
FPGA研发之道(9)架构设计漫谈(四)并行与复用
发布时间:2016-2-29 14:10
发布者:designapp
|
FPGA其在众多器件中能够被工程师青睐的一个很重要的原因就是其强悍的处理能力。那如何能够做到高速的数据处理,数据的并行处理则是其中一个很重要的方式。 数据的并行处理,从结构上非常简单,但是设计上却是相当复杂,对于现有的FPGA来说,虽然各种FPGA的容量都在增加,但是在有限的逻辑中达到更高的处理能力则是FPGA工程师面临的挑战。常用并行计算结构如下图所示: 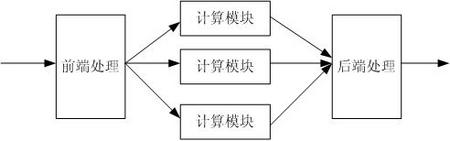 上图中:前端处理单元负责将进入数据信息,分配到多个计算单元中,图中为3个计算单元(几个根据所需的性能计算得出)。然后计算单元计算完毕后,交付后端处理单元整合为统一数据流传入下一级。如果单个计算单元的处理能力为N ,则通过并行的方式,根据并行度M,其计算能力为N*M;在此结构中,涉及到几个问题: 一, 前端处理单元如何将数据分配到多个计算单元,其中一种算法为round-robin,轮流写入下一级计算单元,这种方式一般使用用计算单元计算数据块的时间等同。更常用的一种方式,可以根据计算单元的标示,即忙闲状态,如果哪个计算单元标示为闲状态,则分配其数据块。 二, 计算单元和前后端处理之间如何进行数据交互。一般来说,计算单元处理频率较低,为关键路径所在。前后端处理流量较大,时钟频率较高,因此通过异步FIFO连接,或者双端口RAM都是合适的方式。如果数据可分块计算,且块的大小不定,建议使用FIFO作为隔离手段,同时使用可编程满信号,作为前端处理识别计算模块的忙闲标示。 三, 如果数据有先后的标示,即先计算的数据需要先被送出,则后端处理模块需要额外的信号,确定读取各个计算模块的顺序。这是因为:如果数据等长,则计算时间等长,则先计算的数据会先被送出。但是如果数据块不等长,后送入的小的数据块肯能先被计算完毕,后端处理单元如果不识别先后计算的数据块,就会造成数据的乱序。这可以通过前端计算单元通过小的FIFO通知后端计算单元获知首先读取那个计算单元输出的数据,即使其他计算单元输出已准备好,也要等待按照顺序来读取。 数据的并行处理是FPGA常用的提升处理性能的方法,其优点是结构简单,通过计算单元模块的复用达到高性能的处理。缺点,显而易见就是达到M倍的性能就要要耗费M倍逻辑。 与之相反减少逻辑的另一种方式,则是复用,即一个处理能力较强的模块,可以被N的单元复用,通过复用,而不用每个单元例化模块,可以达到减少逻辑的效果,但控制复杂度就会上升。其结构图如下所示: 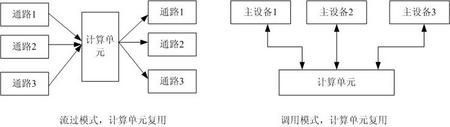 上图复用的结构图中,分别介绍了流过模式复用和调用模式复用。流过模式下,计算单元处理多路数据块,然后将数据块分配到多路上,这种情况下,通过round-robin可以保证各个通路公平机会获得计算单元。其处理思路与上图描述并行处理类似。 调用模式下,计算单元被多个主设备复用,这种架构可以通过总线及仲裁的方式来使各个主设备能够获取计算单元的处理(有很多成熟的例子可供使用,如AHB等)。如果多个主设备和多个计算单元的情况,则可以不通过总线而通过交换矩阵,来减少总线处理带来的总线瓶颈。 实际应用场合,设计的架构都应简单实用为好,交互矩阵虽然实用灵活,但其逻辑量,边界测试验证的难度都较大,在需要灵活支持多端口互联互通的情况下使用,可谓物尽其用。但如果仅仅用于一般计算单元能力复用的场景,就属于过度设计,其可以通过化简成上述两种简单模式,达到高速的数据处理的效果。 并行和复用,虽然是看其来属性相反的操作,但其本质上就是通过处理能力和逻辑数量的平衡,从而以最优的策略满足项目的需要。设计如此,人生亦然。 |





网友评论