ОнЙЄзїМЏНЋЛсКмДѓ;ЭЈГЃжСЩйАќКЌШЋЦСГпДчбеЩЋЛКГхЁЂЩюЖШЛКГхЃЌЛЙПЩФмАќКЌФЃАхЛКГхЁЃЯжДњЩшБИЕФЕфаЭЙЄзїМЏЪЧ 32 ЮЛ/ЯёЫи (bpp) беЩЋЃЌвдМА 32 bpp ЗтзАЕФЩюЖШ/ФЃАхЁЃвђДЫЃЌ1080p ЯдЪОЦСгЕгавЛИі 16MB ЙЄзїМЏЃЌЖј 4k2k ЕчЪгЛњдђгавЛИі 64MB ЙЄзїМЏЁЃгЩгкЦфДѓаЁдвђЃЌетаЉЙЄзїЛКГхБиаыДцДЂдкаОЦЌЭтЕФ DRAM жаЁЃ 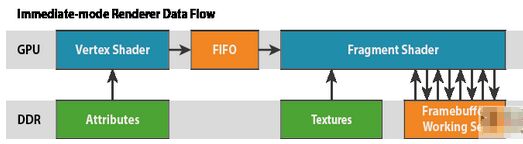 УПвЛДЮЛьКЯЁЂЩюЖШВтЪдКЭФЃАхВтЪддЫЫуЖМашвЊДгетвЛЙЄзїМЏжаЛёШЁЕБЧАЦЌЖЮЯёЫизјБъЕФЪ§ОнжЕЁЃБЛзХЩЋЕФЫљгаЦЌЖЮЭЈГЃЛсНгДЅЕНетвЛЙЄзїМЏЃЌвђДЫдкИпЧхЯдЪОжаЃЌжУгкетвЛФкДцЩЯЕФДјПэИКдиПЩФмЛсЬиБ№ИпЃЌУПвЛЦЌЖЮвВЖМгаЖрИіЖС-ИФ-аДдЫЫуЃЌОЁЙмЛКДцПЩФмЛсЩдЩдЛКМѕетвЛЮЪЬтЁЃетвЛЖдИпДјПэДцШЁЕФашЧѓЗДЙ§РДЭЦЖЏСЫЖдОпБИаэЖреыНХЕФПэФкДцНгПкКЭзЈгУИпЦЕТЪФкДцЕФашЧѓЃЌетСНепЖМЛсдьГЩФмКФЬиБ№УмМЏЕФЭтВПФкДцЗУЮЪЁЃ Mali ЗНЪН Mali GPU ЯЕСаВЩгУЗЧГЃВЛЭЌЕФЗНЪНЃЌЭЈГЃГЦЮЊЛљгкЧјПщЕФЕФфжШОЃЌЦфЩшМЦзкжМЪЧНпСІМѕЩйфжШОЦкМфЫљашЕФЙІКФОоДѓЕФЭтВПФкДцЗУЮЪЁЃШчБОЯЕСаЕквЛЦЊВЉЮФжаЫљЪіЃЌMali ЖдУПвЛфжШОФПБъЪЙгУЖРЬиЕФСНВНжшфжШОЫуЗЈЁЃЫќЪзЯШжДааШЋВПЕФМИКЮДІРэЃЌШЛКѓжДааЫљгаЕФЦЌЖЮДІРэЁЃдкМИКЮДІРэНзЖЮжаЃЌMali GPU НЋЦСФЛЗжИюЮЊЮЂаЁЕФ16x16 ЯёЫиЧјПщЃЌВЂЖдУПИіЧјПщжаДцдкЕФфжШОдгяЙЙНЈвЛЗнЧхЕЅЁЃGPU ЦЌЖЮзХЩЋВНжшПЊЪМЪБЃЌУПвЛзХЩЋЦїКЫаФвЛДЮДІРэвЛИі 16x16 ЯёЫиЧјПщЃЌНЋЫќфжШОЭъКѓдйПЊЪМЯТвЛЧјПщЁЃЖдгкЛљгкЧјПщЕФМмЙЙЃЌЦфЫуЗЈЯрЕБгкЃК 1. foreach( tile ) 2. foreach( primitive in tile ) 3. foreach( fragment in primitive in tile ) 4. render fragment гЩгк 16x16 ЧјПщНіНіЪЧзмЦСФЛУцЛ§ЕФвЛаЁВПЗжЃЌЫљвдгаПЩФмНЋећИіЧјПщЕФЭъећЙЄзїМЏ(беЩЋЁЂЩюЖШКЭФЃАх)ДцЗХдкКЭ GPU зХЩЋЦїКЫаФНєУмёюКЯЕФПьЫй RAM жаЁЃ 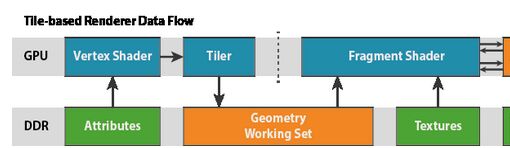 етжжЛљгкЧјПщЕФЗНЪНгажюЖргХЪЦЁЃЫќУЧДѓЬхЩЯЖдПЊЗЂШЫдБЭИУїЃЌЕЋвВжЕЕУСЫНтЃЌгШЦфЪЧдкГЂЪдСЫНтФуФкШнЕФДјПэГЩБОЪБЃК ЖдЙЄзїМЏЕФЫљгаЗУЮЪЖМЪєгкБОЕиЗУЮЪЃЌЫйЖШПьЁЂЙІКФЕЭЁЃЖСШЁЛђаДШыЭтВП DRAM ЕФЙІКФвђЯЕЭГЩшМЦЖјвьЃЌЕЋЖдгкЬсЙЉЕФУП 1GB/s ДјПэЃЌЫќКмШнвзДяЕНДѓдМ 120mWЁЃгыетЯрБШЃЌФкВПФкДцЗУЮЪЕФЙІКФвЊДѓдМЩйвЛИіЪ§СПМЖЃЌЫљвдФуЛсЗЂЯжетецЕФДѓгаЙиЯЕЁЃ ЛьКЯВЛНіЫйЖШПьЃЌЖјЧвЙІКФЕЭЃЌвђЮЊаэЖрЛьКЯЗНЪНашвЊЕФФПБъбеЩЋЪ§ОнЖМЫцЪБПЩгУЁЃ ЧјПщзуЙЛаЁЃЌЮвУЧЪЕМЪЩЯПЩвддкЧјПщФкДцжаБОЕиДцДЂзуЙЛЪ§СПЕФбљБОЃЌЪЕЯж 4 БЖЁЂ8 БЖКЭ 16 БЖЖрВЩбљПЙОтГн1ЁЃетПЩЬсЙЉжЪСПИпЁЂПЊЯњКмЕЭЕФПЙОтГнЁЃгЩгкЩцМАЕФЙЄзїМЏДѓаЁ(вЛАуЕЅвЛВЩбљфжШОФПБъЕФ 4ЁЂ8 Лђ 16 БЖ;4k2k ЯдЪОУцАхЕФ 16x MSAAашвЊОоДѓЕФ 1GB ЙЄзїМЏЪ§Он)ЃЌЩйЪ§жБНгФЃЪНфжШОЦїЩѕжСНЋ MSAA зїЮЊвЛЯюЙІФмЬсЙЉИјПЊЗЂШЫдБЃЌвђЮЊЭтВПФкДцДѓаЁКЭДјПэЭЈГЃЕМжТЦфГЩБОЙ§гкИпАКЁЃ Mali НіНіашвЊНЋЕЅвЛЧјПщЕФбеЩЋЪ§ОнаДЛиЕНЧјПщФЉЮВЕФФкДцЃЌДЫЪБЮвУЧБуФмжЊЕРЦфзюжезДЬЌЁЃЮвУЧПЩвдЭЈЙ§ CRC МьВщНЋПщЕФбеЩЋгыжїФкДцжаЕФЕБЧАЪ§ОнНјааБШНЯ ЁЊ етвЛЙ§ГЬНазіЁАЪТЮёЯћГ§ЁБЁЊ ШчЙћЧјПщФкШнЯрЭЌЃЌдђПЩЭъШЋЬјЙ§аДГіЃЌДгЖјНкЪЁСЫ SoC ЙІКФЁЃЮвЕФЭЌЪТ Tom Olson еыЖдетвЛММЪѕаДСЫвЛЦЊ гХауЕФВЉЮФЃЌЮФжаЛЙЬсЙЉСЫЁАЪТЮёЯћГ§ЁБЕФвЛИіЯжЪЕЪРНчЪОР§(ФГИіУћНаЁАЗпХЕФаЁФёЁБЕФгЮЯЗ;ФуЛђаэЬ§ЫЕЙ§)ЁЃгаЙиетвЛММЪѕЕФЯъЯИаХЯЂЛЙЪЧгЩ Tom ЕФВЉЮФРДНщЩм;ВЛЙ§ЃЌетЖљвВЩдЩдСЫНтвЛЯТИУММЪѕЕФдЫгУ(НіЁАЖрГіЕФЗлЩЋЁБЧјПщгЩ GPU аДШы - ЦфЫћШЋБЛГЩЙІЖЊЦњ)ЁЃ  ЮвУЧПЩвдВЩгУПьЫйЕФЮоЫ№бЙЫѕЗНАИ ЁЊ ARM жЁЛКГхбЙЫѕ (AFBC) ЁЊ ЃЌЖдЬгЙ§ЪТЮёЯћГ§ЕФЧјПщЕФбеЩЋЪ§ОнНјаабЙЫѕЃЌДгЖјНјвЛВННЕЕЭДјПэКЭЙІКФЁЃетвЛбЙЫѕПЩвдгІгУЕНРыЦС FBO фжШОФПБъЃЌКѓепПЩдкЫцКѓЕФфжШОВНжшжагЩ GPU зїЮЊЮЦРэЖСЛи;вВПЩвдгІгУЕНжїДАПкБэУцЃЌжЛвЊЯЕЭГжаДцдкМцШн AFBC ЕФЯдЪОПижЦЦїЃЌШч Mali-DP500ЁЃ ДѓЖрЪ§ФкШнгЕгаЩюЖШЛКГхКЭФЃАхЛКГхЃЌЕЋжЁфжШОНсЪјКѓОЭВЛБидйБЃСєЦфФкШнЁЃШчЙћПЊЗЂШЫдБИцЫп Mali Ч§ЖЏГЬађВЛашвЊБЃСєЩюЖШЛКГхКЭФЃАхЛКГх2ЁЊ РэЯыЗНЪНЪЧЭЈЙ§ЕїгУ glDiscardFramebufferEXT (OpenGL ES 2.0) Лђ glInvalidateFramebuffer (OpenGLES 3.0)ЃЌЫфШЛдкФГаЉЧщаЮжаПЩгЩЧ§ЖЏГЬађЭЦЖЯ ЁЊ ФЧУДЧјПщЕФЩюЖШФкШнКЭФЃАхФкШнвВОЭГЙЕзВЛгУаДЛиЕНжїФкДцжаЁЃЮвУЧгжДѓЗљНкЪЁСЫДјПэКЭЙІКФ! ЩЯБэжаПЩвдЧхЮњЕиПДГіЃЌЛљгкЧјПщЕФфжШООпгажюЖргХЪЦЃЌгШЦфЪЧПЩвдДѓЗљНЕЕЭгыжЁЛКГхЪ§ОнЯрЙиЕФДјПэКЭЙІКФЃЌЖјЧвЛЙФмЙЛЬсЙЉЕЭГЩБОЕФПЙОтГнЙІФмЁЃФЧУДЃЌгааЉЪВУДСгЪЦФи? ШЮКЮЛљгкЧјПщЕФфжШОЗНАИЕФжївЊЖюЭтПЊЯњЪЧДгЖЅЕузХЩЋЦїЕНЦЌЖЮзХЩЋЦїЕФНЛНгЕуЁЃМИКЮДІРэНзЖЮЕФЪфГіЁЂИїЖЅЕуПЩБфЪ§КЭЧјПщжаМфзДЬЌБиаыаДГіЕНжїФкДцЃЌдйгЩЦЌЖЮДІРэНзЖЮжиаТЖСШЁЁЃвђДЫЃЌБиаывЊдкПЩБфЪ§ОнКЭЧјПщзДЬЌЯћКФЕФЖюЭтДјПэгыжЁЛКГхЪ§ОнНкЪЁЕФДјПэжЎМфШЁЕУЦНКтЁЃ ЕБНёЕФЯжДњЯћЗбРрЕчзгЩшБИе§ДѓВНЯђИќИпЗжБцТЪЯдЪОЦСТѕНј;1080p ЯждквбЪЧжЧФмЪжЛњЕФГЃЬЌЃЌХфБИMali-T604 ЕФ Google Nexus 10 ЕШЦНАхЕчФдвд WQXGA (2560x1600) ЗжБцТЪдЫааЃЌЖј 4k2k е§ж№НЅГЩЮЊЕчЪгЛњЪаГЁЩЯаТЕФЁАВЛЖўжЎбЁЁБЁЃЦСФЛЗжБцТЪвдМАжЁЛКГхДјПэе§ПьЫйЗЂеЙЁЃдкетвЛЗНУцЃЌMali ШЗЪЕБэЯжГіжкЃЌЖјЧввдЖдгІгУГЬађПЊЗЂШЫдБЛљБОЭИУїЕФЗНЪНЪЕЯж - ЮоашШЮКЮДњМлЃЌОЭФмЛёЕУЫљгаетаЉКУДІЃЌЖјЧвЛЙВЛгУИќИФгІгУГЬађ! дкМИКЮДІРэЗНУцЃЌMali вВФмДІРэКУИДдгЖШЁЃаэЖрИпЖЫЛљзМВтЪде§дкНгНќУПжЁАйЭђИіШ§НЧаЮЃЌЦфИДдгЖШБШ Android гІгУЩЬЕъжаЕФШШУХгЮЯЗгІгУГЬађИпГівЛИі(ЛђСНИі)Ъ§СПМЖЁЃШЛЖјЃЌгЩгкжаМфМИКЮЪ§ОнЕФШЗЕНДяжїФкДцЃЌЫљвдПЩвдгІгУвЛаЉгагУЕФММЧЩКЭОїЧЯЃЌРДгХЛЏ GPU адФмВЂГфЗжЗЂЛгЯЕЭГФмСІЁЃетаЉММЧЩжЕЕУЭЈЙ§вЛЦЊВЉЮФРДЯИЬИЃЌЫљвдЮвУЧЛсдкетвЛЯЕСаЕФКѓајВЉЮФжадйгшвдНщЩмЁЃ аЁНс дкетЦЊВЉЮФжаЃЌЮвБШНЯСЫзРУцаЭжБНгФЃЪНфжШОЦїгы Mali ЫљгУЕФЛљгкЧјПщЗНЪНЕФвьЭЌЃЌгШЦфЬНЬжСЫСНжжЗНЪНЖдФкДцДјПэЕФгАЯьЁЃ |
ЭјгбЦРТл