
еЦЮеИпМЖДІРэЦїЬиадПЩЬсИпБрТыаЇТЪ
ЗЂВМЪБМфЃК2010-7-13 13:47
ЗЂВМепЃКconniede
ЙиМќДЪЃК
БрТыаЇТЪ , ИпМЖДІРэЦї
|
Ъ§зжаХКХДІРэЦї(DSP)дкадФмЁЂЭтЩшЁЂЙІКФКЭМлИёЩЯвбОНсКЯЕУЗЧГЃКУСЫЃЌаэЖрЯЕЭГЙЄГЬЪІЯЃЭћРћгУDSPЕФгХЪЦЃЌШЁДњДЋЭГЩшМЦЗНАИжаЪЙгУЕФДІРэЦїЃЌЕЋвЛИіЧБдкФбЬтЪЧЩшМЦЙЄГЬЪІвбОЮЊЫћУЧЕФгІгУПЊЗЂСЫДѓСПCКЭC++ДњТыЁЃКмУїЯдЃЌЙЄГЬЪІЖМдИвтдкDSPЦНЬЈЩЯРћгУЯжгаЕФИпМЖДњТыЃЌЭЌЪБРћгУDSPЕФЬхЯЕНсЙЙЬиадвдЛёЕУИќКУЕФадФмЁЃ HLLгыЛуБргябд ЁЁЁЁ ЕБПЊЗЂЛљгкDSPЕФШэМўЪБЃЌБиаывЊзіЕФвЛЯюЙЄзїОЭЪЧШЗЖЈЪЙгУФФвЛжжГЬађЩшМЦЗНЗЈбЇЃЌЭЈГЃЪЧдкЛуБргябдКЭИпМЖгябд(HLL)(Р§ШчCЛђC++гябд)жЎМфНјаабЁдёЁЃ ЁЁЁЁ CКЭC++ЕФгХЕуАќРЈФЃПщадЁЂБуаЏадвдМАПЩжиИДРћгУадЁЃ ЁЁЁЁ ДЋЭГЕФЛуБргябдгЩгкЦфгяЗЈКЭЫѕаДФбвдРэНтКЭЪЙгУЃЌГЄЦквдРДВЛБЛШЫУЧЫљПДКУЁЃФПЧАЕФЁАДњЪ§гяЗЈЁБЬхЯЕНсЙЙгаСЫКмДѓИФНјЁЃБэ1ЪЧЪЙгУДЋЭГЗчИёКЭЪЙгУДњЪ§ИёЪНЕФЕфаЭDSPжИСюЪЕР§ЃЌКмЯдШЛКѓепЕФНсЙЙИќМгжБЙлЁЃдкЫљЬсЙЉЕФЪЕР§жаЃЌrМФДцЦїЪЧЪ§ОнМФДцЦїЃЌpМФДцЦїЪЧжИеыМФДцЦїЁЃ 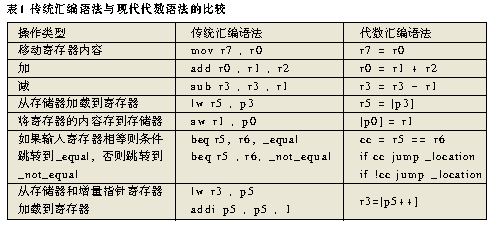 гУЛуБргябдБрГЬРЇФбЕФвЛИідвђЪЧгЩгкЦфЪ§ОнСїМЏжадкDSPЪЕМЪМФДцЦїзщЁЂМЦЫуЕЅдЊКЭДцДЂЦїжЎМфЁЃгУCЛђC++гябдБрГЬЃЌетжжВйзїЭЈГЃЭЈЙ§ЪЙгУБфСПКЭКЏЪ§ЃЌЛђЙ§ГЬЕїгУГіЯждкИќМгГщЯѓЕФДІРэЕШМЖжЎМфЃЌДгЖјЪЙЕУДњТыИќШнвзИњЫцЁЃ ЁЁЁЁ ЮЊЬсИпDSPжДаааЇТЪЃЌЙЄОпПЊЗЂЩЬЛсЪЙгУЛуБргябдЖдживЊЕФЪ§ОнУмМЏДњТыФЃПщНјаагХЛЏЁЃHLLБрвыгХЛЏзЊЛЛПЩвдКмКУЕиЭъГЩИУЯюЙЄзїЃЌЖјЧвЖдDSPЪ§ОнСїКЭМЦЫуЕФжБНгПижЦФмСІЪЧМЋЮЊГіЩЋЕФЁЃетОЭЪЧЮЊЪВУДЩшМЦЙЄГЬЪІЭЈГЃНсКЯЪЙгУC/C++КЭЛуБргябдЁЃHLLЪЪКЯгкПижЦКЭЛљБОЕФЪ§ОнВйзїЃЌЖјЛуБргябдЪЪКЯгкИпаЇЕФЪ§зжМЦЫуЁЃ ЪЪКЯИпаЇБрГЬЕФЬхЯЕНсЙЙЕФЬиад ЁЁЁЁ ЮЊСЫЪЙЛуБргябдГЬађдБФмЙЛгааЇЕиЭъГЩЙЄзїЃЌашвЊСЫНтДІРэЦїЕФНсЙЙРраЭЃЌвдБуФмЙЛЧјЗжВЛЪЪКЯИпЫйЪ§зжМЦЫуЕФФЧаЉDSPДІРэЦїЁЃетаЉЪЪКЯИпаЇБрГЬЕФЬхЯЕНсЙЙНсЙЙЬиадАќРЈЃК ЁЁЁЁЁё зЈгУбАжЗФЃЪН ЁЁЁЁЁё гВМўЛЗТЗНсЙЙ ЁЁЁЁЁё ИпЫйЛКГхДцДЂЦї ЁЁЁЁЁё УПжмЦкЖрДЮВйзї ЁЁЁЁЁё ЛЅЫјСїЫЎЯп ЁЁЁЁЁё СщЛюЕФЪ§ОнМФДцЦїЮФЕВ зЈгУбАжЗФЃЪН ЁЁЁЁ дЪаэДІРэЦїдкЕЅжмЦкФкЗУЮЪЖрИіЪ§ОнзжашвЊСщЛюЕФЕижЗВњЩњЗНЪНЁЃГ§СЫашвЊИќДѓЕФвдDSPЮЊжааФЕФ16bitКЭ32bitБпНчЕФЗУЮЪГпДчЭтЃЌЛЙашвЊзжНкбАжЗвдДяЕНзюгааЇЕФДІРэЁЃетЪЧЗЧГЃживЊЕФЃЌвђЮЊвЛаЉЦеЭЈгІгУ(Р§ШчаэЖрЛљгкЪгЦЕЕФЯЕЭГ)ЖМЪЧАДее8bitЪ§ОнВйзїЁЃЕБДІРэЦїЗУЮЪЯожЦдкЕЅвЛБпНчФкЪБЃЌДІРэЦїПЩФмашвЊЖюЭтЕФжмЦкРДбкБЮЕєЯрЙиЕФЮЛЁЃ ЁЁЁЁ СэЭтвЛжжгаРћЕФбАжЗФмСІЪЧЁАбЛЗЛКГхЁБЁЃИУЬиадБиаыжБНггЩДІРэЦїжЇГжЃЌЮоаызЈУХЕФШэМўЙмРэПЊЯњЁЃбЛЗЛКГхдЪаэГЬађдБЖЈвхДцДЂЦїжаЕФЛКГхЦїЃЌВЂЧвздЖЏПчдНЫќУЧЁЃвЛЕЉЛКГхЦїЩшжУКУЃЌдђЮоаызЈУХЕФШэМўНЛЛЅВйзїЪ§ОнЁЃЕижЗЗЂЩњЦїДІРэЗЧЭЌЪНПчЗљЃЌИќживЊЕФЪЧПЩвдДІРэЭМ1ЫљЪОЕФЁАЛЗШЦЪНЁБЬиадЁЃШчЙћУЛгаетжжздЖЏЕижЗВњЩњЙІФмЃЌГЬађдББиаыЪжЖЏИњзйЛКГхЦїЃЌДгЖјРЫЗбСЫБІЙѓЕФДІРэжмЦкЁЃ 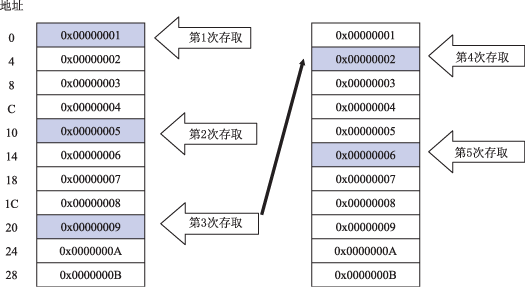 ЭМ1 ЛЗШЦЪНЛКГхЕФР§зг ЁЁЁЁдкДЫР§жаЃЌЛљЕижЗКЭЦ№ЪМЫїв§ЕижЗЃН0x0ЃЛЫїв§ЕижЗМФДцЦїI0жИЯђЕижЗ0x0ЃЛЛКГхЦїГЄЖШLЃН44(11ИіЪ§ОндЊЫиЁС4зжНк/дЊЫи)ЃЛаоИФМФДцЦїM0ЃН16(4ИіЪ§ОндЊЫиЁС4зжНк/дЊЫи) ЁЁЁЁ ЪЕР§ДњТыЃК ЁЁЁЁR0 = [I0++M0]; //R0 = 1ЃЌI0дкДњТыжДааКѓжИЯђ0x10 ЁЁЁЁR1 = [I0++M0]; //R1 = 5ЃЌI0дкДњТыжДааКѓжИЯђ0x20 ЁЁЁЁR2 = [I0++M0]; //R2 = 9ЃЌI0дкДњТыжДааКѓжИЯђ0x04 ЁЁЁЁR3 = [I0++M0]; //R3 = 2ЃЌI0дкДњТыжДааКѓжИЯђ0x14 ЁЁЁЁR4 = [I0++M0]; //R4 = 6ЃЌI0дкДњТыжДааКѓжИЯђ0x24 ЁЁЁЁ гУгкИпаЇаХКХДІРэдЫЫу(Р§ШчПьЫйИЕСЂвЖБфЛЛ(FFT)КЭРыЩЂгрЯвБфЛЛ(DCT))ЕФвЛжжживЊбАжЗФЃЪНЪЧБШЬиЗзЊЁЃЙЫУћЫМвхЃЌЁАБШЬиЗзЊЁБОЭЪЧНЋЖўНјжЦЕижЗжаЕФБШЬиЗзЊЃЌвВОЭЪЧЫЕНЋШЈжЕзюаЁЕФБШЬигыШЈжЕзюДѓЕФБШЬиНЛЛЛЮЛжУЁЃгЩЛљЮЊ2ЕФЕћаЮЫљвЊЧѓЕФЪ§ОнЫГађЪЧЁАвбЗзЊБШЬиЁБЕФЫГађЃЌвђДЫБШЬиЗзЊЫїв§гУРДзщКЯFFTМЖЁЃПЩвдМЦЫуШэМўжаЕФетаЉБШЬиЗзЊЫїв§ЃЌЕЋЪЧетбљзіЕФаЇТЪЗЧГЃЕЭЁЃЭМ2ЫљЪОЪЧБШЬиЗзЊЕижЗСїЪЕР§ЁЃ 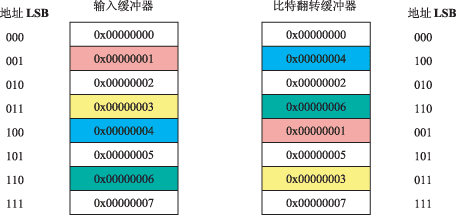 ЭМ2 гВМўБШЬиЗзЊЛњРэ ЁЁЁЁЪЕР§ДњТыЃК ЁЁЁЁLSETUP(Ц№ЪМ, жежЙ)LC0ЃНP0ЃЛ //бЛЗЪ§P0ЃН8 ЁЁЁЁЦ№ЪМЃКR0 = [I0] || I0 += M0(BREV)ЃЛ //I0жИЯђЪфШыЛКГхЦїЃЌдкБШЬиЗзЊЙ§ГЬжаздЖЏдіМг ЁЁЁЁжежЙЃК[I2++] = R0ЃЛ ; //I2жИЯђБШЬиЗзЊЛКГхЦї гВМўбЛЗНсЙЙ ЁЁЁЁ бЛЗдкЭЈаХДІРэЫуЗЈжаЪЧвЛЯюКмживЊЕФЬиадЁЃгаСНИігыбЛЗгаЙиЕФЙиМќЬиадФмЙЛИФНјЖржжЫуЗЈЕФадФмЁЃЕквЛИіЬиадГЦзїЁАСуПЊЯњгВМўбЛЗЁБЁЃЫцзХбАжЗФмСІЕФЬсИпЃЌбЛЗНсЙЙПЩвддкгВМўжаЪЕЯжЁЃДЫЭтЃЌЕБИУЯюЙІФмгУШэМўЪЕЯжЪБЃЌЯрЙиЕФПЊЯњПЩМѕаЁЕНЪЕЪБДІРэдЄЫуЁЃСуПЊЯњбЛЗдЪаэГЬађдБЭЈЙ§ЩшжУМЦЪ§жЕВЂЧвЖЈвхбЛЗБпНчГѕЪМЛЏбЛЗЁЃДІРэЦїНЋМЬајжДаабЛЗжБЕНМЦЪ§НсЪјЁЃ ЁЁЁЁ СуПЊЯњбЛЗЪЧДѓЖрЪ§ДІРэЦїБиВЛПЩЩйЕФвЛВПЗжЃЌЕЋЁАгВМўбЛЗЛКГхЦїЁБЪЕМЪЩЯПЩвдЬсИпбЛЗНсЙЙЕФадФмЁЃЫќУЧгУзїбЛЗжаЫљжДаажИСюЕФвЛжжИпЫйЛКГхДцДЂЦїЁЃР§ШчЃЌдкЕквЛДЮжДааЭъвЛИібЛЗжЎКѓЃЌПЩНЋИУжИСюБЃДцдкбЛЗЛКГхЦїжаЃЌДгЖјЮоаыдкУПвЛДЮбЛЗЖМЗДИДжиШЁЯрЭЌжИСюЁЃЭЈЙ§НЋбЛЗжИСюБЃДцдкФмЙЛдкЕЅжмЦкФкЗУЮЪЕФЛКГхЦїжаЃЌФмЙЛНкЪЁДѓСПЕФжмЦкЪ§ЁЃИУЬиадВЛашвЊГЬађдБНјааЖюЭтЕФЩшжУЃЌЕЋЪЧашвЊжЊЕРбЛЗЛКГхЦїЕФГпДчвдКЯРэЕибЁдёбЛЗДѓаЁЁЃ ИпЫйЛКГхДцДЂЦї ЁЁЁЁ ЭЈГЃЕфаЭЕФDSPОпгаЩйСПЕФПьЫйЁЂФкжУДцДЂЦїЁЃMCUЭЈГЃПЩвдЗУЮЪДѓСПЕФЭтВПДцДЂЦїЁЃЗжВуДцДЂЦїЬхЯЕНсЙЙНЋетСНжжЗНАИЕФгХЕуНсКЯдквЛЦ№ЃЌДгЖјПЩЬсЙЉМИжжЕШМЖОпгаВЛЭЌадФмЕФДцДЂЦїЁЃЖдгкашвЊзюИпадФмгІгУЃЌПЩвддкЕЅИіКЫаФЪБжгжмЦкФкЗУЮЪФкжУSRAMЁЃЖдгкОпгаДѓДњТыГпДчЕФЯЕЭГЃЌПЩЬсЙЉДѓСПЁЂНЯГЄЕШД§бгГйЕФЦЌФкКЭЦЌЭтДцДЂЦїЁЃ ЁЁЁЁ етжжЗжВуДцДЂЦїЬхЯЕНсЙЙБОЩэНіНіЪЧЗЂЛгвЛЖЈЕФзїгУЃЌгЩгкЯждкЕФИпадФмДІРэЦїГЃГЃдЫаадкНЯЕЭЕФЪБжгЦЕТЪЯТЃЌвђДЫДѓЕФгІгУГЬађжЛФмзАдкНЯТ§ЕФЭтВПДцДЂЦїжаЁЃДЫЭтЃЌГЬађдББЛЦШЪжЖЏНЋЙиМќДњТывЦШыКЭвЦГіФкВПSRAMЁЃЕЋЪЧЃЌЭЈЙ§НЋЪ§ОнКЭжИСюИпЫйЛКГхДцДЂЦїМгЕНИУЬхЯЕНсЙЙжаКѓЃЌЭтВПДцДЂЦїИќвзгкЙмРэЃЌИпЫйЛКГхДцДЂЦїПЩвдМѕЩйНЋжИСюКЭЪ§ОнвЦШыДІРэЦїФкКЫЕФЪжЙЄВйзїЁЃгЩгкВЛашвЊПМТЧНјШыФкКЫЕФЪ§ОнКЭжИСюСїЙмРэЃЌПЩвдДѓДѓМђЛЏБрГЬФЃЪНЁЃ ЁЁЁЁ жИСюИпЫйЛКДцЭЈГЃВЩгУСЫФГжжРраЭЕФзюНќзюЩйЪЙгУ(LRU)ЫуЗЈЃЌДгЖјШЗБЃИќГЃгУЕФжИСюДњЬцНЯЩйЪЙгУЕФжИСюЁЃНЋвЛаЉФкжУЪ§ОнДцДЂЦїХфжУЮЊИпЫйЛКДцКЭВПЗжSRAMЕФФмСІПЩвдгХЛЏадФмЁЃжБНгДцДЂЦїЗУЮЪ(DMA)ПижЦЦїФмЙЛжБНгПижЦФкКЫЃЌЭЌЪБЕБашвЊБэжаЪ§ОнЪБНЋЦфЖСШыЪ§ОнИпЫйЛКДцЁЃвЛЕЉИпЫйЛКДцдЪаэВЂЧвDMAПижЦЦїХфжУЭъБЯЃЌдђГЬађдБМДПЩМЏжаОЋСІгкФкКЫЫуЗЈЕФПЊЗЂЁЃ УПжмЦкЖрДЮВйзї ЁЁЁЁ ЭЈГЃвдУПУыжДааЖрЩйАйЭђЬѕжИСю(MIPS)РДКтСПДІРэЦїЁЃдјОБЛБЃСєгУдкИпГЩБОВЂааДІРэЦїжаЕФЖрЗЂВМжИСюФПЧАвВПЩгУдкЕЭГЩБОЁЂЖЈЕуДІРэЦїжаЁЃГ§СЫдкУПИіКЫаФДІРэЦїжмЦкФкЭъГЩЖрЬѕALUЛђMACВйзїЭтЃЌдкЯрЭЌжмЦкФкЛЙПЩЭъГЩЖюЭтЕФЪ§ОнДІРэКЭЪ§ОнДцДЂЁЃДцДЂЦїЭЈГЃЛЎЗжЮЊзгШєИЩИіДцДЂЦїзщЃЌетаЉДцДЂЦїзщПЩвдБЛФкКЫЫЋЯђЗУЮЪВЂЧвБЛDMAПижЦЦїЫцЛњЗУЮЪЁЃМјгкЩЯЪіЕФЛљгкгВМўЕФбАжЗЫуЗЈЕФЗжНтЗНЗЈЃЌКмУїЯдЦфПЩвддкЕЅИіжмЦкФкЭъГЩаэЖрВйзїЁЃ ЁЁЁЁ ЭМ3ЪОГіЖрВйзїжИСюЕФвЛИіЪЕР§ЁЃШчЭМ3ЫљЪОЃЌдквЛИіжмЦкФкГ§СЫЭъГЩСНЬѕЖРСЂЕФMACВйзїЭтЃЌдкЯрЭЌЕФДІРэЦїЪБжгжмЦкФкЛЙЭъГЩСЫЪ§ОнЖСШЁКЭЪ§ОнДцДЂЁЃ 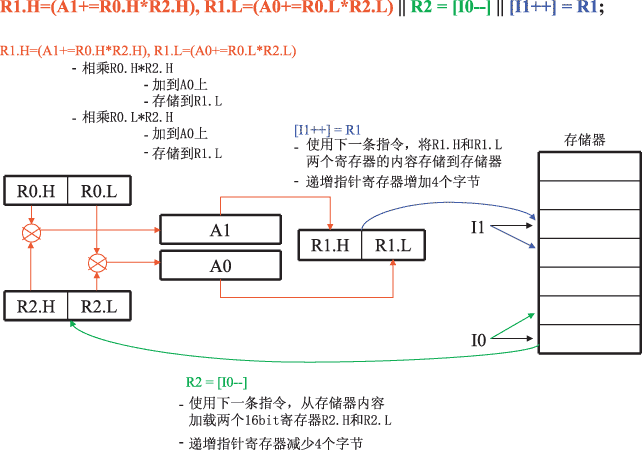 ЭМ3 BlackfinЖрЗЂВМжИСюдкЕЅжмЦкФкЭъГЩМИДЮВйзї ЛЅЫјСїЫЎЯп ЁЁЁЁ ЫцзХДІРэЦїЫйЖШЕФдіМгЃЌДгећИіЕчТЗМЖРДПДДІРэСїЫЎЯпБиЖЈЛсБфЕУИќЩюЁЃШЛЖјЃЌгааЉДІРэЦїОпгаЁАЛЅЫјЁБСїЫЎЯпЁЃетвтЮЖзХЕБЭъГЩЛуБргябдБрГЬЪБЃЌГЬађдБВЛБиЪжЖЏЕїЖШЛђИњзйЭЈЙ§СїЫЎЯпЕФЪ§ОнКЭжИСюЁЃДІРэЦїЛсздЖЏДІРэетаЉЪБађЕФЪТЧщЁЃ СщЛюЕФЪ§ОнМФДцЦїЮФЕЕ ЁЁЁЁ зюКѓЃЌСэЭтвЛИіВЙГфЬиадЪЧЭЈгУЪ§ОнМФДцЦїМЏЁЃдкДЋЭГЕФЖЈЕуDSPжаЃЌзжГЄЭЈГЃЪЧЙЬЖЈЕФЁЃШЛЖјЃЌОпгаФмЙЛгУзївЛИі32bit(Р§ШчR0)ЛђСНИі16bit(Р§ШчЗжБ№гУгкЕЭ8bitКЭИп8bitЕФR0.LКЭR0.H)ЕФЪ§ОнМФДцЦїЪЧЗЧГЃгаРћЕФЁЃдкЫЋMACЯЕЭГжаЃЌетдЪаэдкЕЅжмЦкФкВйзїЫФИі16bitЕФЪ§ОнЁЃ ФкЛ§ ЁЁЁЁ ФкЛ§ЛђепБъСПЛ§дкЖШСПСНИіЯђСПЕФе§НЛадЪБЪЧКмгааЇЕФВйзїЁЃДѓЖрЪ§CгябдГЬађдБгІИУЪьЯЄвдЯТЕФФкЛ§ВйзїЃКЁЁЁЁshort dot(short a[], short b[], int size) { ЁЁЁЁ int i; ЁЁЁЁ int output = 0; ЁЁЁЁ for(i=0; i ЁЁЁЁreturn output; ЁЁЁЁ ЯТУцЪЧBlackfinДІРэЦїЛуБрДњТыЕФжївЊВПЗжЃК ЁЁЁЁ//P0=loop count, I0 & P1 are address registers ЁЁЁЁA1 = A0 = 0; // A0 & A1 are accumulators ЁЁЁЁLSETUP (loop1,loop1) LC0 = P0 ;// Setup hardware loop starting at label loop1: ЁЁЁЁloop1: A1 +=R1.H*R0.H, A0+=R1.L*R0.L||R1=[P1++]||R0=[I0++]; ЯТУцМИЕуЫЕУїСЫМђЛЏетжжНєДеБрТыЕФDSPЬхЯЕНсЙЙЬиадЁЃ ЁЁЁЁ гВМўбЛЗЛКГхЦїКЭбЛЗМЦЪ§ЦїдкУПДЮЕќДњЕФФЉЖЫВЛашвЊЬјзЊжИСюЁЃгЩгкФкЛ§ЪЧГЫЛ§змКЭЃЌвђДЫПЩдквЛДЮбЛЗжаЭъГЩЁЃИУЛуБрГЬађЫљЪОЪЧLSETUPжИСюЃЌЫќЪЧжДаабЛЗЫљашЕФЮЈвЛжИСюЁЃ ЁЁЁЁ ЖрЗЂВМжИСюдЪаэдкЯрЭЌЕФжмЦкФкжДааЖрЬѕжИСюКЭСНДЮЪ§ОнЗУЮЪЁЃдкУПвЛДЮЕќДњЪБЃЌБиаыЯШЖСШЁaКЭbжЕЃЌШЛКѓЯрГЫЃЌзюКѓаДЛиЕНПЩБфЪфГіЕФдЫаазмКЭжаЁЃдкаэЖрMCUЦНЬЈЩЯЃЌетЪЕМЪЩЯЕШгкЫФЬѕжИСюЁЃЛуБрДњТыЕФзюКѓвЛааЪОГідквЛИіжмЦкФкПЩжДааЕФЫљгаВйзїЁЃ ЁЁЁЁ ВЂааALUВйзїдЪаэЭЌЪБжДааСНЬѕ16bitжИСюЁЃЛуБрДњТыЪОГідкУПДЮЕќДњжаЪЙгУЕФСНИіРлМгЦїЕЅдЊ(A0КЭA1)ЃЌетНЋЕќДњДЮЪ§МѕЩйСЫ50%ЃЌДгЖјНЋдРДЕФжДааЪБМфМѕЩйСЫвЛАыЁЃ FIRЫуЗЈ ЁЁЁЁ гаЯоТіГхЯьгІ(FIR)ТЫВЈЦїЪЧвЛжжЕШМлгкОэЛ§ВйзїКмГЃМћЕФТЫВЈЦїНсЙЙЁЃAЭЈЙ§CВйзїПДЦ№РДЗЧГЃРрЫЦгкФкЛ§ЁЃ ЁЁЁЁ//НЋаХКХШЁбљЕНбЛЗЛКГхЦїжа ЁЁЁЁx[cur] = sampling_function(); ЁЁЁЁcur = (cur+1)%TAPS; // дкбЛЗжадіМгcurжИеы ЁЁЁЁ//ЭъГЩГЫМг ЁЁЁЁy = 0; ЁЁЁЁfor (k=0; k ЁЁЁЁ ЪЙгУЛуБргябдБраДЕФFIRФкКЫИёЪНгааЉРрЫЦгкФкЛ§ЁЃдкетИіЬиЖЈЕФР§згжаЃЌШЁбљжЕДцДЂдкR0МФДцЦїжаЃЌЭЌЪБЯЕЪ§ДцДЂдкR1МФДцЦїжаЁЃ ЁЁЁЁ// P0 ДцгаТЫВЈЦїГщЭЗ ЁЁЁЁR0=[I0++] || R1=[I1++]; // ЩшжУR0КЭR1ЕФГѕЪМжЕ ЁЁЁЁA1=A0=0; // НЋРлМгЦїжУСу ЁЁЁЁLSETUP (loop1, loop1) LC0 = P0;//ЩшжУФкВПбЛЗ ЁЁЁЁloop1: A1+=R0.L*R1.L, A0+=R0.H*R1.H||R0=[I0++]||R1=[I1++]; //МЦЫу ЁЁЁЁ Г§СЫОпгаЫљУшЪіЕФгУгкФкЛ§ЕФЬиадЭтЃЌЩЯУцЫљЪОЕФFIRЫуЗЈвВПЩЪЙгУбЛЗЛКГхЁЃ бЛЗЛКГхЦїВЛашвЊжБНгШЁгрдЫЫуЁЃдкCДњТыЦЌЖЮжаЃЌ%(ШЁгр)дЫЫуЗћПЩЬсЙЉвЛжжгУгкбЛЗЛКГхЕФЛњРэЁЃе§ШчЛуБрФкКЫжаЫљЪОЃЌетаЉШЁгрдЫЫуЗћВЛФмБЛБрвыЮЊФкбЛЗжаЕФЦфЫћжИСюЁЃЯрЗДЃЌЪ§ОнЕижЗЗЂЩњЦїМФДцЦїI0КЭI1ПЩдкЭтбЛЗжаХфжУЃЌвдБудкбЛЗЕНДяЯЕЪ§ЛКГхЦїБпНчЪБФмЙЛздЖЏЗЕЛиЦ№ЪМДІЁЃ FFTЫуЗЈ ЁЁЁЁ ПьЫйИЕСЂвЖБфЛЛ(FFT)ЪЧаэЖраХКХДІРэЫуЗЈВЛПЩШБЩйЕФвЛВПЗжЃЌЦфЬиЕужЎвЛЪЧЪфШыЯђСПАДееСЌајЪБМфЫГађХХСаЃЌЕЋЪфГіАДБШЬиЗзЊЫГађХХСаЁЃДѓЖрЪ§ДЋЭГЕФЭЈгУДІРэЦївЊЧѓГЬађдБгУЕЅЖРЕФГЬађећРэБШЬиЗзЊЪфГіЁЃдкDSPЦНЬЈЩЯЃЌБШЬиЗзЊПЩгУгкбАжЗв§ЧцЁЃ ЁЁЁЁ БШЬиЗзЊбАжЗдкЪЕЯжFFTЪБВЛашвЊЕЅЖРЕФБШЬиЗзЊГЬађЃЌдЪаэгВМўздЖЏНЋFFTЫуЗЈЕФЪфГіНјааБШЬиЗзЊЃЌЮоаыГЬађдББраДЖюЭтЕФГЬађЃЌДгЖјИФНјСЫадФмЁЃ ЁЁЁЁ Г§СЫЩЯУцЫљЬсЕНЕФжИСюЭтЃЌгааЉДІРэЦївВАќРЈЖюЭтвЛЬззЈгУжИСювджЇГжЖржжгІгУЁЃЬсЙЉетаЉжИСюЕФФПЕФОЭЪЧНјвЛВНЬсИпЖдЫуЗЈЕФДІРэФмСІЃЌР§ШчЮЌЬиБШЫуЗЈЁЂHuffmanБрТывдМАаэЖрЦфЫћБШЬиВйзїГЬађЁЃ |
ЭјгбЦРТл