
高速上下变频FIR滤波器的FPGA设计
发布时间:2010-7-24 10:39
发布者:lavida
|
滤波器是通信系统中的重要部件。数字滤波器的实现一般有3 条途径: (1) 由通用DSP 芯片编程实现; (2) 选用已有的专用滤波器芯片实现; (3) 根据系统要求自行设计滤波器, 并用FPGA 实现。随着数字通信速率的快速提高, 对滤波器的运算速度的要求也愈来愈高。在数据传输率为54M b it?s, 符合HyperL an2 的宽带无线WLAN 收发器的研究实验中, 数据的基带速率为20MByte?s, 经4 倍升采样为80MByte?s, 在此升采样(在接收链路中为降采样) 过程中必须实现数字上下变频和抗混叠滤波器。如此高速的滤波器如用通用DSP 实现, 则将占用该DSP 的绝大部分运算资源, 使DSP 几乎不能承担其他编解码等任务。 这种情况下, 最好的选择是用FPGA 硬件实现上下变频和滤波。虽然目前市场上有一些用于FPGA 实现上下变频和F IR滤波器的IP 软核, 但这些软核由于追求通用性和可配置性, 在代码效率、运行速度、系统集成紧凑性和FPGA 资源用量最小化等方面很难满足要求或达到最优化。 因此, 根据具体系统的运行要求, 暂不强求通用性和可重新配置性, 而着重研究实现上下变频滤波的高速度和FPGA 资源用量最小化。资源用量最小化可以在一片FPGA 上集成更多的功能电路, 例如增益自动控制功能等, 即可能实现片上系统(SoC)。为了在实现高速的同时, 减少FP2GA 的资源占用量, 一方面可以研究具体FPGA 的底层结构特点, 人工干预底层电路综合来组建系统, 另一方面要研究被设计电路的实现结构、算法和编码方式等, 从中选择快速有效和硬件复杂度最低的实现方法。 本文根据宽带WLAN 的收发器要求, 在系统总体结构安排、滤波器结构设计、乘加运算算法, 以及流水线实现等方面进行研究, 在实现高速度的同时, 使得系统资源的占用量达到最小。 达到这一目标的主要技术要点有: (1) 充分利用上下变频器结构特点, 只用一套滤波器运算单元实现上变频滤波和下变频滤波; (2) 充分利用收发器的数据流特点和F IR 滤波器系数特点, 用该滤波器运算单元同时实现对I,Q 两个数据流的变频和滤波; (3) 分别用传统滤波器的转置结构和独特的位平面结构设计实现高速上下变频和滤波(80MHz 运算速度的40 阶上下变频F IR 滤波器)。并对二者的实现结构和综合结果进行比较, 说明在达到同样速度的前提下, 位平面结构仅占用转置结构所用逻辑资源的一半。在下一步对位平面结构的通用性设计有所改进后, 位平面结构应成为高速滤波器的主要设计方法; (4) 合理划分和优化各级流水线的性能是实现上下变频滤波高速运行的关键。 宽带无线通信的数字上下变频 数字上下变频过程是数字通信系统中必不可少的实现环节。上变频就是用数字信号处理的手段将基带已调制信号的频带搬移到中频( IF) 的过程。上变频得到的数字IF 信号经DAC 变换为模拟信号后, 再在模拟域变换为RF 信号, 通过天线发送出去, 实现数字信号的发送(图1 的右箭头方向表示信号的发送步骤)。无线信号的接收过程(图1 的左箭头方向) 和发送过程完全相反, 即在A?D 变换得到数字IF 后, 经数字下变频变换为基带调制信号, 再经数字解调最后得到接收的信息。在符合HyperLan2 传输协议的WLAN 的收发器实验中,数据传输率高达54M b it?s, 其基带O FDM 调制输出的I,Q 信号采样频率高达20MBytes。 图1 实线框内是本文设计实现的上下变频过程, 它们被集成在一片FPGA 上。基带输出的I,Q 信号, 经4 倍增采样、去混叠滤波、增益补偿后和20MHz (f s?4混频, f s 为采样频率) 的数字载波信号复混频。数字IF 信号的采样率升为80M SPS, 基带信号的中心频率被移至20MHz。这一过程中滤波器起着至关重要的作用, 它保证基带信号的频谱在升降采样过程和混频过程中不发生混叠和展宽。滤波器的主要指标为: Remez 40 阶低通F IR 滤波器; 通带带宽10MHz; 阻带抑制比- 50 dB; 输入信号采样频率80MHz; 滤波器系数量化为12bit 有符号数表示。 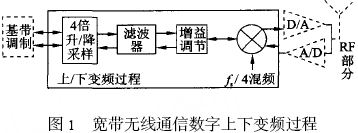 上下变频滤波器的实现 滤波器的输入数据流特点 基带调制的信号输出形式是I (8bit) 和Q (8bit ) 的并行输出. 在数据发送方式时, I,Q 信号直接馈入上变频器。4 倍升采样过程是分别在I 和Q序列中每相邻点之间插入3 个0, 从而数据率升为80MHz。利用升采样后的这一特点, 可以将并行的I,Q 数据串行化, 如图2 (a) 所示。在接收数据方式下, RF 信号经80MSPS 的AD 采样后输出馈入下变频器。在下变频器中的第一步处理是中心频率下移的复混频。输入信号分别和相位相差90°的正弦波数字相乘, 从而分解出I,Q 两路信号。用于复混频的正弦波和余弦波的中心频率为20MHz, 每周期取4 个点, 其中有2 个点为0, 另2 个点分别为+ 1 和- 1。这样得到的I,Q 信号相邻两点之间必为零值, 如图2 (b) 所示。和发送工作方式一样, 可以将并行的I,Q 信号串行化。这样在两种工作方式下, 滤波器的输入并行数据流均先变换成8bit宽的串行输入流。 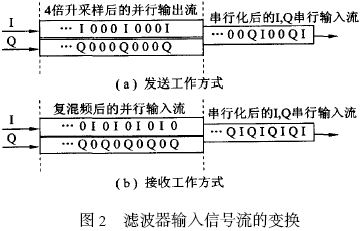 滤波器的转置结构实现 FIR 滤波器的输出是输入信号与滤波器系数的卷积求和。根据卷积表达式的计算形式, 传统上很自然地会得到滤波器的直接形式的实现结构。由于用直接形式实现的滤波器的输出延迟较大且与滤波器阶数成正比, 在硬件实现上, 一般都使用直接形式的转置结构, 如图3 所示。串行化后的I,Q 数据流, 以80MHz 速率同时馈入40 个乘法器和滤波器系数分别相乘, 所得结果作为加法器的一个输入量。加法器的另一输入量是前一个加法器在上一个时钟节拍的输出结果, 它是由图3 中小方框表示的寄存器缓存。 为了用一个滤波器硬件同时对I,Q 滤波, 设计中充分利用串行输入流的特点, 用两套寄存器( I,Q 通道寄存器, 16 b it 宽) 分别缓冲和延迟I 通道滤波的中间结果和Q 通道的中间结果, 即相当于滤波器被I 通道和Q 通道分时复用,在输出端再按序将它们分开, 输出并行的I,Q 数据流。在FPGA 的编程实现中, 乘法器采用Xilinx的N 位变量和M 位常量相乘产生M + N 位积的乘法器IP 软核。由于该软核充分利用了FPGA 查表(Look-up ) 的硬件单元结构来实现乘法, 速度较快, 一次相乘运算用时小于12 n s。 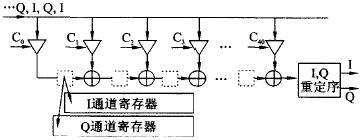 滤波器的位平面结构实现 上述滤波器的转置结构是滤波器设计的传统方法。而用位平面结构快速有效地实现乘2加运算的基本思想早在86 年就被提出, 由于将其应用于滤波器设计在通用性和可重新配置性方面不如转置结构简单, 所以一直不被广泛应用。但位平面结构的高速度和高代码效率却是不容忽视的, 特别是在当今SoC 的设计实现方面。位平面结构的本质就是重新安排滤波器乘积求和运算过程的顺序。 图4 是直接形式的位平面结构原理说明, 其中每一个方框部分代表一个位平面, 分别标记为位平面1、位平面2 等。在每一个位平面内, 和输入数据相乘的仅是滤波器系数的一个b it, 位平面1 为各系数的最低位L SB, 位平面2 是各系数的最低第二位, 依此类推, 位平面12 是各系数的M SB。因为滤波器系数为12 b it 宽, 所以共有12 个位平面。输入数据同时输入到各个位平面, 所有位平面并行计算对应位的部分积及其累加结果。最后, 在每个时钟节拍下, 位平面1 输出结果右移一位(除以2) 和位平面2 输出相加, 所得结果除以2, 再和位平面3的输出相加, 这样继续相加直至最后一个位平面。由于在位平面内的乘数仅为单个b it (0 或者1) , 实质上滤波器的乘2加运算已转化为纯相加运算。 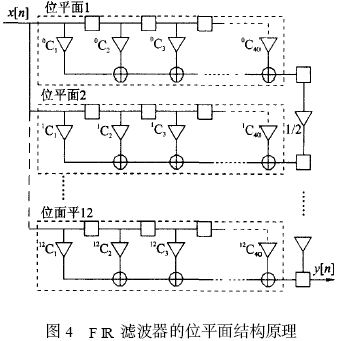 为了能够用一套滤波器同时对I,Q 数据流进行滤波, 采用图5 所示的上下变频滤波器的总体结构, 其中将整个滤波器拆分为两个子滤波器, 它们均由位平面结构实现。子滤波器1 的奇数系数设定为0, 而偶数系数不变; 子滤波器2 的偶数系数改变为0, 而奇数系数不变。输入的串行化的I,Q 数据流被40 个数据寄存器移位缓存, 两个子滤波器分别交替计算纯I 和Q 的输出值, 例如, 在某一时钟, 子滤波器1 完全忽略奇数位置上的输入数据,计算得到的是I 流的滤波结果, 与此同时, 子滤波器2 完全忽略偶数位置上的输入数据, 而计算输出Q 流的计算结果。在下一时钟计算内容与此相反:子滤波器1 计算输出Q 流结果, 而子滤波器2 计算输出I 流结果。最后由I,Q 重定序部分将这种I,Q 交织排列转换为平行输出的I,Q 流。 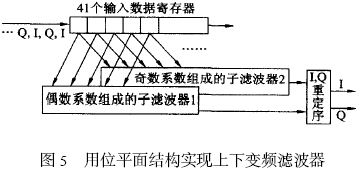 测试结果与比较 整个上下变频器被集成在一片Xilinx FPGA XCV 600HQ 24026 上, 由VHDL 设计完成, 其中滤波器分别用上述两种结构实现。图6 是设计的仿真测试结果。测试过程如下: 先用M at lab 产生如图6(a) 所示的正弦波, 作为输入文件, 测试用VHDL设计的下变频功能, 得到的下变频输出如图6 (b)所示。其中23MHz 的输入信号被下移了20MHz,且输出信号的信噪比大于50 dB; 在测试上变频功能时, 将下变频的输出信号作为VHDL 设计的输入信号, 得到上变频的输出结果如图6 (c) 所示。图中3MHz 的信号又被上移到23MHz 位置。用两种滤波器结构设计的变频器得到了几乎相同的测试结果, 最大运行速度均大于80MHz, 但它们占用芯片资源的情况却不同(见表1) , 其中逻辑资源单元(Slices) 的占用数相差一半。 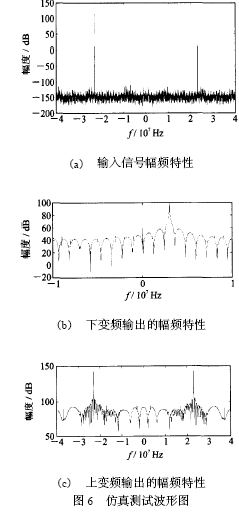 结束语 用FPGA 设计实现滤波器, 采用位平面结构在芯片资源利用率方面占明显优势。这主要得益于位平面结构实现滤波器乘积2累加运算的独特方式。每一位平面计算得到的部分积通过右移一位被及时丢弃而不致影响运算精度。这就省去了一般乘法运算实现时, 为避免精度变差存储中间结果的寄存器必须留有足够的保护位。位平面结构中的运算顺序避免了大量的移位操作, 比较适合FPGA 的结构特点。如果滤波器系数中含有更多的0 bit 位, 将会减小求和操作次数, 进一步提高运算速度。相对于转置结构, 位平面结构的最大缺点是输入和输出之间有较大的延迟, 这主要是由于位平面内直接形式结构的固有延迟和各个位平面在最后输出求和过程的流水线结构所造成的, 但一般不影响实际应用。 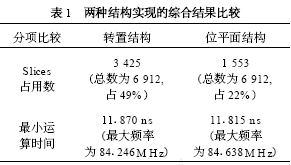 |




网友评论