
基于SVM和sigmoid函数的字符识别自适应学习算法
发布时间:2015-12-7 15:17
发布者:designapp
|
手写字符的一个突出特点就是模式具有较大的变化性,表现为模式空间的类内分布过于分散,类间交叠严重,这使得识别模型无法“恰当”地拟合每类模式的数据分布或类别之间的判别面。在识别模型过程中,通过自适应学习就能较好地拟合特定书写者笔迹特征向量的空间分布,从而有利于识别率的提高。当然,自适应学习的结果只是提高了对特定书写者的识别率,但通过为不同人的笔迹特征向量提供不同的识别模型,就能够从总体上提高系统的识别率。 任何一种自适应学习算法都基于一定的识别方法。从目前已有的文献来看,大致有以下几种自适应学习所依据的识别方法:HMMs(Hidden Markov Models),ANNs(Artificial Neural Networks),PDNNs(Probabilistic Decision—based Neural Networks),子空间法(Local Subspace)以及模板匹配法(Template Matching)等。这些识别方法可以分为分布拟合法(HMMs,PDNNs,LS,TM)和判别决策法(ANN);前者仅学习每一类的正例,而不学习反例,而后者是同时学习正例和反倒。显然,在模型的一致性上,判别决策法要好于分布拟合法。 根据这种思想,本文提出了一种基于SVM分类算法和sigmoid函数的自适应学习算法。SVM分类算法是一种判别决策方法,在很多识别问题中都获得了很好的实验结果,SVM分类算法的输出为距离,参数化的sigmoid函数拟合SVM输出距离的类别后验概率分布,使SVM的距离输出变换为概率输出。本文提出的算法基于这种概率化方法,通过自适应学习,修改sigmoid参数,使sigmoid函数能够较好地拟合自适应数据输出距离的类别后验概率分布。由于输出距离是基于两类别的判别面的.因此输出距离的类别后验概率分布就同时学习了正例和反例。 本文以手写数字为实验对象,对上文提出的自适应学习算法进行了有效性验证。 1 SVM算法及sigmoid函数 1.1 SVM分类学习算法  1.2 sigmoid函数 本文采用的方法,即利用参数化的sigmoid函数拟合SVM分类决策函数的输出距离的类别后验概率分布,使其距离输出变为概率输出。参数化的sigmoid函数为:  1.3 求解A,B 为了避免求出的参数A,B值的偏移性,应利用不同于训练集D1的数据集D2求解A,B的值。D2= 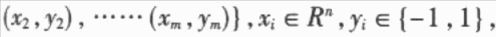 将D2中的所有数据代入到(6)、(7)式中,求解A,B以求出(7)式的极小值问题。 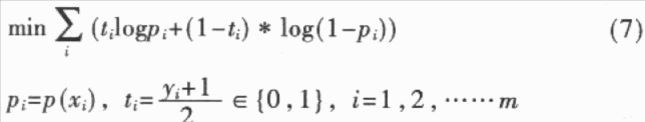 2 基于SVM和sigmoid函数的自适应学习算法 2.1 多类别分类器设计方法 本文依据所述SVM算法和one-verse-one原则设计多类别的分类器。设类别数是n,则共有n*(n-1)/2个分类器,每个分类器的参数依次是权值Wi,j,bi,j,Ai,j和Bi,j,i,j=1,2,……n,i 2.2 概率输出下的多类别决策 概率输出下的多类别决策规则是:设有未知类别数据x,将其代入(6)式中有: 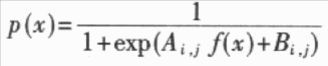 依据投票法原则,若p(x)>O.5,第i类得到1票;若p(x)  Milil的上脚标i1表示x被误识为i1类,Mi1表示被误识为i1类的样本个数。若第i1类的自适应数据集合 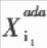 的误识样本集合Ei1中有被误识为i类的样本,则Ei中被误识为i1类的样本和Ei1中被误识为i类的样本将构成正反例集合Ep和En;若i 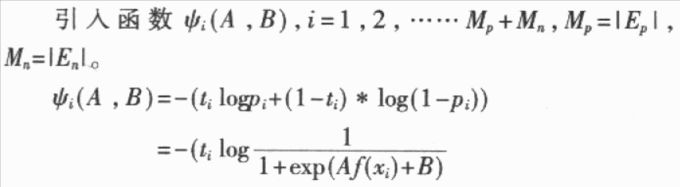 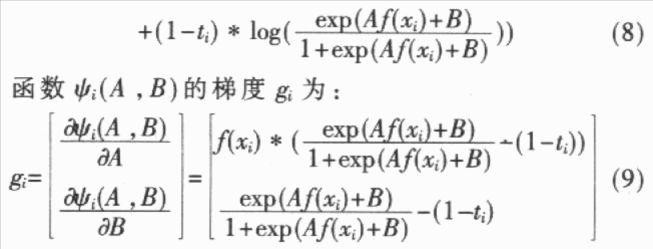 将误识样本的正反例集合Ep,En代入(9)式并根据梯度下降法有:  Aoid,Bold是自适应修正前的参数值,Anew,Bnew是自适应修正后的参数值。 3 实验结果 3.1 预处理及特征提取 本文以O~9十个数字作实验。预处理及特征提取的步骤如下: (1)首先将二值图像作非线性归一化,归一化的尺寸为64*64的方阵。 (2)在非线性归一化后的图像上提取轮廓。 (3)对轮廓图像提取DEF(Directional Element Feature)特征,特征的维数是1024。 (4)对1024维特征作K—L变换,特征维数压缩到128维。 3.2 实验结果 本实验的样本情况为:自行收集样本,平均每个数字145个样本,其中90个样本用来学习判别面的参数W和6,设C=1000,kernel设为线性,采用的软件是LIBSVM;其余的55个样本用来学习参数A,B。在自适应学习和测试阶段,共收集了5个人的样本,每个人平均每个数字的样本数为35个。表l显示了自适应学习的结果。 本实验只测试了线性核的识别情况。从表中的统计结果可以看出,概率输出本身就能够提高识别率;在采用了本文提出的自适应学习算法之后,识别率得到了进一步的提高,平均达到94.5%,比常规SVM方法提高了5.1%。同时,学习算法中的步长η对识别率也有一定程度的影响,步长为0.1的识别率要高于步长为0.2的识别率。 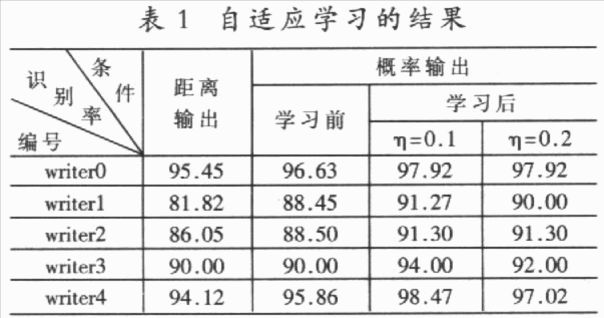 本文基于SVM和sigmoid函数,提出了一种字符识别自适应学习算法。本算法相对于基于HMMs,ANNs,PDNNs,模板匹配,子空间法等识别方法的自适应学习算法,是一种新的自适应学习算法,具有推广能力好和模型一致性好等特点。今后的研究方向在于设计能够更好地适应自适应学习数据的参数A、B的自适应学习算法,寻求更合适的拟台距离类别后验概率分布的函数及判别函数本身的参数W、b的自适应学习算法。 |
网友评论